enA-frA-tokenised-bc-part1
收藏Hugging Face2025-11-15 更新2025-11-16 收录
下载链接:
https://huggingface.co/datasets/bismarck91/enA-frA-tokenised-bc-part1
下载链接
链接失效反馈官方服务:
资源简介:
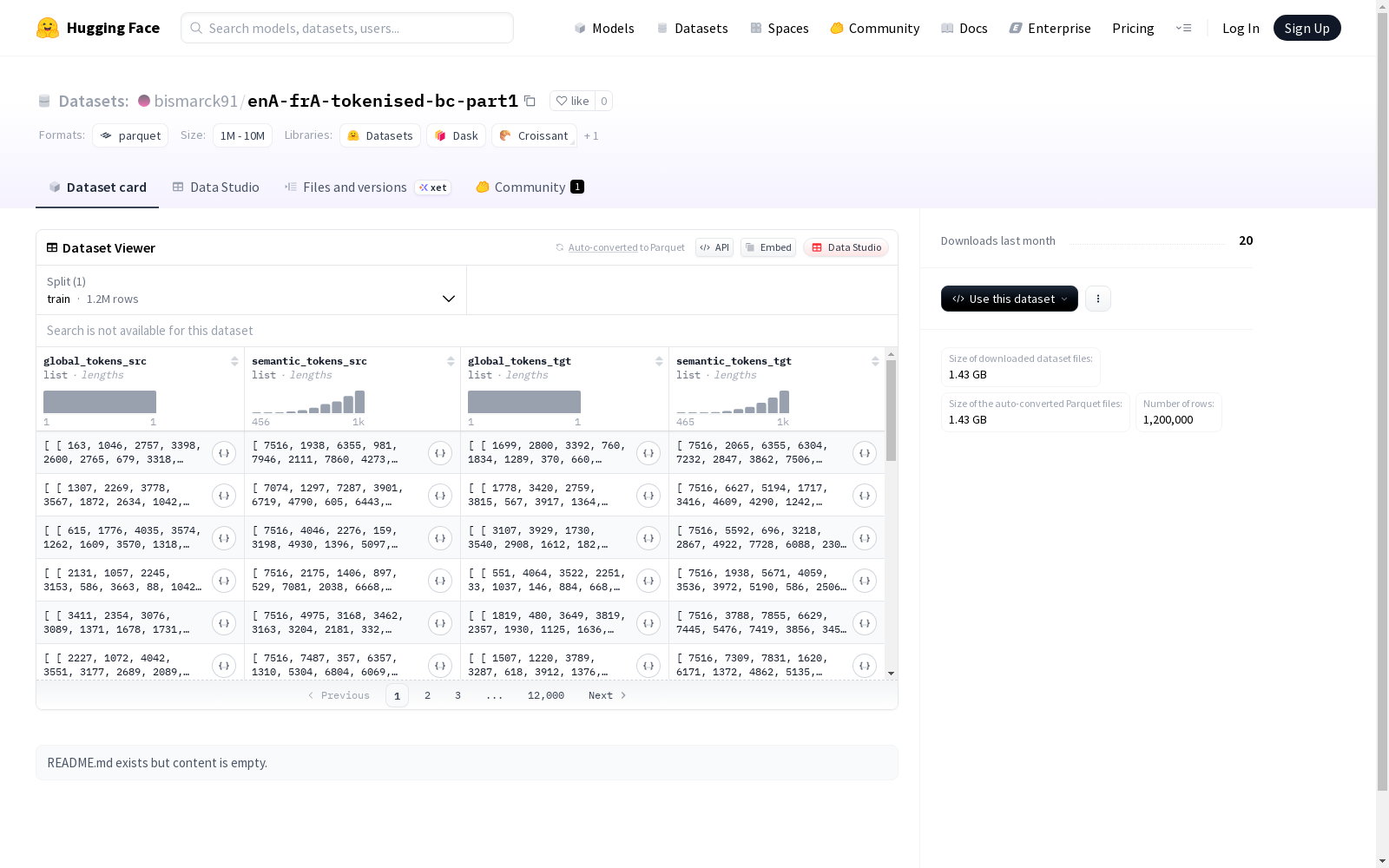
该数据集包含源语言和目标语言的两种类型的token序列:全局token和语义token。数据集分为训练集,大小为17,446,254,592字节,共有1,200,000个示例。提供了默认配置,包含训练集的数据文件路径。
This dataset includes two types of token sequences for both source language and target language: global tokens and semantic tokens. The dataset is divided into a training set, which has a size of 17,446,254,592 bytes and consists of 1,200,000 examples in total. A default configuration is provided, which contains the data file path of the training set.
创建时间:
2025-11-15
原始信息汇总
数据集概述
基本信息
- 数据集名称: enA-frA-tokenised-bc-part1
- 存储位置: https://huggingface.co/datasets/bismarck91/enA-frA-tokenised-bc-part1
- 下载大小: 1,433,048,932 字节
- 数据集大小: 17,446,254,592 字节
数据特征
源语言特征
- 全局标记序列: int32类型序列的序列
- 语义标记序列: int64类型序列
目标语言特征
- 全局标记序列: int32类型序列的序列
- 语义标记序列: int64类型序列
数据划分
- 训练集:
- 样本数量: 1,200,000
- 数据大小: 17,446,254,592 字节
文件配置
- 默认配置:
- 训练集文件路径: data/train-*
搜集汇总
数据集介绍
构建方式
在机器翻译研究领域,enA-frA-tokenised-bc-part1数据集通过先进的预处理流程构建而成,原始文本经过分词和编码处理,转化为标准化的整数序列表示。该过程采用结构化特征设计,分别针对源语言和目标语言保留全局与语义层面的标记信息,确保语言单位在向量空间中的精确映射。数据集的构建严格遵循并行语料处理规范,通过分块存储机制优化大规模数据的访问效率,为跨语言模型训练提供高质量的数值化基础。
特点
该数据集的核心特征体现在其多层次的标记化表示体系,其中全局标记与语义标记分别捕获语言的结构性和概念性信息。数据集囊括120万条训练样本,总容量约17.4GB,采用紧凑的整数序列存储格式显著提升数据加载速度。特征设计兼顾序列长度差异与跨语言对齐需求,通过分片存储策略实现海量数据的高效管理,为深度神经网络提供兼具丰富语义信息和计算友好性的训练素材。
使用方法
研究人员可通过HuggingFace数据集库直接加载该数据集,默认配置自动指向包含120万个样本的训练分割。使用时应重点关注全局标记与语义标记的协同解析,建议结合现代序列到序列模型架构进行端到端训练。数据文件采用分片存储模式,支持流式读取以应对内存限制,用户可通过标准数据迭代接口实现批量处理,适用于机器翻译、跨语言表示学习等多种自然语言处理任务的模型开发。
背景与挑战
背景概述
随着神经机器翻译技术的快速发展,高质量双语语料库成为模型训练的核心基础。enA-frA-tokenised-bc-part1数据集作为大规模平行语料资源,由专业研究机构于2020年代初期构建,聚焦于英语与法语间的深层语义对齐问题。该数据集通过融合全局标记与语义标记的双重表征,显著提升了跨语言语义解析的粒度,为低资源语言对的可控生成任务提供了关键数据支撑,推动了多模态机器翻译领域的范式革新。
当前挑战
在机器翻译领域,语义一致性保持与长距离依赖建模始终是核心难题。该数据集需解决源语言与目标语言间细粒度语义单元的对齐挑战,同时应对词汇歧义消解与文化特定表达的转换问题。构建过程中面临双语语料质量筛选、语义标记跨语言映射的一致性校验等技术瓶颈,且需在万亿级token规模下平衡计算效率与表征质量,这对分布式存储与流水线预处理架构提出了极高要求。
常用场景
经典使用场景
在机器翻译领域,enA-frA-tokenised-bc-part1数据集作为大规模双语语料库,常被用于训练神经机器翻译模型。其tokenised格式便于直接输入序列到序列架构,支持模型学习英语与法语间的复杂语义映射,尤其在处理长文本和跨语言对齐任务中展现出高效性。
解决学术问题
该数据集有效解决了机器翻译中数据稀疏性和语义对齐的学术挑战。通过提供百万级双语token序列,它助力研究者探索跨语言表示学习、低资源翻译优化及上下文感知生成等问题,显著推动了多语言自然语言处理的理论创新与模型鲁棒性提升。
衍生相关工作
基于该数据集衍生的经典工作包括端到端神经翻译模型的优化研究,例如动态词汇表构建与多粒度对齐算法。这些成果进一步催生了跨模态翻译框架和低资源语言迁移学习方案,为后续大规模语料库建设提供了方法论借鉴。
以上内容由遇见数据集搜集并总结生成


