calme-legalkit-v0.1
收藏Hugging Face2024-08-20 更新2024-12-12 收录
下载链接:
https://huggingface.co/datasets/MaziyarPanahi/calme-legalkit-v0.1
下载链接
链接失效反馈官方服务:
资源简介:
Calme LegalKit v0.1是一个合成生成的数据集,旨在增强语言模型在法律推理和分析方面的能力。该数据集基于Louis Brulé Naudet的LegalKit构建,结合了先进的思维链(CoT)推理和专业法律知识。数据集的生成使用了NousResearch/Nous-Hermes-2-Mixtral-8x7B-DPO模型和Hugging Face的推理端点,通过高级提示技术生成高质量的合成法律数据。数据集包含多个特征,如对话、问题、输入、答案和模型等,主要用于训练和学术研究。
Calme LegalKit v0.1 is a synthetic dataset developed to enhance the legal reasoning and analytical capabilities of language models. This dataset is built upon Louis Brulé Naudet's LegalKit, integrating advanced Chain-of-Thought (CoT) reasoning and professional legal knowledge. The dataset was generated using the NousResearch/Nous-Hermes-2-Mixtral-8x7B-DPO model and Hugging Face inference endpoints, leveraging advanced prompting techniques to produce high-quality synthetic legal data. The dataset contains multiple features including dialogues, questions, inputs, answers, and model-related information, and is primarily intended for model training and academic research.
创建时间:
2024-08-19
原始信息汇总
Calme LegalKit v0.1 数据集概述
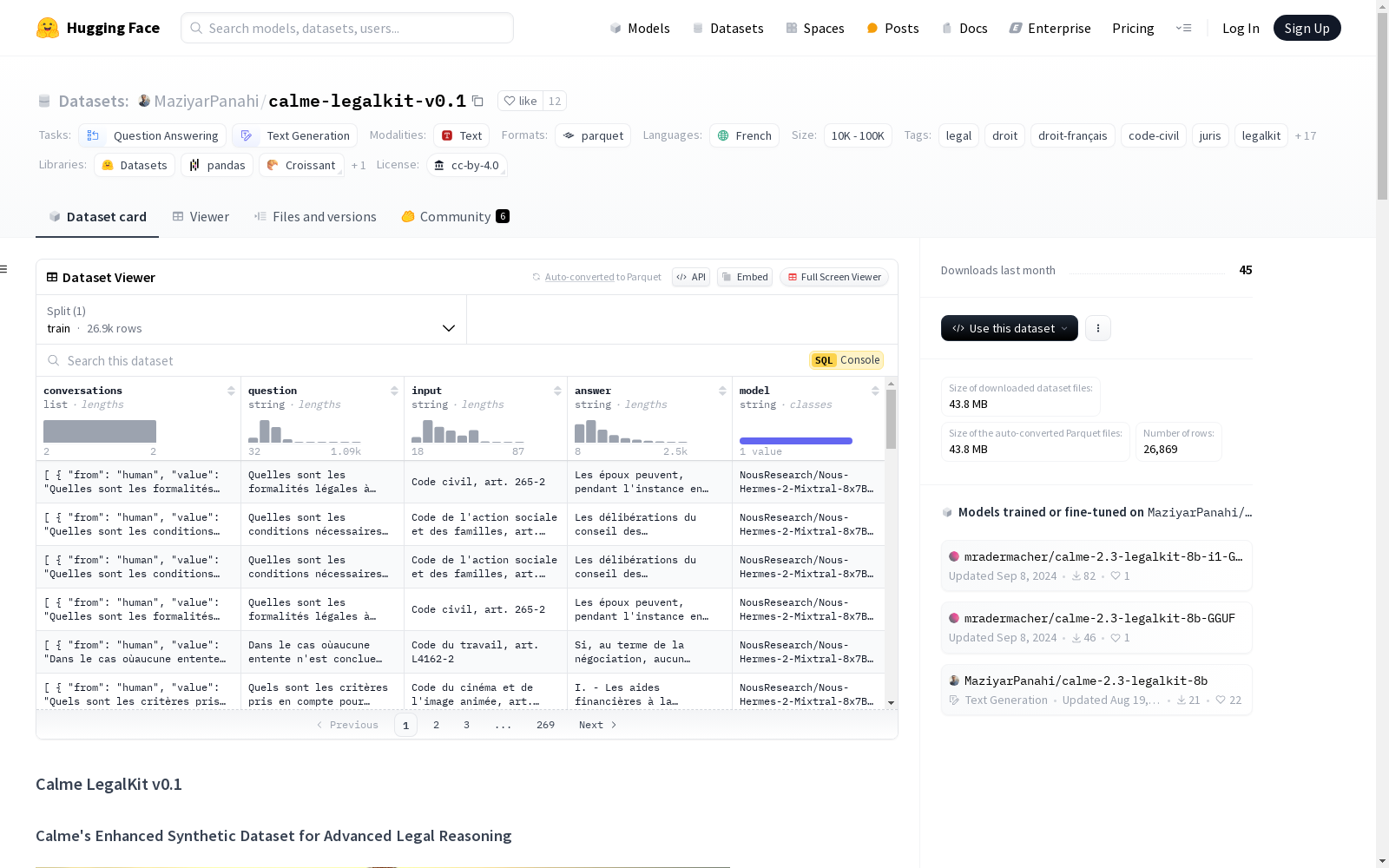
数据集信息
特征
- conversations:
- from: 字符串类型
- value: 字符串类型
- question: 字符串类型
- input: 字符串类型
- answer: 字符串类型
- model: 字符串类型
分割
- train:
- 字节数: 133740783
- 样本数: 26869
下载和数据大小
- 下载大小: 43792789 字节
- 数据集大小: 133740783 字节
配置
- default:
- data_files:
- split: train
- path: data/train-*
- data_files:
语言
- 法语 (fr)
许可证
- Creative Commons Attribution 4.0 (CC-BY-4.0)
任务类别
- 问答 (question-answering)
- 文本生成 (text-generation)
标签
- legal
- droit
- droit-français
- code-civil
- juris
- legalkit
- synthetic
- Livre des procédures fiscales
- Code du travail
- Code de commerce
- Code monétaire et financier
- Code général des impôts
- Code de la construction et de lhabitation
- Code de la défense
- Code de laction sociale et des familles
- Code civil
- Code de la consommation
- Code des assurances
- Code du cinéma et de limage animée
- Code de la propriété intellectuelle
- Code de la commande publique
- Code pénal
- Code des impositions sur les biens et services
- Livre des procédures fiscales
数据集大小类别
- 10K<n<100K
概述
Calme LegalKit v0.1 是一个合成生成的数据集,旨在增强语言模型在法律推理和分析能力方面的能力。该数据集基于 Louis Brulé Naudet 的 LegalKit,并结合了高级的思维链 (Chain of Thought, CoT) 推理和专业法律知识。
关键特性
- 使用最先进的语言模型生成合成数据
- 专注于法律推理和分析
- 采用思维链 (CoT) 方法
- 适用于微调小型专业语言模型
生成过程
数据集的创建过程如下:
- 基础模型:
NousResearch/Nous-Hermes-2-Mixtral-8x7B-DPO - 基础设施: Hugging Face 的 Inference Endpoint
- 方法: 使用高级提示技术生成高质量的合成法律数据
数据集统计
| 指标 | 值 |
|---|---|
| 总令牌数(含系统提示) | 22.10M |
| 总令牌数(不含系统提示) | 15.67M |
| 助手令牌数 | 14.68M |
| 每条记录的最小令牌数 | 101 |
| 每条记录的最大令牌数 | 1,423 |
| 每条记录的平均令牌数 | 583.37 |
使用案例
- 微调小型语言模型以进行法律任务
- 增强 AI 系统的法律推理能力
- 开发专业法律助手和聊天机器人
- 人工智能和法律领域的学术研究
研究影响
该数据集已被用于微调 calme-2.3-legalkit-8b,结果表明,小型语言模型在特定领域(如法律推理)可以有效地专业化,其性能可与比它们大十倍的模型相媲美甚至更好。
使用方法
要在您的项目中使用此数据集:
python from datasets import load_dataset
dataset = load_dataset("MaziyarPanahi/calme-legalkit-v0.1")
许可证
该数据集发布在 Creative Commons Attribution 4.0 许可证下。
搜集汇总
数据集介绍
构建方式
Calme LegalKit v0.1 数据集的构建基于先进的语言模型生成技术,采用了 `NousResearch/Nous-Hermes-2-Mixtral-8x7B-DPO` 作为基础模型,结合 Hugging Face 的推理端点进行数据生成。通过高级提示技术,生成了高质量的合成法律数据,旨在增强语言模型在法律推理和分析方面的能力。数据集的构建过程注重法律知识的深度整合,特别是通过 Chain of Thought (CoT) 方法,进一步提升了数据的逻辑性和实用性。
使用方法
Calme LegalKit v0.1 数据集的使用方法简单直观,用户可以通过 Hugging Face 的 `datasets` 库轻松加载数据集。具体操作如下:首先导入 `load_dataset` 函数,然后指定数据集的名称 `MaziyarPanahi/calme-legalkit-v0.1` 即可加载数据。该数据集适用于多种法律任务,如法律问答、文本生成等,尤其适合用于微调小型语言模型,以提升其在法律领域的推理和分析能力。用户还可以利用该数据集开发专业的法律助手或聊天机器人,或用于法学与人工智能交叉领域的研究。
背景与挑战
背景概述
Calme LegalKit v0.1 是一个专为增强法律推理和分析能力而设计的合成数据集,由 Maziyar Panahi 等人基于 Louis Brulé Naudet 的 LegalKit 数据集构建。该数据集于近期发布,旨在通过先进的链式思维(Chain of Thought, CoT)推理方法,提升语言模型在法语法律领域的表现。数据集涵盖了多个法国法典,如《民法典》、《劳动法》、《商法典》等,为法律领域的自然语言处理任务提供了丰富的语料支持。其核心研究问题在于如何通过合成数据生成技术,提升小型语言模型在复杂法律推理任务中的表现。该数据集的发布对法律人工智能领域具有重要影响,尤其是在法语法律文本处理方面,为学术研究和实际应用提供了新的工具和资源。
当前挑战
Calme LegalKit v0.1 面临的挑战主要体现在两个方面。首先,在法律领域问题的解决上,尽管数据集通过合成数据生成技术提升了法律推理能力,但法律文本的复杂性和多义性仍然对模型的准确性提出了较高要求。例如,法律术语的精确解释和上下文依赖的推理能力是模型需要克服的主要难题。其次,在数据集的构建过程中,如何确保生成数据的质量和多样性是一个关键挑战。尽管使用了先进的提示技术和高质量的基础模型,但合成数据的真实性、一致性和法律逻辑的严谨性仍需进一步验证。此外,数据集的规模相对较小,可能限制了模型在更广泛法律任务中的泛化能力。
常用场景
经典使用场景
Calme LegalKit v0.1数据集在法学领域的研究中具有重要应用,特别是在法律推理和文本生成任务中。该数据集通过合成数据生成技术,结合先进的Chain of Thought(CoT)方法,能够有效提升语言模型在法律文本理解和推理方面的能力。研究人员可以利用该数据集进行法律问答系统的开发,或用于训练专门的法律助手,以应对复杂的法律问题。
解决学术问题
Calme LegalKit v0.1数据集解决了法学与人工智能交叉领域中的多个关键问题。首先,它为法律推理任务提供了高质量的训练数据,弥补了传统法律数据集在多样性和复杂性上的不足。其次,通过引入CoT方法,该数据集帮助模型更好地理解法律条文的逻辑结构,从而提升了模型在法律文本生成和问答任务中的表现。这些改进为法学研究提供了新的工具和方法,推动了法律智能化的发展。
实际应用
在实际应用中,Calme LegalKit v0.1数据集被广泛用于开发法律智能助手和自动化法律咨询系统。例如,律师事务所可以利用该数据集训练模型,帮助律师快速检索相关法律条文或生成法律文书。此外,该数据集还可用于法律教育领域,为学生提供模拟法律案例分析的训练数据,提升其法律推理能力。这些应用不仅提高了法律工作的效率,还为公众提供了更便捷的法律咨询服务。
数据集最近研究
最新研究方向
近年来,随着人工智能在法律领域的应用日益广泛,Calme LegalKit v0.1数据集在增强法律推理和分析能力方面展现出显著的前沿研究价值。该数据集通过合成数据生成技术,结合先进的链式思维(CoT)方法,专注于法语法律文本的复杂推理任务。其独特之处在于利用Nous-Hermes-2-Mixtral-8x7B-DPO等大型语言模型生成高质量的法律数据,为小型语言模型的微调提供了强有力的支持。这一研究方向不仅推动了法律领域AI助手和聊天机器人的发展,还为学术界在AI与法律交叉领域的研究提供了丰富的实验数据。通过该数据集微调的模型在特定法律任务中表现出色,甚至超越了规模更大的通用模型,为法律智能化应用开辟了新的可能性。
以上内容由遇见数据集搜集并总结生成


