cuevascarlos/PICO-breast-cancer
收藏Hugging Face2024-06-17 更新2024-03-04 收录
下载链接:
https://hf-mirror.com/datasets/cuevascarlos/PICO-breast-cancer
下载链接
链接失效反馈官方服务:
资源简介:
该数据集是从PICO-Corpus中提取的,包含了1011篇来自PubMed的乳腺癌随机对照试验的摘要。数据集包含了26个实体,比通常的PICO语料库中的4个实体更多。数据集提供了三个版本:Data-v2(未分割的数据集)、Default_split-v2(按80%训练、10%验证、10%测试分割的数据集)和Train_test_split-v2(按80%训练、20%测试分割的数据集)。此外,数据集的预处理是为了分析命名实体识别的可重复性,所有代码都可以在GitHub上找到。
该数据集是从PICO-Corpus中提取的,包含了1011篇来自PubMed的乳腺癌随机对照试验的摘要。数据集包含了26个实体,比通常的PICO语料库中的4个实体更多。数据集提供了三个版本:Data-v2(未分割的数据集)、Default_split-v2(按80%训练、10%验证、10%测试分割的数据集)和Train_test_split-v2(按80%训练、20%测试分割的数据集)。此外,数据集的预处理是为了分析命名实体识别的可重复性,所有代码都可以在GitHub上找到。
提供机构:
cuevascarlos
原始信息汇总
PICO Breast Cancer Dataset Summary
Dataset Configurations
-
Data-v1
- Features:
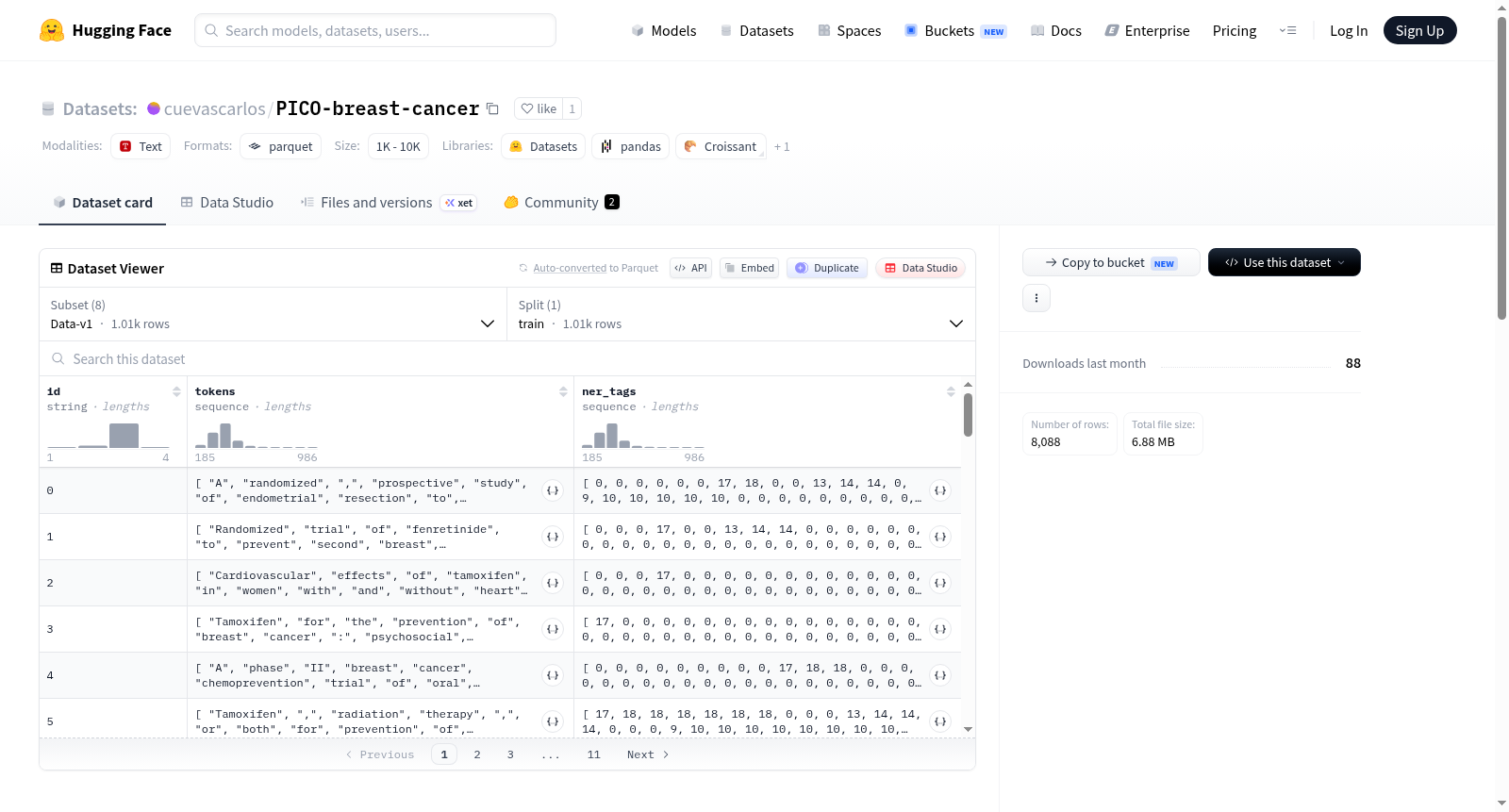
id: stringtokens: sequence of stringner_tags: sequence of class labels with names:- 0: O
- 1: B-total-participants
- ... (omitted for brevity)
- Splits:
train: 1011 examples, 6313125 bytes
- Download Size: 848172 bytes
- Dataset Size: 6313125 bytes
- Features:
-
Data-v2
- Features:
id: stringtokens: sequence of stringner_tags: sequence of class labels with names:- 0: O
- 1: B-total-participants
- ... (omitted for brevity)
- Splits:
train: 1011 examples, 6318272 bytes
- Download Size: 851739 bytes
- Dataset Size: 6318272 bytes
- Features:
-
Default_split-v1
- Features:
id: stringtokens: sequence of stringner_tags: sequence of class labels with names:- 0: O
- 1: B-total-participants
- ... (omitted for brevity)
- Splits:
train: 808 examples, 5021698 bytesvalid: 101 examples, 640991 bytestest: 102 examples, 650205 bytes
- Download Size: 868297 bytes
- Dataset Size: 6312894 bytes
- Features:
-
Default_split-v2
- Features:
id: stringtokens: sequence of stringner_tags: sequence of class labels with names:- 0: O
- 1: B-total-participants
- ... (omitted for brevity)
- Splits:
train: 808 examples, 5025842 bytesvalid: 101 examples, 641606 bytestest: 102 examples, 650824 bytes
- Download Size: 872281 bytes
- Dataset Size: 6318272 bytes
- Features:
-
Train_test_split-v1
- Features:
id: stringtokens: sequence of stringner_tags: sequence of class labels with names:- 0: O
- 1: B-total-participants
- ... (omitted for brevity)
- Splits:
train: 808 examples, 5021698 bytestest: 203 examples, 1291306 bytes
- Download Size: 865658 bytes
- Dataset Size: 6313004 bytes
- Features:
-
Train_test_split-v2
- Features:
id: stringtokens: sequence of stringner_tags: sequence of class labels with names:- 0: O
- 1: B-total-participants
- ... (omitted for brevity)
- Splits:
train: 808 examples, 5025842 bytestest: 203 examples, 1292430 bytes
- Download Size: 869544 bytes
- Dataset Size: 6318272 bytes
- Features:
Dataset Details
- Source: Extracted from PICO-Corpus.
- Content: 1,011 abstracts of breast cancer randomized controlled trials from PubMed.
- Entities: 26 entities.
- Preprocessing: Conducted as part of a project analyzing reproducibility in Named Entity Recognition.
搜集汇总
数据集介绍
构建方式
在生物医学文本挖掘领域,PICO框架(Population, Intervention, Comparison, Outcome)是结构化临床证据的核心要素。该数据集源自PICO-Corpus,精选自PubMed中1,011篇乳腺癌随机对照试验的摘要。构建过程中,研究者对原始语料进行了精细的预处理,使其可直接作为BERT类掩码语言模型的输入。数据集提供多种版本:Data-v2为无分割的完整集合;Default_split-v2按80%、10%、10%的比例划分为训练、验证与测试集;Train_test_split-v2则分为80%训练和20%测试集。版本2采用PubMed ID作为标识符,便于快速回溯原始文献。所有预处理代码均公开于GitHub仓库中。
特点
该数据集的核心特色在于其细粒度的实体标注体系,共包含26类实体,远超传统PICO语料库的4类基础实体。标注层次涵盖参与者总数、干预组人数、对照组人数、年龄、资格标准、种族、疾病状况、地理位置、干预措施、对照措施、结局指标等,并对二分类与连续型结局变量进行了细分,如绝对数值、百分比、均值、中位数、标准差及四分位数等。此外,还提供简化版本(Data-v1_4classes),将实体归纳为参与者、干预、对照与结局四大顶级类别,以适应不同研究需求。这种多层次、多维度的标注设计,为深入分析临床文本中的结构化信息提供了丰富的数据基础。
使用方法
研究者可通过HuggingFace Datasets库便捷地加载该数据集。根据任务需求选择相应配置,例如使用'Default_split-v2'获取预划分的训练、验证与测试集,或使用'train_test_split-v2'仅获取训练与测试集。数据以token序列和对应的NER标签序列形式存储,标签采用BIO标注方案。使用时需将token序列与预训练模型的词表对齐,并利用NER标签进行序列标注任务的训练与评估。对于需要简化实体类别的场景,可选择_4classes版本。所有数据均以Parquet格式存储,支持高效加载与批处理操作。
背景与挑战
背景概述
在循证医学蓬勃发展的当下,系统评价与荟萃分析作为指导临床决策的黄金标准,其核心在于从海量文献中精准提取PICO(Population, Intervention, Comparison, Outcome)要素。乳腺癌作为全球女性发病率居首的恶性肿瘤,相关随机对照试验(RCT)的文本挖掘需求尤为迫切。由Carlos Cuevas等人构建的PICO-breast-cancer数据集,源自PICO-Corpus项目,于近期发布在HuggingFace平台。该数据集精选了1,011篇来自PubMed的乳腺癌RCT摘要,其核心研究问题在于突破传统PICO实体识别的粗粒度局限,开创性地定义了26个细粒度实体类别,涵盖参与者数量、年龄、干预措施具体数值等临床关键信息,为提升信息提取的精确性与可复现性开辟了新路径,对推动临床试验自动化分析领域具有里程碑意义。
当前挑战
该数据集面临的核心挑战源于临床文本固有的复杂性与细粒度标注的艰巨性。在领域问题层面,传统的四类PICO实体(参与者、干预、对照、结局)无法满足对临床试验细节的深度理解,而将实体扩展至26类后,模型需精准区分如“干预组绝对计数(iv-bin-abs)”与“对照组百分比(cv-bin-percent)”等高度相似且语义微妙的标签,这对命名实体识别(NER)模型的上下文理解能力提出了极高要求。在构建过程中,挑战尤为突出:一方面,需从非结构化的PubMed摘要中手工标注海量细粒度实体,确保标注一致性;另一方面,数据集仅包含1,011条样本,且类别分布极不均衡,部分细粒度实体出现频次极低,易导致模型过拟合或泛化能力不足,亟需通过数据增强或迁移学习等策略加以应对。
常用场景
经典使用场景
在生物医学自然语言处理领域,PICO-breast-cancer数据集以其精细的实体标注体系脱颖而出,成为命名实体识别(NER)任务的经典基准。该数据集从PubMed收录的1011篇乳腺癌随机对照试验摘要中提取,不仅囊括了传统的PICO要素(参与者、干预、对照、结局),更将实体细化为26个子类别,如参与者总数、干预组人数、年龄、纳入标准、种族、疾病状况、地理位置等。研究者常利用该数据集训练和评估基于Transformer架构的预训练语言模型(如BERT),以精准识别临床试验文献中的关键信息要素,推动医学文本结构化提取技术的发展。
实际应用
在实际应用中,该数据集驱动的NER模型可无缝集成至医学文献管理系统与循证医学平台。例如,系统可自动从乳腺癌临床试验摘要中抽取出患者数量、干预措施、对照条件及结局指标,辅助研究者在撰写系统评价时快速筛选相关文献。此外,细粒度信息(如特定年龄段的参与者比例、不同种族分布)的自动提取,有助于评估试验结果的外部有效性,支持个性化医疗的循证决策。在药物研发与公共卫生领域,该工具可加速从海量临床证据中提炼关键参数,提升证据综合的效率与质量。
衍生相关工作
基于PICO-breast-cancer数据集,已衍生出多项具有影响力的研究工作。该数据集本身源于PICO-Corpus项目,其层次化标注体系启发了后续针对其他疾病领域(如心血管疾病、糖尿病)的细粒度PICO抽取数据集构建。在模型层面,研究者探索了基于条件随机场(CRF)与注意力机制的混合模型,以及利用预训练语言模型进行迁移学习的策略。此外,该数据集被用于评估NER任务的可复现性,催生了一系列关于标注一致性、模型鲁棒性及数据预处理标准化的方法论研究,推动了生物医学NLP领域对实验复现性的重视。
以上内容由遇见数据集搜集并总结生成


