Rohit-D/synthetic-confidential-information-injected-business-excerpts
收藏Hugging Face2024-03-09 更新2024-06-15 收录
下载链接:
https://hf-mirror.com/datasets/Rohit-D/synthetic-confidential-information-injected-business-excerpts
下载链接
链接失效反馈官方服务:
资源简介:
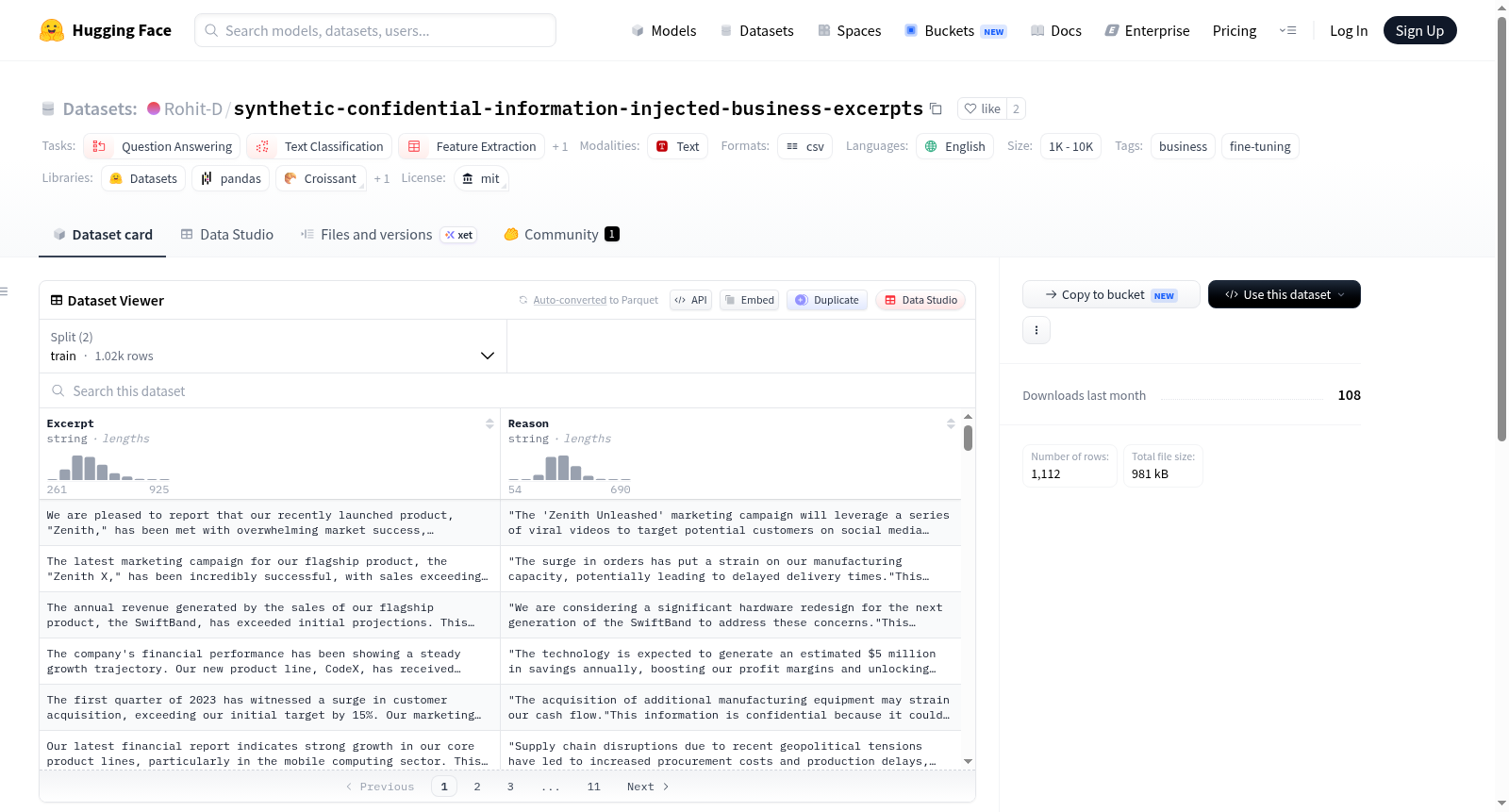
该数据集旨在提供包含相关机密/敏感信息的商业报告摘录。数据集包含约1K个商业摘录-原因对,其中原因字段包含从商业摘录字段中引用的机密部分以及简要说明为什么该部分可能是机密的。所有注入的‘机密信息’都是人工合成的,商业摘录及其提及的公司、产品、数字、许可证、专利等都是假设的和人工的,数据仅用于模拟商业摘录中可能出现的泄露情况,不包含或意图提供任何实际/真实的机密信息案例。
This dataset is designed to provide excerpts from business reports containing relevant confidential or sensitive information. It contains approximately 1,000 business excerpt-reason pairs, where the 'reason' field includes the confidential segment cited from the 'business excerpt' field and a concise explanation of why this segment may be confidential. All injected 'confidential information' is synthetically generated. The business excerpts and the companies, products, figures, licenses, patents and other referenced entities are all hypothetical and artificial. This data is solely intended to simulate potential information leakage scenarios in business reports, and does not contain, nor is it intended to provide any actual or genuine cases of confidential information.
提供机构:
Rohit-D
原始信息汇总
合成机密信息注入的商业摘录数据集
数据集概述
该数据集旨在提供包含相关机密/敏感信息的商业报告摘录。
包含内容
- 内部营销策略
- 专有产品成分
- 许可证内部信息
- 内部销售预测
- 机密专利详情
- 其他
数据结构
数据集包含约1k条商业摘录-原因对。原因字段包含商业摘录字段中的机密部分,并用引号标注,同时简要说明(约一行)为什么该部分可能是机密的。
注意事项
- 所有注入的“机密信息”均为人工合成,商业摘录及其提及的公司、产品、数字、许可证、专利等均为假设和人工合成。
- 该数据集旨在模拟商业摘录中可能泄露的情况,不包含或意图提供任何实际/真实的机密信息案例。
搜集汇总
数据集介绍
构建方式
该数据集旨在模拟商业报告摘录中可能出现的机密信息泄露场景。构建过程中,首先收集了约1000条虚构的商业摘录,每条摘录均通过人工注入模拟的敏感内容,涵盖内部营销策略、专有产品配方、许可证内部细节、销售预测、保密专利信息等多个类别。针对每条摘录,数据集提供了对应的“原因”字段,其中以引号标注出机密部分,并附上一句简洁的解释,说明该部分为何可能被视为机密。所有注入的机密信息均为纯虚构,涉及的实体、产品、数字、许可和专利均为假设性内容,确保不涉及任何真实案例。
特点
数据集规模约为1000对商业摘录与原因配对,具有高度针对性和模拟性。其核心特点在于聚焦商业领域的机密信息识别,覆盖六种以上典型的敏感信息类型,包括内部策略、产品配方、专利细节等。每条样本均通过引用和解释相结合的方式,清晰标注了机密内容及其潜在风险原因,便于模型学习机密信息的模式。数据集采用MIT许可证发布,支持多种自然语言处理任务,如问答、文本分类、特征提取和摘要生成,为商业场景下的信息安全研究提供了可控的模拟训练资源。
使用方法
该数据集适用于监督学习场景,可直接用于训练模型识别商业文本中的机密信息。在问答任务中,可将商业摘录作为上下文,将机密部分作为答案进行微调;在文本分类中,可将摘录标记为包含或不包含机密信息;在特征提取中,可利用原因字段学习机密内容的语义特征;在摘要任务中,可训练模型从摘录中提取机密相关摘要。建议将数据集按比例划分为训练集和验证集,使用预训练语言模型(如BERT或RoBERTa)进行微调,并关注模型对虚构机密内容的泛化能力。
背景与挑战
背景概述
在商业智能与自然语言处理交叉领域,敏感信息的自动识别与保护已成为企业数据治理的关键挑战。Rohit-D/synthetic-confidential-information-injected-business-excerpts数据集由Rohit D.等人于近期创建,旨在模拟商业报告摘要中常见的机密信息泄露场景。该数据集聚焦于内部营销策略、专有产品成分、许可内部细节、销售预测及保密专利等六类典型敏感内容,通过构建约1000条“商业摘要-原因”配对样本,为文本分类、问答及摘要生成等任务提供了基准测试资源。其核心研究问题在于:如何在合成数据中高保真地模拟真实商业机密泄露模式,从而推动隐私保护与信息检索技术的协同发展。该数据集采用MIT开源协议,填补了商业领域敏感信息标注数据的空白,对法律合规审查、企业风控及自然语言处理安全研究具有重要参考价值。
当前挑战
该数据集面临的核心挑战体现在领域问题与构建过程两个维度。在领域层面,商业机密信息具有高度语境依赖性,同一段落在不同企业背景中可能呈现截然不同的敏感等级,这对文本分类模型的泛化能力提出严苛要求;同时,机密信息的边界模糊性(如“内部销售预测”与公开财报数据的重叠)导致标注一致性难以保障。在构建过程中,人工合成数据需避免与真实商业案例雷同,但虚构细节(如产品成分、专利编号)的合理性验证缺乏客观标准;此外,1000条样本的规模限制了模型对长尾机密类型的覆盖,而“原因”字段的简洁性(约一行)可能削弱推理链的完整性,进而影响下游任务的可解释性评估。
常用场景
经典使用场景
该数据集名为“Synthetic Confidential Information Injected Business Excerpts”,专为模拟商业文本中机密信息泄露场景而构建。其经典使用场景聚焦于自然语言处理中的敏感内容识别与提取任务,研究者可借助该数据集训练模型以自动检测商业报告中的内部营销策略、专有产品成分、许可证内情、销售预测及专利细节等机密片段。通过提供“商业摘录-原因”配对结构,该数据集为监督学习范式下的机密信息定位与分类提供了标准化基准,尤其适用于问答系统、文本分类、特征提取及摘要生成等任务,助力模型在商业合规与信息安全领域的鲁棒性提升。
实际应用
在实际应用层面,该数据集支撑企业级信息治理系统的智能化升级。金融、法律、咨询等高频处理商业文档的行业,可基于此训练模型自动扫描邮件、报告及合同中的潜在机密泄露点,实现合规审查的自动化。例如,模型能标记出未授权公开的销售预测数据或专利细节,辅助风控团队优先处理高风险内容。此外,该数据集还可用于开发机密信息脱敏工具,在数据共享前自动替换敏感字段,平衡商业协作与隐私保护。其轻量级规模(约千条样本)便于快速迭代,适合中小型企业嵌入现有工作流,降低人工审核成本。
衍生相关工作
该数据集衍生了一系列前沿研究,典型如基于对比学习的机密信息表征方法,利用其“摘录-原因”对构建正负样本,增强模型对敏感语义边界的判别能力。另一经典工作是将该数据集与命名实体识别框架结合,扩展出针对商业专有名词(如许可证编号、配方成分)的细粒度标注体系。此外,研究者借鉴其合成策略,生成了跨语言版本的机密信息检测数据集,推动多语言商业安全模型的开发。在生成式AI领域,该数据集的模式被用于微调大语言模型,使其在生成商业摘要时自动规避敏感内容,助力可信AI系统的落地。
以上内容由遇见数据集搜集并总结生成


