reap-calibration-data-v1
收藏Hugging Face2026-04-10 更新2026-04-11 收录
下载链接:
https://huggingface.co/datasets/0xSero/reap-calibration-data-v1
下载链接
链接失效反馈官方服务:
资源简介:
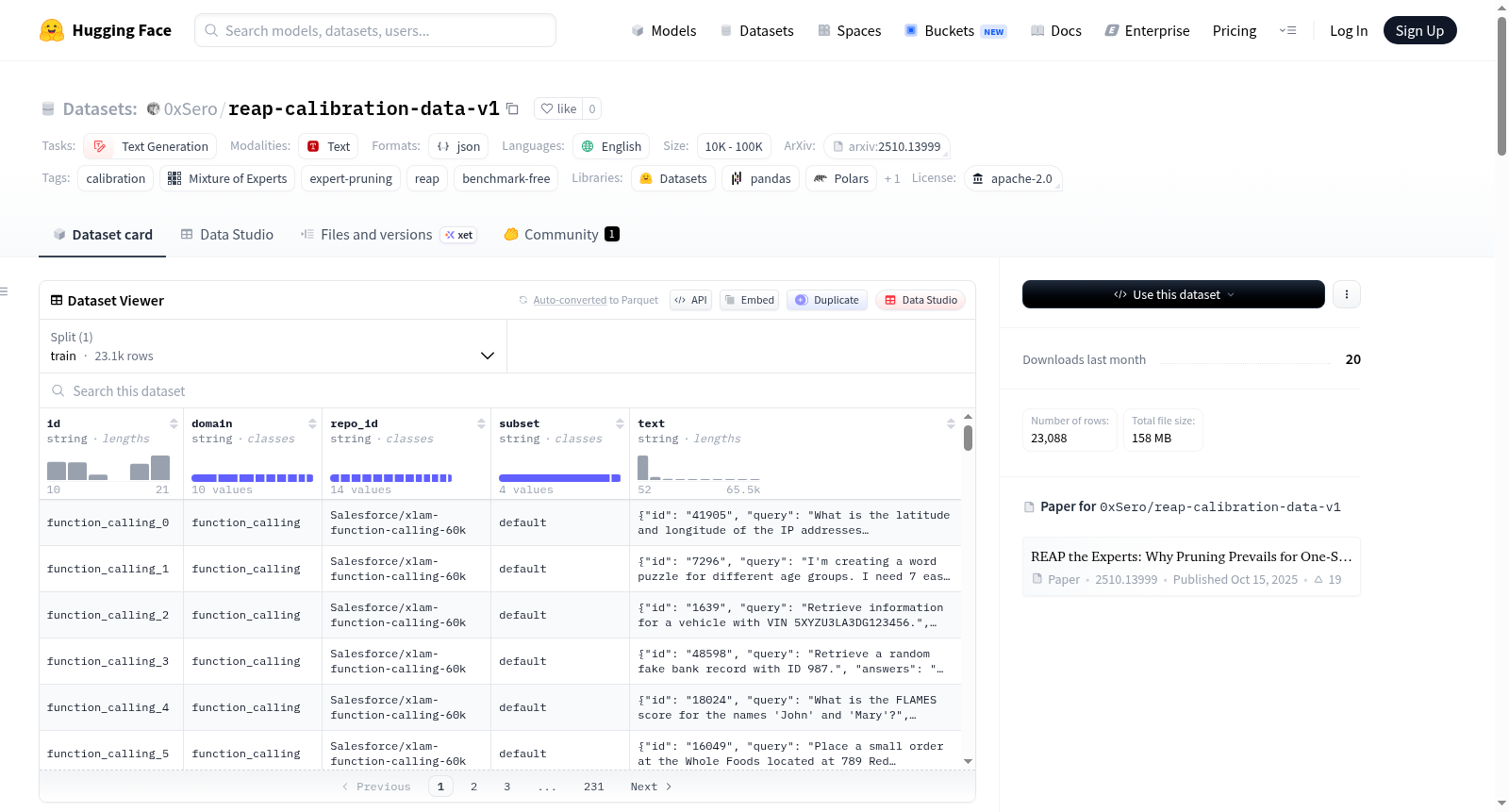
REAP校准数据集v1是一个专为REAP(路由增强激活剪枝)设计的无基准校准数据集,用于混合专家(Mixture-of-Experts)语言模型的剪枝决策。该数据集通过提供多样化的输入,观察专家路由统计信息,从而确定哪些专家可以安全移除。数据集包含23,088个样本,覆盖10个领域,主要集中在编码和工具使用工作负载上。为确保剪枝决策不受基准特定模式的影响,数据集排除了所有常见评估基准。数据集采用JSONL格式,包含id、domain、repo_id、subset和text等字段。适用于≥110B参数的模型时,每个样本作为独立序列处理,最大序列长度为16,384个标记;对于<110B参数的模型,建议将多个样本打包以填充2,048个标记的序列。数据集已用于多个模型的校准,如Qwen3.5-122B-A10B-REAP系列。
REAP Calibration Dataset v1 is a benchmark-free calibration dataset specifically designed for REAP (Route-Augmented Activation Pruning), used for pruning decisions of Mixture-of-Experts (MoE) language models. This dataset provides diverse inputs to observe expert routing statistics, thereby identifying which experts can be safely pruned. The dataset contains 23,088 samples covering 10 domains, with a primary focus on coding and tool-use workloads. To ensure pruning decisions are not biased by benchmark-specific patterns, this dataset excludes all common evaluation benchmarks. The dataset is stored in JSONL format, with fields including id, domain, repo_id, subset, and text. For models with ≥110B parameters, each sample is processed as an independent sequence, with a maximum sequence length of 16,384 tokens; for models with <110B parameters, it is recommended to pack multiple samples to fill sequences of 2,048 tokens. This dataset has been used for calibration of multiple models, such as the Qwen3.5-122B-A10B-REAP series.
创建时间:
2026-04-09
搜集汇总
数据集介绍
构建方式
在混合专家模型优化领域,REAP校准数据集v1的构建遵循了严谨的筛选与整合原则。该数据集并非通过传统训练方式生成,而是专门为观测专家激活模式而精心汇编。其核心构建策略在于从多个公开数据源中选取样本,并严格排除所有常见评估基准的内容,以防止剪枝决策产生偏差。数据集最终汇集了23,088个样本,覆盖函数调用、智能体轨迹、网络安全、通用编程、深度推理、数学、CUDA编程、终端命令、长上下文及科学等十个专业领域,并以JSONL格式组织,每个条目均标注了来源与领域信息。
使用方法
该数据集专用于支持REAP剪枝方法中的校准阶段。使用过程中,模型处于推理模式,数据集被输入模型以记录各层专家的激活统计数据,这些统计信息随后用于识别并安全移除那些激活频率较低的专家。具体操作可通过配套脚本执行,用户需指定数据集路径、最大令牌数、批处理大小等参数。例如,对于大规模模型,建议批处理大小为8,且每个前向传播处理一个独立序列。观测得到的数据将直接指导后续的模型剪枝,旨在以最小的能力损失实现模型参数的显著精简。
背景与挑战
背景概述
在大型语言模型领域,混合专家模型因其卓越的扩展性和效率而备受关注,但随之而来的计算开销与参数冗余问题亦成为研究焦点。REAP校准数据集v1应运而生,专为支持路由增强激活剪枝技术而设计,由Sybil Solutions的研究团队于2025年创建。该数据集旨在为MoE模型提供多样化的推理输入,以观测专家激活模式,从而在不更新模型权重的前提下,精准识别并剪除低效专家。其核心研究问题在于实现无偏的模型压缩,通过精心排除常见评估基准的污染,确保剪枝决策的泛化性与鲁棒性,为高效模型部署奠定了新的方法论基础。
当前挑战
该数据集致力于解决混合专家模型剪枝中的校准挑战,即在保持模型核心能力的前提下,准确识别可安全移除的冗余专家。构建过程中的主要挑战在于确保数据集的代表性与无偏性。研究者必须精心筛选涵盖编码、工具调用、网络安全等十个领域的样本,同时严格排除HumanEval、MMLU等广泛使用的评估基准,以避免剪枝决策被特定任务模式所误导。此外,数据整合需处理多源异构数据的格式统一与版权合规,并在序列长度与批量处理上适配不同规模模型的观测需求,确保校准过程的效率与可靠性。
常用场景
经典使用场景
在混合专家模型(MoE)的优化研究中,该数据集被设计用于支持路由增强激活剪枝(REAP)方法的校准过程。通过提供覆盖函数调用、代理轨迹、网络安全等十个领域的多样化文本输入,它使研究者能够在推理模式下观察模型中各专家的激活模式,从而识别出那些极少被触发的冗余专家,为后续的剪枝决策提供数据支撑。
解决学术问题
该数据集主要解决了混合专家模型剪枝中的校准偏差问题。通过精心排除所有常见评估基准(如HumanEval、MMLU等),它确保了剪枝决策不会偏向于特定基准的模式,从而提升了剪枝过程的泛化性与可靠性。这为模型压缩领域提供了一种无基准污染的校准范例,有助于在保持模型核心能力的前提下,实现更高效、更公正的专家移除。
实际应用
在实际应用中,该数据集被直接用于大规模语言模型的轻量化部署。例如,在Qwen3.5-122B等模型系列中,通过基于此数据集收集的专家激活统计信息,成功移除了20%至40%的专家,同时保持了97.9%的原始能力。这显著降低了模型的计算开销与存储需求,为在资源受限环境中部署高性能MoE模型提供了可行的技术路径。
数据集最近研究
最新研究方向
在大型语言模型高效化部署的浪潮中,混合专家模型因其卓越的性能而备受瞩目,但其庞大的参数量也带来了严峻的计算挑战。REAP校准数据集v1的构建,正是为了支撑路由增强激活剪枝这一前沿技术,旨在无偏见地观测专家激活模式,从而精准识别并移除冗余专家。该数据集精心排除了所有常见评估基准的污染,确保了剪枝决策的普适性与鲁棒性,其多领域、偏向代码与工具使用的构成,精准契合了当前模型实用化的热点需求。这项工作不仅为MoE模型的高效压缩提供了关键工具,也推动了模型剪枝技术从依赖基准测试向更通用、更数据驱动的范式转变,对降低大模型部署成本具有深远意义。
以上内容由遇见数据集搜集并总结生成


