LOGICAL-COMMONSENSEQA
收藏arXiv2026-01-28 更新2026-01-29 收录
下载链接:
https://huggingface.co/datasets/ojayy/logical-csqa
下载链接
链接失效反馈官方服务:
资源简介:
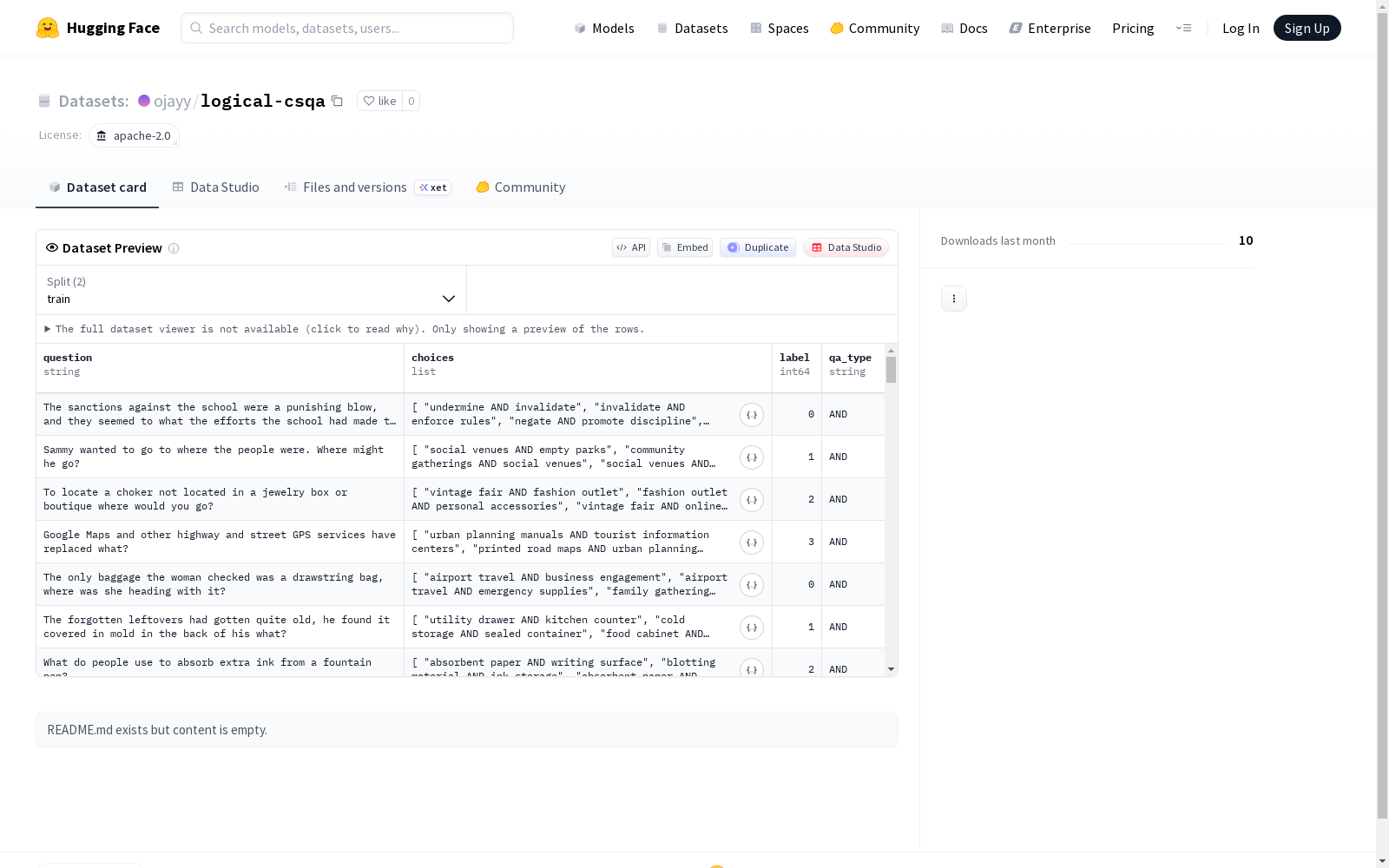
LOGICAL-COMMONSENSEQA是由科罗拉多大学博尔德分校构建的常识推理基准数据集,旨在通过逻辑组合关系(AND/OR/NEITHER/NOR)评估模型对多答案复合推理的能力。该数据集包含19,996条实例,源自COMMONSENSEQA的扩展重构,采用三阶段流水线构建:首先生成候选答案,随后通过GPT-4过滤优化,最后进行确定性逻辑组合。数据覆盖物理、社会及情境常识领域,通过人类标注验证其社会共识性。该数据集专门用于揭示传统单答案评测掩盖的模型缺陷,尤其在否定性复合推理(NEITHER/NOR)方面表现出显著挑战性,为推进组合式常识推理研究提供标准化框架。
LOGICAL-COMMONSENSEQA is a commonsense reasoning benchmark dataset constructed by the University of Colorado Boulder, aiming to evaluate models' ability to perform multi-answer complex reasoning via logical combinatorial relations (AND/OR/NEITHER/NOR). This dataset contains 19,996 instances, which is an extended and reorganized derivative of COMMONSENSEQA, and is built through a three-stage pipeline: first, generate candidate answers; second, filter and optimize using GPT-4; finally, conduct deterministic logical combination. The data covers physical, social and situational commonsense domains, and its social consensus is verified via human annotation. This dataset is specifically designed to reveal model flaws masked by traditional single-answer evaluations, and poses significant challenges especially in negative compositional reasoning (NEITHER/NOR), providing a standardized framework for advancing research on compositional commonsense reasoning.
提供机构:
科罗拉多大学博尔德分校
创建时间:
2026-01-23
原始信息汇总
数据集概述
基本信息
- 数据集名称: logical-csqa
- 发布者: ojayy
- 许可证: Apache 2.0
数据说明
- 数据集的详细描述、具体内容、规模、用途等信息未在提供的README文件中提供。
搜集汇总
数据集介绍
构建方式
在常识推理领域,传统基准往往局限于单一答案评估,难以捕捉现实情境中多重合理解释的复杂性。LOGICAL-COMMONSENSEQA的构建通过一个三阶段流程实现:首先基于COMMONSENSEQA的问题与答案,利用GPT-4o-mini生成多样化的候选原子陈述,涵盖合理与不合理选项;随后对这些候选进行精细化筛选,剔除逻辑不一致或事实错误的条目,并确保每个问题保留三个正确与四个错误的原子选项;最终通过符号程序将原子选项对确定性地组合为逻辑复合实例,标注为AND、OR或NEITHER/NOR关系,从而形成评估组合式常识推理的基准数据集。
特点
该数据集的核心特点在于将常识推理重新定义为逻辑组合任务,突破了传统单一答案模式的局限。每个实例以自然语言问题呈现,其选项并非原子答案,而是通过AND、OR或NEITHER/NOR运算符连接的两个独立陈述,分别表示联合合理、部分合理或联合不合理的关系。这种设计不仅保留了多项选择题的格式,还明确模拟了现实中的歧义性与组合推理需求。数据集包含近两万个实例,均匀分布于不同逻辑关系类型,并引入了混合条件以阻止模型依赖运算符特定模式,从而更真实地评估模型对组合式合理性的理解能力。
使用方法
使用LOGICAL-COMMONSENSEQA时,模型需根据给定问题,从四个逻辑复合选项中选择其组合合理性最符合常识约束的一项。评估可在零样本、少样本或监督微调等多种范式下进行,涵盖指令调优、推理专用及微调模型。在零样本和少样本设置中,通过提示工程引导模型输出对应选项字母;在监督微调中,模型基于训练集学习逻辑组合模式。数据集的分层划分确保了各逻辑关系在训练、开发和测试集中的均衡分布,支持以准确率和宏观F1分数等指标系统衡量模型在组合式常识推理上的性能,尤其凸显了模型在否定性推理方面的薄弱环节。
背景与挑战
背景概述
在人工智能与自然语言理解领域,常识推理作为人类认知的核心能力,长期以来面临评估框架的局限性。传统基准如COMMONSENSEQA虽推动了神经模型的发展,却将多义性问题简化为单一答案选择,掩盖了陈述间联合合理、部分合理或联合不合理等复杂关系。为应对这一挑战,科罗拉多大学博尔德分校的研究人员Obed Junias与Maria Leonor Pacheco于2024年提出了LOGICAL-COMMONSENSEQA数据集。该数据集重构了常识推理任务,通过合取、析取与否定三类逻辑算子对原子陈述进行组合,旨在评估模型对组合式合理性的判断能力。其创新性在于保留了多项选择题格式的同时,引入了基于社会共识的合理性层级操作,为深入探究语言模型的组合推理缺陷提供了可控框架。
当前挑战
LOGICAL-COMMONSENSEQA所针对的核心领域挑战在于,现有模型难以处理常识推理中固有的模糊性与组合性。具体而言,模型在否定性组合(NEITHER/NOR)上表现急剧下降,暴露了其在同时处理否定语义与合理性评估时的根本局限。此外,数据集构建过程亦面临多重挑战:一是生成兼具多样性与推理深度的候选答案时,需避免浅层词汇匹配与事实性错误;二是通过人工验证确保答案选项既反映个人合理性认知,又符合社会共识,这一过程要求精细的标注设计与裁决机制;三是将原子陈述确定性地组合为逻辑结构时,需维持算子语义的一致性,避免引入命题逻辑之外的混淆。
常用场景
经典使用场景
在自然语言理解与常识推理领域,LOGICAL-COMMONSENSEQA 数据集被广泛用于评估大型语言模型在组合式逻辑推理方面的能力。该数据集通过将常识问题重构为包含逻辑运算符(AND、OR、NEITHER/NOR)的复合选项,要求模型不仅判断单个陈述的合理性,还需理解多个陈述在逻辑关系下的联合意义。这一设计使得研究者能够系统检验模型在处理联合合理、部分合理或联合不合理情境时的表现,从而深入揭示模型在组合推理中的薄弱环节,特别是在基于否定的推理任务上。
解决学术问题
LOGICAL-COMMONSENSEQA 主要解决了传统常识推理基准中单一答案评估的局限性问题。以往数据集如 COMMONSENSEQA 仅要求模型选择单个正确答案,忽视了现实场景中常存在的多重合理解释。该数据集通过引入逻辑组合结构,使评估焦点转向模型对陈述间关系(如同时成立、至少其一成立或均不成立)的判别能力。这不仅暴露了模型在否定性推理上的显著缺陷,还促进了针对组合式常识推理的模型改进研究,推动了更接近人类直觉推理的评估框架发展。
衍生相关工作
围绕 LOGICAL-COMMONSENSEQA 衍生出多项经典研究工作,主要集中在扩展逻辑运算符集、结合社会共识验证框架以及探索生成式推理任务。例如,后续研究尝试引入蕴含(IMPLY)或排他(XOR)等更丰富的逻辑关系,以覆盖更复杂的推理模式。同时,部分工作借鉴该数据集的社会感知标注方法,构建了融合个体认知与集体共识的评估体系。此外,基于其组合式结构,研究者开发了链式思维提示策略与微调技术,显著提升了模型在否定性推理任务上的性能,为常识推理的符号与神经结合提供了新范式。
以上内容由遇见数据集搜集并总结生成


