TreeVGR-SFT-35K
收藏Hugging Face2025-07-15 更新2025-07-16 收录
下载链接:
https://huggingface.co/datasets/HaochenWang/TreeVGR-SFT-35K
下载链接
链接失效反馈官方服务:
资源简介:
TreeBench是一个用于全面评估模型'带着图像思考'能力的诊断基准数据集,它通过动态引用视觉区域进行评估。该数据集基于三个核心原则:1. 对复杂场景中微妙目标的聚焦视觉感知;2. 通过边界框评估的跟踪证据;3. 测试对象交互和空间层次的二次推理。TreeBench包含405个具有挑战性的视觉问答对,由八位LMM专家精心标注,图像来源于SA-1B,优先选择物体密集的图像。
TreeBench is a diagnostic benchmark dataset designed for comprehensively evaluating the "image-grounded thinking" capability of models, which conducts evaluations by dynamically referencing visual regions. This dataset is based on three core principles: 1. Focused visual perception of subtle targets in complex scenes; 2. Evaluation of tracking evidence via bounding boxes; 3. Secondary reasoning for testing object interactions and spatial hierarchies. TreeBench contains 405 challenging visual question-answer pairs, meticulously annotated by eight LMM experts, with images sourced from SA-1B, prioritizing object-dense images.
创建时间:
2025-07-01
原始信息汇总
TreeBench: Traceable Evidence Enhanced Visual Grounded Reasoning Benchmark
数据集概述
- 名称: TreeBench
- 用途: 诊断性基准数据集,用于评估"基于图像的思考"能力
- 核心原则:
- 复杂场景中细微目标的聚焦视觉感知
- 通过边界框评估实现可追溯证据
- 超越简单对象定位的二阶推理能力测试
数据集详情
- 语言: 英语 (en)
- 许可证: Apache-2.0
- 任务类别: 图像文本到文本 (image-text-to-text)
- 标签: VQA, 视觉定位, 推理, 基准测试, 多模态
- 数据规模: 405个具有挑战性的视觉问答对
- 标注: 由8位LMM专家精心标注
- 图像来源: 初始采样自SA-1B数据集,优先选择具有密集对象的图像
相关资源
- GitHub仓库: https://github.com/Haochen-Wang409/TreeVGR
- 图像数据集: https://huggingface.co/datasets/lmms-lab/LLaVA-NeXT-Data
- 关联模型:
- TreeVGR-7B: https://huggingface.co/HaochenWang/TreeVGR-7B
- TreeVGR-7B-CI: https://huggingface.co/HaochenWang/TreeVGR-7B-CI
- 训练数据集:
- TreeVGR-RL-37K: https://huggingface.co/datasets/HaochenWang/TreeVGR-RL-37K
- TreeVGR-SFT-35K: https://huggingface.co/datasets/HaochenWang/TreeVGR-SFT-35K
引用
bibtex @article{wang2025traceable, title={Traceable Evidence Enhanced Visual Grounded Reasoning: Evaluation and Methodology}, author={Haochen Wang and Xiangtai Li and Zilong Huang and Anran Wang and Jiacong Wang and Tao Zhang and Jiani Zheng and Sule Bai and Zijian Kang and Jiashi Feng and Zhuochen Wang and Zhaoxiang Zhang}, journal={arXiv preprint arXiv:2507.07999}, year={2025} }
搜集汇总
数据集介绍
构建方式
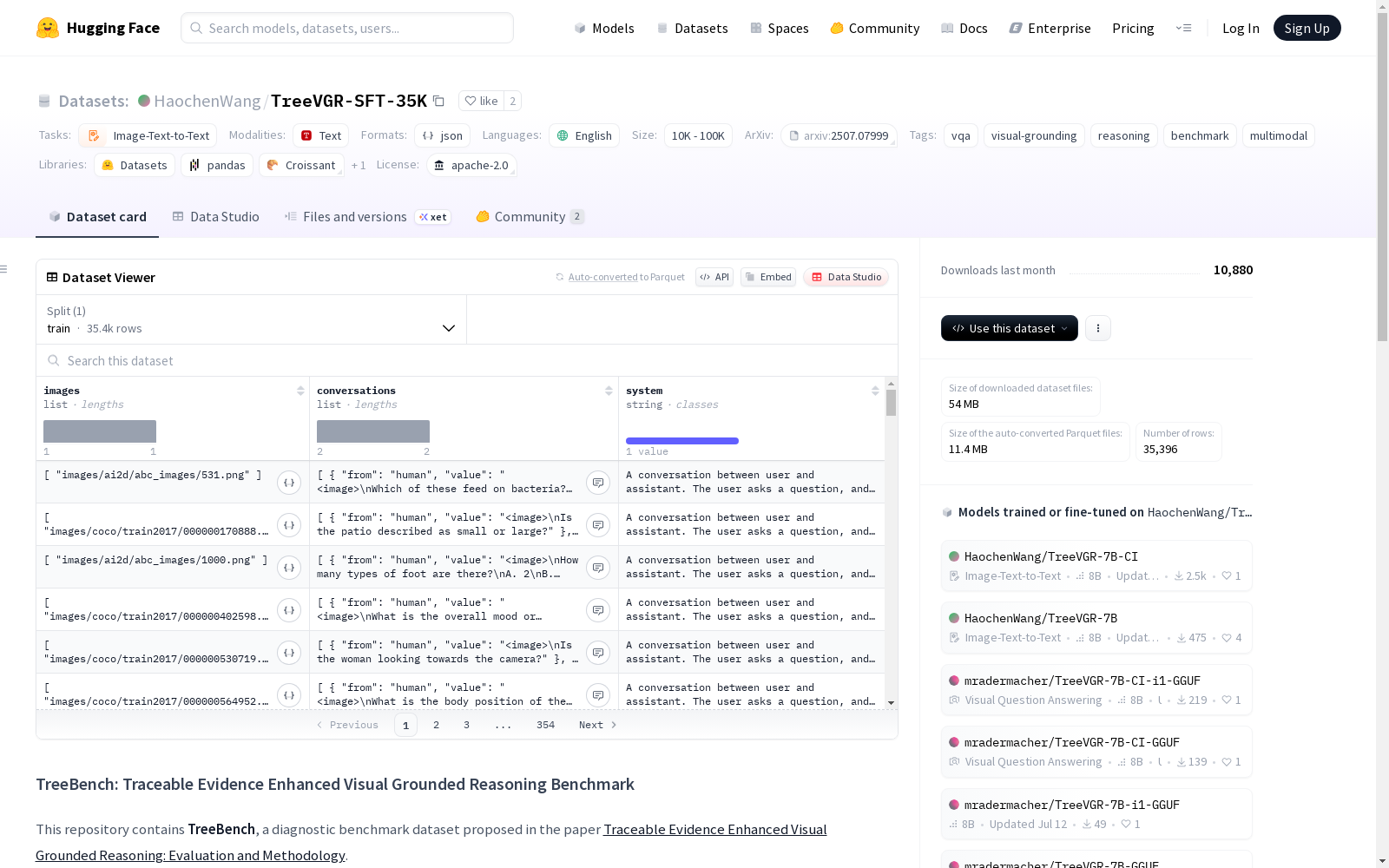
在视觉推理领域,TreeVGR-SFT-35K数据集的构建体现了严谨的科学方法论。该数据集基于SA-1B图像库进行初始采样,特别筛选包含密集对象的复杂场景图像,确保视觉感知任务的挑战性。通过八位大型多模态模型专家团队的精细标注,形成了35,000个高质量的监督微调样本,每个样本都包含图像-文本对及其对应的边界框标注,为模型训练提供了可靠的视觉 grounding 基础。
使用方法
在多模态模型训练实践中,该数据集主要用于视觉 grounded 推理任务的监督微调阶段。研究人员可通过Hugging Face平台直接加载数据集,将其与基础视觉语言模型结合进行端到端训练。使用时应遵循原论文推荐的训练范式,注意保持图像-文本-边界框三元组的数据完整性,训练完成后可通过TreeBench基准测试集系统评估模型的视觉推理能力,具体实现细节可参考项目GitHub仓库提供的示例代码。
背景与挑战
背景概述
视觉推理领域近年来在人工智能研究中占据重要地位,TreeBench作为2025年由Haochen Wang等研究人员提出的诊断性基准数据集,专注于可追溯证据增强的视觉接地推理能力评估。该数据集基于SA-1B图像源构建,通过八位大型多模态模型专家精心标注的405个视觉问答对,致力于解决复杂场景中细微目标的感知、空间层次推理以及对象交互分析等核心研究问题,为多模态推理模型的发展提供了重要的评估基准。
当前挑战
该数据集主要应对视觉接地推理中高阶认知能力的挑战,包括复杂场景下细微目标的精准定位、多对象空间关系的层次化推理,以及可追溯视觉证据的量化评估。在构建过程中面临密集对象场景的样本筛选、专家一致性标注的质量控制,以及边界框标注与自然语言推理的协同验证等多重技术难题,这些挑战共同推动了视觉推理领域评估范式的革新。
常用场景
经典使用场景
在视觉语言模型评估领域,TreeVGR-SFT-35K数据集作为TreeBench基准的核心组成部分,专门用于测试模型在复杂场景中的视觉推理能力。该数据集通过精心设计的视觉问答对,要求模型在包含密集对象的图像中定位细微目标并进行多步推理,典型应用包括评估模型对物体交互关系和空间层次结构的理解能力,为视觉 grounded reasoning 研究提供标准化测试平台。
解决学术问题
该数据集有效解决了多模态推理中视觉证据追溯性不足的学术难题。通过引入边界框标注和二阶推理机制,它使研究者能够精确追踪模型决策过程中的视觉依据,弥补了传统视觉问答数据集在可解释性方面的缺陷。这种设计显著提升了视觉推理研究的透明度和可靠性,为构建可信赖的多模态人工智能系统奠定了重要基础。
实际应用
在实际应用层面,该数据集支撑的视觉 grounded reasoning 技术可广泛应用于智能医疗影像分析、自动驾驶环境感知和工业质检系统。通过提升模型在复杂场景中的细粒度目标识别和关系推理能力,这些系统能够更准确地理解视觉内容并做出可靠决策,例如在医疗诊断中辅助医生定位病灶区域,或在自动驾驶中精确识别道路危险因素。
数据集最近研究
最新研究方向
在视觉语言多模态研究领域,TreeBench数据集正推动着可追溯视觉推理范式的革新。该数据集通过引入动态视觉区域引用机制和边界框评估体系,为复杂场景下的细粒度感知与二阶推理建立了新的评估标准。当前研究热点集中于解决模型在密集对象交互和空间层级推理中的局限性,相关突破将直接影响自动驾驶、医疗影像分析等需要精确视觉定位的垂直领域。该基准通过融合可验证的证据链,为构建透明可信的多模态人工智能系统提供了重要方法论支撑。
以上内容由遇见数据集搜集并总结生成


