Soofi-Think-SFT-10B-multilingual
收藏Hugging Face2026-03-27 更新2026-03-28 收录
下载链接:
https://huggingface.co/datasets/toroe/Soofi-Think-SFT-10B-multilingual
下载链接
链接失效反馈官方服务:
资源简介:
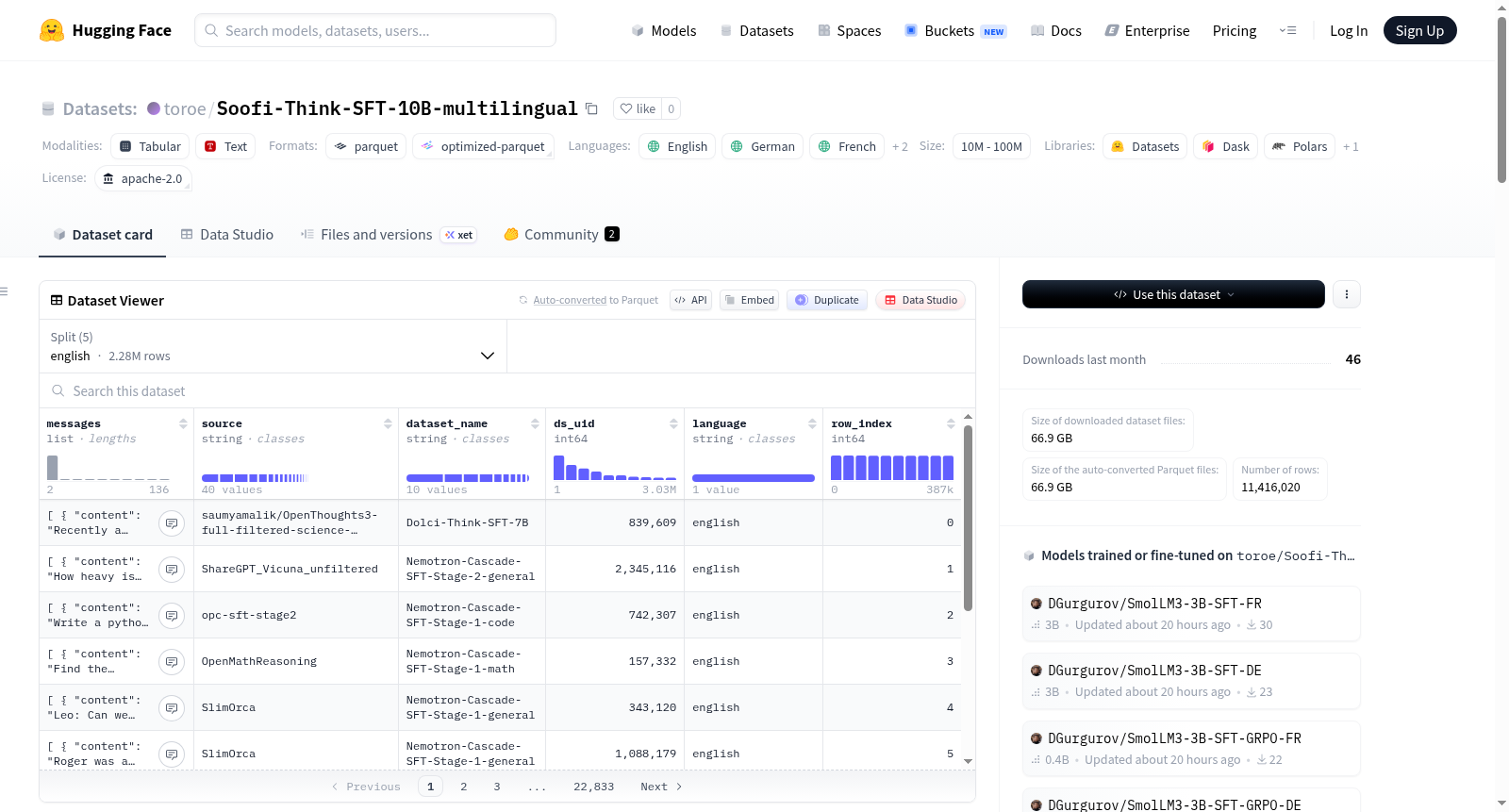
ReasonXL是一个大规模多语言推理语料库,涵盖5种语言(英语、德语、法语、西班牙语、意大利语),总计约440亿token。该数据集旨在支持带有跨领域思维链的多语言推理模型的监督微调。
数据内容包含从10个现有推理数据集中筛选的英语样本,经过质量标注后使用Qwen3-32B模型翻译成其他四种欧洲语言。每个样本包含三个独立翻译的组件:用户输入、思维链(用<think>标签标记)和最终输出。翻译过程严格保留技术术语、数学符号和推理结构。
数据集包含2,282,204个样本,平均每个英语样本总长度4,023 token(输入424 token,输出3,599 token)。特征字段包括消息内容(content)、角色(role)、数据来源(source)、数据集名称(dataset_name)等。数据来源于6个现有推理数据集,包括Cascade-SFT、Dolci-Think等。
该数据集采用Apache-2.0许可证,适用于多语言推理模型训练、思维链研究等场景。
ReasonXL is a large-scale multilingual reasoning corpus covering five languages: English, German, French, Spanish, and Italian, with a total of approximately 44 billion tokens. This corpus is intended to support supervised fine-tuning of multilingual reasoning models with cross-domain chain-of-thought capabilities.
The dataset comprises English samples filtered from 10 existing reasoning datasets, which are subsequently translated into the other four European languages using the Qwen3-32B model following quality annotation. Each sample includes three independently translated components: user input, chain-of-thought (marked with the <think> tag), and final output. The translation process strictly retains technical terms, mathematical symbols, and reasoning structures.
The dataset contains 2,282,204 samples, with an average total length of 4,023 tokens per English sample (424 tokens for input and 3,599 tokens for output). Its feature fields include message content (content), role (role), data source (source), dataset name (dataset_name), and other relevant fields. It is derived from 6 existing reasoning datasets, including Cascade-SFT, Dolci-Think, and others.
This dataset is licensed under Apache-2.0, and is suitable for applications such as multilingual reasoning model training and chain-of-thought research.
创建时间:
2026-03-13
搜集汇总
数据集介绍
构建方式
在构建多语言推理数据集的过程中,Reason<sub>XL</sub>采用了系统化的数据生成流程。其核心方法是从十个现有的英语推理数据集中筛选源样本,通过专用模型进行质量标注与过滤,确保样本在安全性、信息密度及教育价值等十八个维度上符合高标准。随后,利用先进的大语言模型将每个样本的用户输入、推理轨迹及最终输出独立翻译为德语、法语、西班牙语和意大利语,翻译过程严格遵循技术术语与数学符号的保留原则,并辅以语言特定的正式性指导,从而构建出一个跨语言、跨领域的大规模监督微调语料库。
特点
该数据集显著特点在于其大规模多语言覆盖与高质量的推理轨迹标注。它囊括了英语、德语、法语、西班牙语和意大利语五种语言,总计约四百四十亿标记,每个语言版本均包含超过两百万个样本。数据集样本结构清晰,包含完整的对话消息序列,并保留了原始的领域标签与质量标注。其独特之处在于所有非英语样本均源自高质量的英语源数据翻译,确保了跨语言间在技术术语、推理逻辑和格式上的一致性,同时通过严谨的过滤流程实现了领域平衡与内容完整性。
使用方法
该数据集主要用于支持大语言模型在多语言环境下的推理能力监督微调。研究人员可直接加载特定语言的分支数据,利用其包含的带有明确角色标识的消息序列进行训练。每条数据中的推理轨迹被封装于特定标签内,为模型学习链式思维提供了清晰的监督信号。使用者可根据`dataset_name`和`source`字段筛选特定领域或来源的数据,以进行针对性训练或评估。该资源设计为持续更新的活体语料库,未来版本将扩展数据规模,为多语言推理研究提供长期支持。
背景与挑战
背景概述
随着大型语言模型在复杂推理任务上的需求日益增长,多语言、跨领域的推理数据成为关键资源。Reason<sub>XL</sub>数据集由Daniil Gurgurov与Tom Röhr于2026年发布,旨在构建一个大规模多语言推理语料库,涵盖英语、德语、法语、西班牙语和意大利语五种语言,总计约440亿令牌。该数据集的核心研究问题在于如何通过高质量的多语言监督微调数据,提升模型在科学、数学、编程等专业领域的链式推理能力。其从十个现有推理数据集中筛选并标注英文样本,再利用先进模型进行精准翻译,确保了技术术语与推理结构的跨语言一致性,为多语言推理模型的训练与评估提供了重要基准。
当前挑战
该数据集致力于解决多语言跨领域推理任务中的核心挑战,即如何使模型在不同语言和文化背景下保持严谨的逻辑链条与专业术语的一致性。构建过程中的主要挑战包括:确保技术内容(如数学符号、代码片段)在翻译过程中的无损传递,这要求翻译模型严格遵循格式与术语规范;维持各语言版本在风格与正式程度上的适应性,例如德语需使用正式敬语,而西班牙语需保持中性国际风格;此外,原始英文数据的质量筛选与多阶段标注流程也涉及复杂的完整性约束与领域平衡策略,以避免数据偏差并保障教育价值与信息密度。
常用场景
经典使用场景
在多语言人工智能领域,Soofi-Think-SFT-10B-multilingual数据集为研究者提供了跨语言推理任务的标准化训练资源。该数据集通过整合英语、德语、法语、西班牙语和意大利语五种语言的链式思维标注数据,支持模型在数学、科学、编程等多个技术领域进行监督式微调。其核心价值在于保留了原始技术术语和推理结构的同时,实现了高质量的多语言对齐,使得模型能够在不同语言环境下展现出连贯且准确的推理能力。
实际应用
在实际部署中,该数据集能够赋能多语言教育辅助系统、跨语言技术文档分析工具以及全球化智能客服平台。例如,在教育场景下,系统可根据学生使用的语言提供个性化的数学或科学问题分步解答;在企业环境中,它能协助工程师跨越语言障碍理解技术文档中的复杂逻辑。这些应用显著提升了多语言环境下知识服务的可及性与准确性。
衍生相关工作
基于该数据集衍生的经典工作主要集中在多语言思维链蒸馏、跨语言推理模型架构优化以及低资源语言能力增强等领域。例如,研究者利用其对齐的多语言推理轨迹,开发了能够将高资源语言推理能力有效迁移至低资源语言的模型微调策略;亦有工作借鉴其数据构建方法论,扩展至更多语言对或垂直领域,推动了多语言推理技术生态的持续演进与完善。
以上内容由遇见数据集搜集并总结生成


