coco-human-inpainted-objects
收藏资源简介:
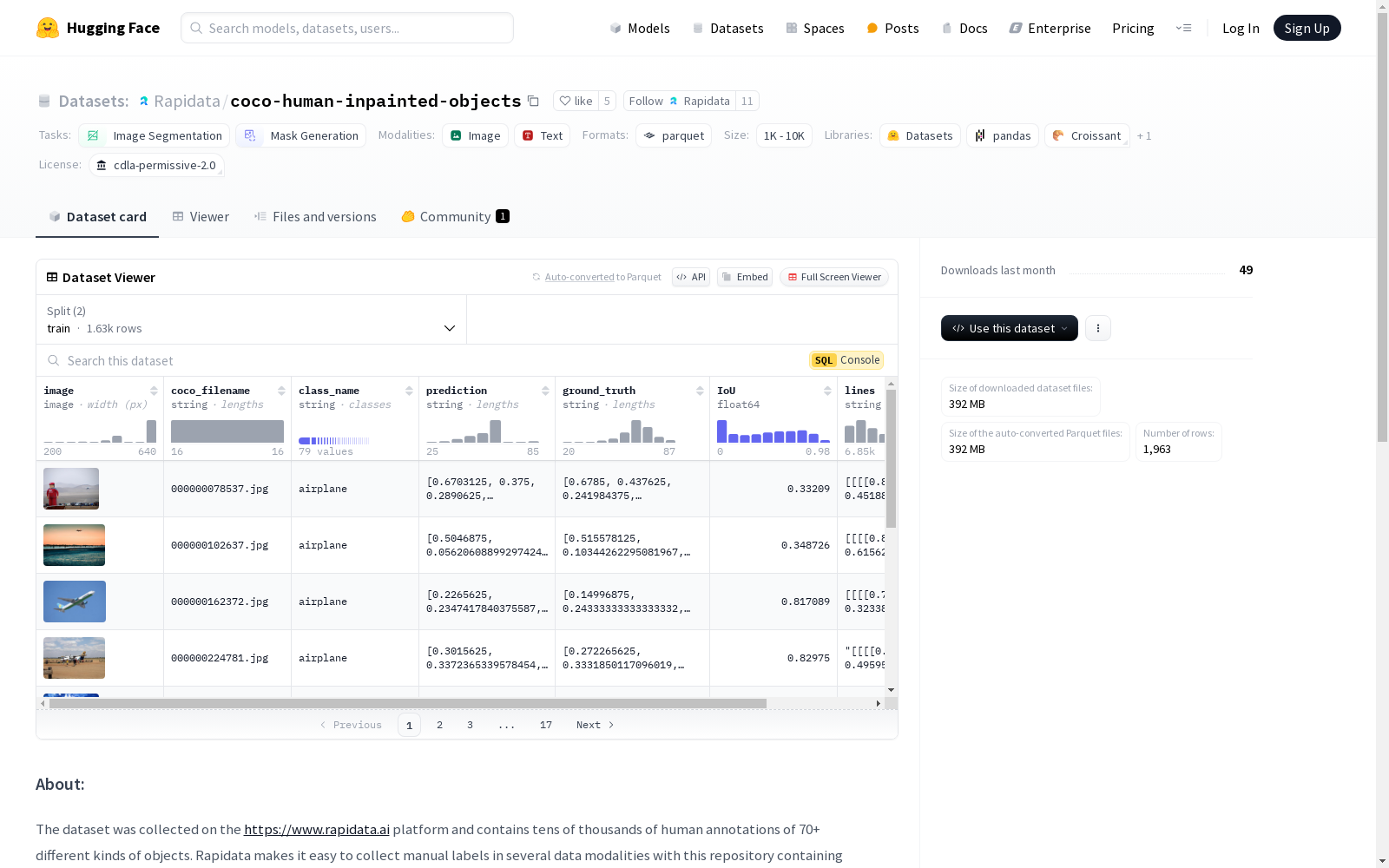
该数据集是从https://www.rapidata.ai平台收集的,包含数十万个人工标注的70多种不同类别的对象。数据集包含约2000张来自COCO数据集的图像,用户在这些图像上使用画笔工具绘制特定类别的对象。每张图像上只有一个目标对象,因此任务不模糊。用户交互的结果是用户在特定图像上绘制的线条集合。数据集的挑战在于将每张图像上的线条聚合起来,以了解目标对象的位置。每张图像提供了数百条由不同人绘制的2D线条,可用于创建目标对象的边界框和分割图。除了线条,数据集还包含COCO 2D边界框的地面真值以及基准预测。数据集的元数据文件描述了每张图像的详细信息,包括COCO文件名、类别名称、基准预测、地面真值、IoU分数以及用户绘制的线条的3D坐标数组。
This dataset is collected from the platform at https://www.rapidata.ai. It contains hundreds of thousands of manually annotated objects belonging to over 70 distinct categories. The dataset includes approximately 2,000 images sourced from the COCO dataset, on which users draw objects of specific categories using brush tools. There is exactly one target object per image, making the task unambiguous. The outcome of user interaction is a collection of lines drawn by users on the corresponding image. The core challenge of this dataset lies in aggregating the lines on each image to determine the location of the target object. Hundreds of 2D lines drawn by different users are provided for each image, which can be used to generate bounding boxes and segmentation masks for the target object. In addition to the lines, the dataset also includes the ground truth 2D bounding boxes from COCO as well as baseline predictions. The dataset's metadata file details each image, including the COCO filename, category name, baseline predictions, ground truth, IoU scores, and the 3D coordinate array of the user-drawn lines.
数据集概述
数据集信息
-
特征:
- image: 图像数据,数据类型为图像。
- coco_filename: 图像在COCO数据集中的唯一标识符,数据类型为字符串。
- class_name: 用户被要求在图像上标记的类别/类别名称,与COCO中的
category_name相同,数据类型为字符串。 - prediction: 基于热图的COCO边界框基线预测,数据类型为字符串。
- ground_truth: COCO边界框的地面真值,数据类型为字符串。
- IoU: 基线预测与地面真值之间的交并比(IoU)得分,数据类型为浮点数。
- lines: 坐标的三维数组,数据类型为字符串。每个用户可以绘制多条线,第一个维度表示不同的用户,第二个维度表示每个用户绘制的多条线,第三个维度表示每条线的[x, y]坐标,相对于图像尺寸。
-
分割:
- train: 训练集,包含1631个样本,大小为393005272.944字节。
- validation: 验证集,包含332个样本,大小为81827046.0字节。
-
下载大小: 391573463字节
-
数据集大小: 474832318.944字节
数据集结构
- 配置:
- default:
- train: 数据路径为
data/train-*。 - validation: 数据路径为
data/validation-*。
- train: 数据路径为
- default:
数据集描述
- 来源: 数据集在https://www.rapidata.ai平台上收集,包含70多种不同类型对象的数万个手动标注。
- 任务: 用户在图像上使用画笔工具绘制特定类别的对象,每个图像上只有一个此类对象,任务明确。
- 挑战: 数据集的挑战在于将每张图像上的线条聚合,以了解目标对象的位置。每张图像提供数百条由不同人类绘制的2D线条,可用于创建目标对象的边界框和分割图。
- 元数据:
metadata.csv文件描述了每张图像的信息,包含以下列:- coco_filename: 图像在COCO数据集中的唯一标识符。
- class_name: 用户被要求在图像上标记的类别/类别名称。
- prediction: 基于热图的COCO边界框基线预测。
- ground_truth: COCO边界框的地面真值。
- IoU: 基线预测与地面真值之间的交并比(IoU)得分。
- lines: 坐标的三维数组,表示不同用户绘制的线条及其坐标。