llama-mesh-obj-annotations
收藏Hugging Face2025-05-11 更新2025-05-12 收录
下载链接:
https://huggingface.co/datasets/MLDen/llama-mesh-obj-annotations
下载链接
链接失效反馈官方服务:
资源简介:
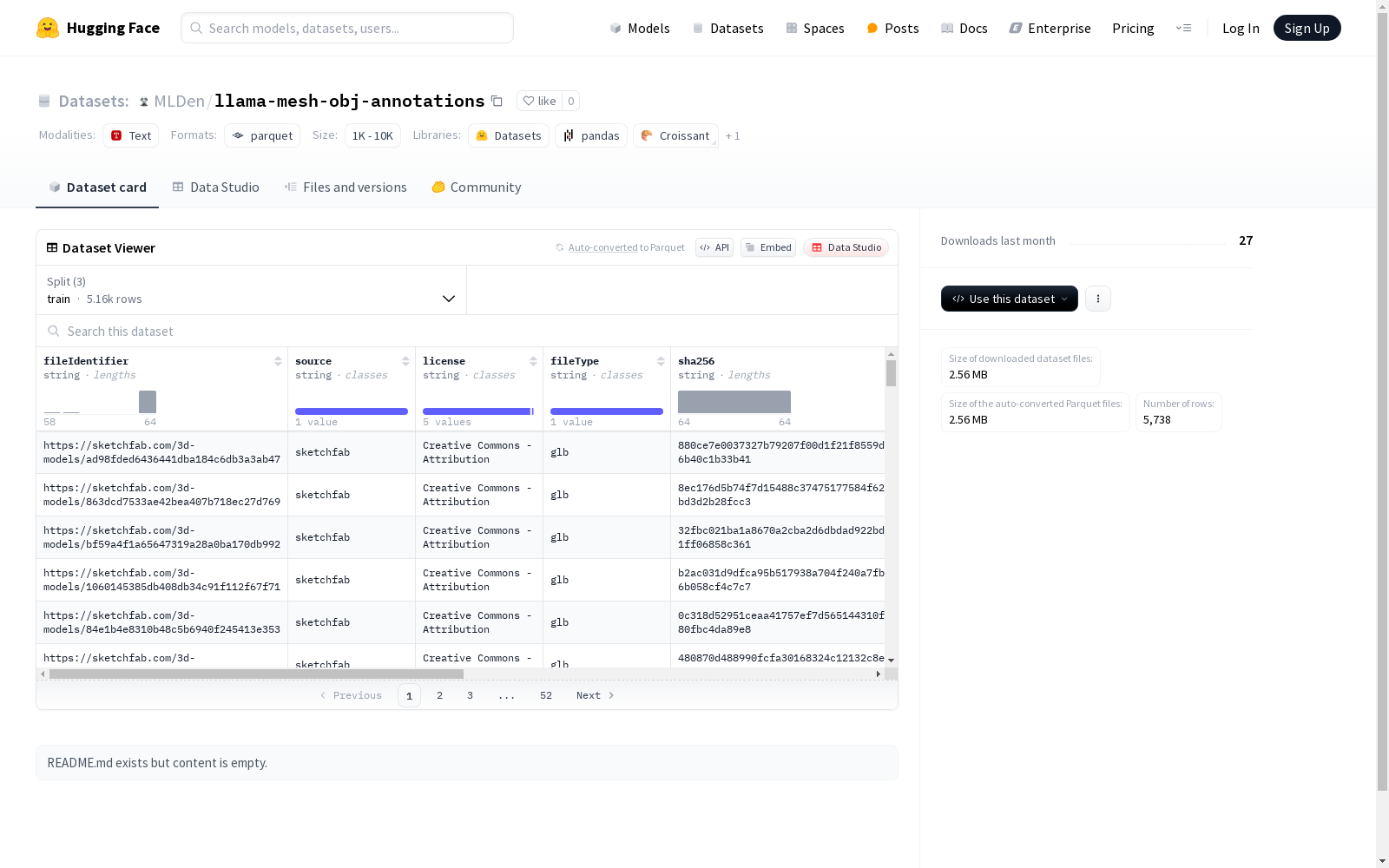
这是一个包含多个字段的数据集,字段包括文件标识符、来源、许可、文件类型、哈希值、元数据、审美评分和字幕等。数据集分为训练集、验证集和测试集三个部分,分别用于不同的训练和评估阶段。
This is a dataset comprising multiple fields, including file identifier, source, license, file type, hash value, metadata, aesthetic rating, subtitles, etc. The dataset is divided into three subsets: training set, validation set and test set, which are respectively used for different training and evaluation stages.
创建时间:
2025-05-11
搜集汇总
数据集介绍
构建方式
在三维模型处理与计算机视觉领域,llama-mesh-obj-annotations数据集通过系统化采集和标注流程构建而成。该数据集包含5,163个训练样本、298个验证样本和277个测试样本,每个样本均包含文件标识符、来源、许可协议、文件类型等结构化元数据。数据采集过程注重多样性,涵盖不同来源的三维模型文件,并通过SHA256校验确保数据完整性。标注工作不仅包含基础文件信息,还创新性地引入了美学评分和文字描述,为模型提供多维度学习特征。
特点
该数据集最显著的特点在于其多维度的标注体系。除常规的文件元数据外,每个三维模型都配有详细的美学评分和文字描述,为计算机视觉研究提供了丰富的语义信息。数据集采用标准化的训练-验证-测试划分,确保模型评估的可靠性。文件类型字段明确标注了模型格式,便于研究者进行针对性处理。高达6MB的总数据规模保证了模型的训练需求,而精确的校验机制则维护了数据质量的一致性。
使用方法
研究者可通过标准数据加载接口快速获取该数据集,其结构化存储格式兼容主流机器学习框架。训练集适用于模型参数优化,验证集用于超参数调整,测试集则用于最终性能评估。美学评分字段可用于生成模型的质量评估任务,文字描述字段支持跨模态学习研究。数据集的标准化划分方案允许研究者直接进行对比实验,而详细的元数据则为数据筛选和预处理提供了便利条件。
背景与挑战
背景概述
llama-mesh-obj-annotations数据集是近年来三维计算机视觉领域的重要资源,专注于为网格对象提供详尽的标注信息。该数据集由专业研究团队构建,旨在解决三维模型理解与生成中的语义标注难题。通过整合多源三维模型数据并附加美学评分、文本描述等元数据,该数据集为三维形状分析、跨模态检索等任务提供了标准化基准。其5163个训练样本的规模及精细的标注体系,显著促进了三维深度学习模型在语义理解方面的研究进展。
当前挑战
该数据集核心挑战在于三维模型语义标注的复杂性与主观性。网格对象的多视角特征提取需要解决几何拓扑不一致性问题,而美学评分等主观标注易受评判标准差异影响。构建过程中面临多源数据格式兼容性难题,需统一OBJ/FBX等不同文件类型的元数据规范。文本描述与三维视觉特征的跨模态对齐亦存在语义鸿沟,这对标注质量提出了更高要求。
常用场景
经典使用场景
在三维计算机视觉和图形学领域,llama-mesh-obj-annotations数据集因其丰富的三维网格对象和标注信息而成为经典资源。该数据集广泛应用于三维物体重建、形状分析和语义分割等任务。研究者通过其提供的网格数据和对应的标注信息,能够高效训练和验证深度学习模型,提升模型在复杂三维场景中的理解和生成能力。
实际应用
在实际应用中,llama-mesh-obj-annotations数据集为虚拟现实、增强现实和游戏开发提供了重要支持。其标注的三维网格对象可直接用于场景构建和物体生成,显著提升了内容创作的效率。工业设计领域亦可通过该数据集训练生成模型,快速原型化复杂的三维结构,缩短产品开发周期。
衍生相关工作
围绕llama-mesh-obj-annotations数据集,学术界已衍生出多项经典工作。其中包括基于其网格数据的三维生成对抗网络(3D-GAN)优化研究,以及结合文本标注的跨模态检索系统开发。这些工作不仅扩展了数据集的用途,也为三维视觉领域的算法创新提供了重要基准。
以上内容由遇见数据集搜集并总结生成


