TripUNLamb
收藏Hugging Face2025-09-12 更新2025-09-13 收录
下载链接:
https://huggingface.co/datasets/SwetieePawsss/TripUNLamb
下载链接
链接失效反馈官方服务:
资源简介:
这是一个用于评估模型在问答和知识保留方面的性能的数据集。它包含了问题、答案、主题、关系和对象等信息,以及多个模型的性能指标,如生成文本的准确性、BERT相似度等。数据集分为多个子集,每个子集代表不同的数据采样策略或保留策略。
This is a dataset intended to evaluate model performance in question answering and knowledge retention. It contains information such as questions, answers, topics, relationships and entities, as well as performance metrics of multiple models, including the accuracy of generated text, BERT similarity, and so on. The dataset is divided into multiple subsets, each representing a distinct data sampling strategy or retention strategy.
创建时间:
2025-09-10
原始信息汇总
TripUNLamb 数据集概述
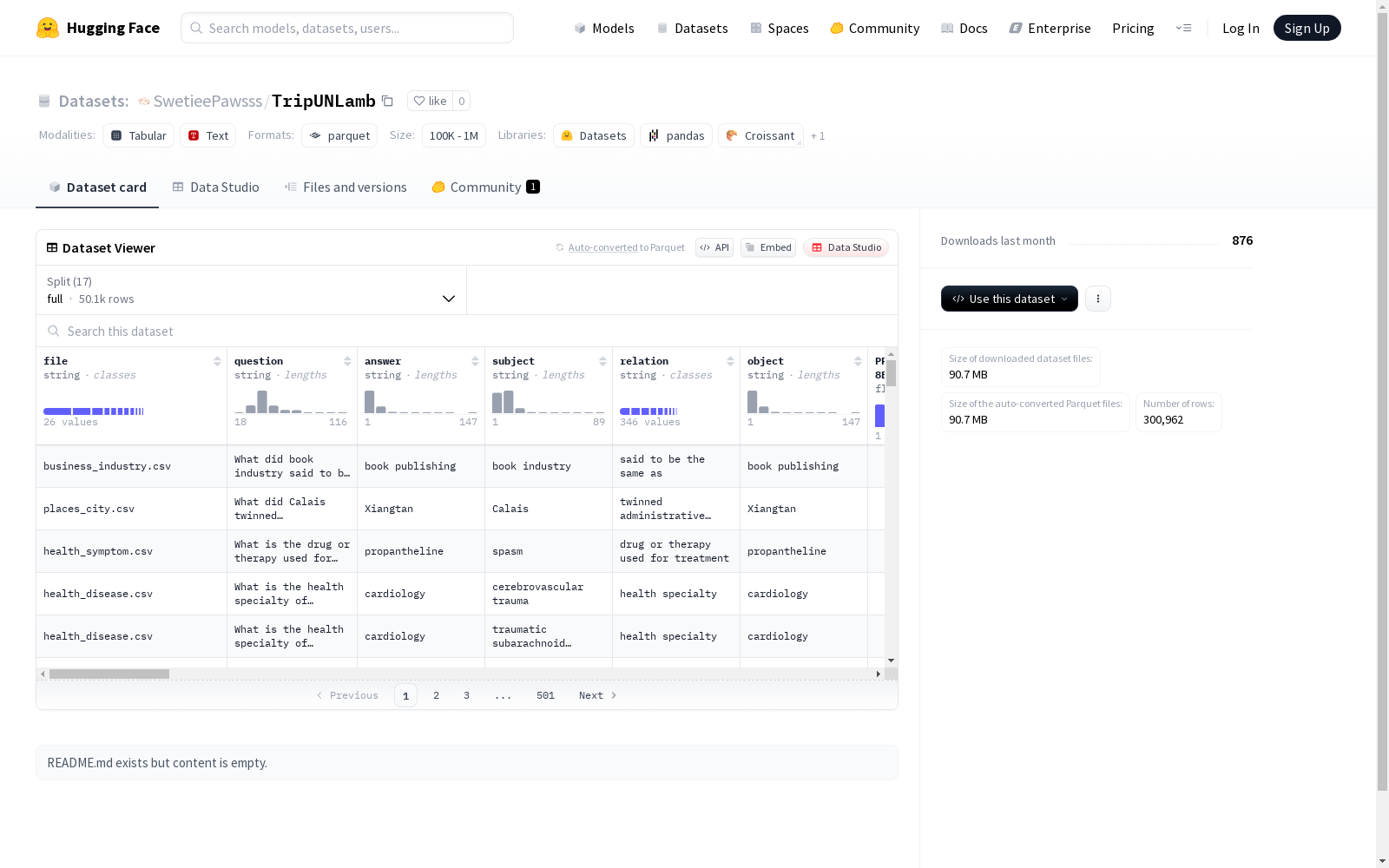
数据集基本信息
- 数据集名称:TripUNLamb
- 下载大小:90,749,451 字节
- 数据集大小:162,773,479.98015058 字节
- 总样本数:50,077 条
数据结构
数据集包含以下字段:
核心字段
- file:字符串类型
- question:字符串类型
- answer:字符串类型
- subject:字符串类型
- relation:字符串类型
- object:字符串类型
- subject_qid:字符串类型
- object_qid:字符串类型
统计特征字段
- subject_popularity_sitelinks:整型
- object_popularity_sitelinks:整型
- popularity_sitelinks_sum:整型
模型评估指标字段
包含多个大型语言模型的性能评估指标:
- PPL_*(困惑度):浮点型
- best_gen_*(最佳生成):字符串类型
- gen_recall_*(生成召回率):浮点型
- bert_sim_*(BERT相似度):浮点型
评估模型包括:
- Llama3 1-8B Instruct
- Llama3 2-3B Instruct
- Llama3 2-1B Instruct
- Gemma 7B IT
- Zephyr 7B Beta
- Phi3 5 mini Instruct
数据划分
数据集提供多个划分版本:
主要划分
- full:完整数据集,27,083,843 字节,50,077 个样本
- know_intersection:687,687 字节,1,326 个样本
- full_retain:26,125,675 字节,48,251 个样本
遗忘研究划分
- rare_forget_ 系列(1,5,10,15):从 500 到 7,511 个样本不等
- popular_forget_ 系列(1,5,10,15):从 500 到 7,511 个样本不等
- retain_instersection_ 系列(98,90,80,70):从 35,055 到 49,077 个样本不等
快速评估划分
- random_fast_retain:270,481 字节,500 个样本
- fast_retain:270,421.9801505681 字节,500 个样本
搜集汇总
数据集介绍
构建方式
在知识图谱与自然语言处理交叉领域,TripUNLamb数据集通过结构化三元组构建,涵盖主体、关系和客体要素。该数据集整合了来自多源知识库的实体链接与语义关系,并利用大规模语言模型生成问答对,确保数据覆盖广度与逻辑一致性。构建过程中采用自动化流水线处理,辅以人工校验机制,有效平衡了数据规模与质量。
使用方法
研究者可通过加载标准分片数据开展知识追踪实验,利用内置的困惑度指标评估模型性能差异。该数据集支持针对特定实体流行度区间的分析,例如通过稀有实体分片检验模型的长尾知识掌握能力。评估流程可整合生成的参考答案与相似度指标,量化模型在关系推理任务中的表现,为知识图谱补全与语言模型优化提供实证基础。
背景与挑战
背景概述
TripUNLamb数据集诞生于知识图谱与大语言模型融合研究的关键时期,由前沿学术机构为探索结构化知识在自然语言处理中的表征能力而构建。该数据集以三元组(主体-关系-客体)为核心架构,深度融合问答生成任务,旨在推动语言模型对实体关系的深度理解与生成准确性。其设计理念源于对知识驱动型AI系统的迫切需求,通过整合多维度评估指标(如困惑度、召回率与语义相似度),为衡量模型在知识保留与遗忘现象中的表现提供了标准化基准。
当前挑战
该数据集核心挑战在于解决大语言模型在知识密集型任务中的动态知识管理问题,特别是模型对长尾实体与高频实体表征的不均衡性。构建过程中需克服多源知识融合的复杂性,包括三元组到自然语言问句的语义对齐、不同规模模型评估指标的一致性校准,以及流行度差异对知识遗忘模式影响的量化分析。此外,需确保生成答案的语义保真度与事实准确性,同时处理大规模知识三元组与生成文本间的尺度匹配难题。
常用场景
经典使用场景
在知识图谱与自然语言处理交叉领域,TripUNLamb数据集通过结构化三元组与自然语言问答的对应关系,为大型语言模型的知识保留与遗忘机制研究提供基准测试平台。其经典应用体现在评估模型对事实性知识的记忆强度,通过控制不同流行度实体的遗忘比例,系统分析模型在知识提取与生成任务中的稳定性与可靠性。
解决学术问题
该数据集有效解决了大语言模型知识更新过程中的灾难性遗忘问题,为量化分析模型对高频与低频知识的记忆差异提供实证基础。通过设计保留集与遗忘集的对比实验,研究者能够精确评估知识编辑技术对模型内部表征的影响,推动可解释性人工智能在知识维护方向的理论突破。
实际应用
在实际应用中,该数据集支撑了知识密集型系统的性能优化,如智能搜索引擎的答案生成模块和对话系统的事实核查功能。企业可依据其提供的遗忘曲线指标,针对性增强模型对长尾知识的覆盖能力,提升医疗、法律等专业领域问答系统的准确性与时效性。
数据集最近研究
最新研究方向
在知识图谱与语言模型融合领域,TripUNLamb数据集正推动机器遗忘与知识保留机制的前沿探索。该数据集通过结构化三元组与多维度评估指标,为研究不同参数规模语言模型在知识提取与生成任务中的表现差异提供了基准平台。当前研究聚焦于模型对流行知识与稀有知识的差异化处理能力,揭示参数效率与知识覆盖度的平衡机制。相关成果对构建可持续学习系统、缓解模型幻觉现象具有重要参考价值,已成为评估模型知识管理能力的关键工具之一。
以上内容由遇见数据集搜集并总结生成


