HKMMLU
收藏Hugging Face2025-05-08 更新2025-05-09 收录
下载链接:
https://huggingface.co/datasets/chuxuecao/HKMMLU
下载链接
链接失效反馈官方服务:
资源简介:
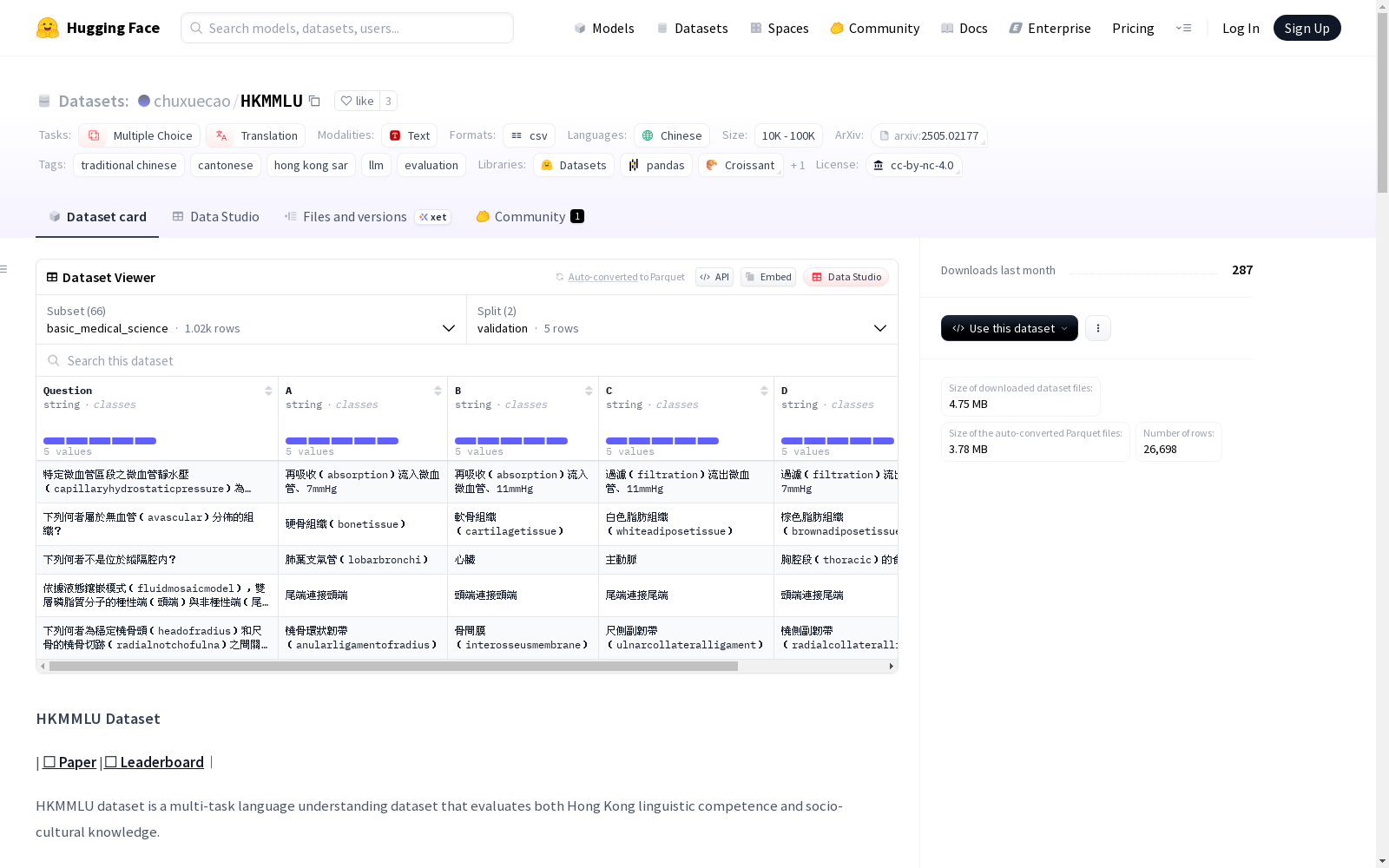
HKMMLU数据集是一个多任务语言理解数据集,旨在评估香港的语言能力和社会文化知识。它包括26,698个选择题,涵盖66个学科,分为STEM(科学、技术、工程和数学)、社会科学、人文和其他四大类。此外,该数据集还包括88,292个普通话-粤语翻译任务。
The HKMMLU dataset is a multi-task language understanding dataset designed to evaluate language proficiency and socio-cultural knowledge in Hong Kong. It includes 26,698 multiple-choice questions covering 66 disciplines, which are divided into four major categories: STEM (Science, Technology, Engineering and Mathematics), Social Sciences, Humanities and Others. Additionally, this dataset also contains 88,292 Mandarin-Cantonese translation tasks.
创建时间:
2025-04-26
搜集汇总
数据集介绍
构建方式
在构建HKMMLU数据集时,研究者采用了系统化的多源数据整合策略,涵盖科学、技术、工程、数学、社会科学、人文学科及其他领域。通过精心设计的66个专业科目,数据集汇集了26,698道高质量选择题,并额外纳入88,292项普通话与粤语翻译任务,以全面评估语言模型的多领域认知能力。数据采集过程注重专业性与地域特色,尤其在香港社会文化相关科目中融入了本地化知识要素,确保了数据集的学术严谨性和文化代表性。
特点
HKMMLU数据集展现出显著的跨学科与多语言特性,其内容架构划分为STEM、社会科学、人文学科及其他四大类别,全面覆盖专业学术领域与日常生活常识。数据集特别强调香港地区的语言文化特征,包含丰富的粤语翻译任务,为评估模型在多元文化语境下的理解能力提供了独特视角。其规模达到数万条样本,兼具广度与深度,能够有效支撑复杂语言智能任务的基准测试与研究验证。
使用方法
使用HKMMLU数据集时,研究者可通过HuggingFace平台便捷加载特定科目或整体数据,支持灵活的分割配置如测试集与验证集。数据以结构化格式存储,包含问题、选项及标准答案等关键字段,便于直接应用于多项选择任务的模型评估。用户可依据研究需求选择单一科目深入分析,或整合多科目进行综合性能测评,该设计显著提升了数据集在语言模型能力基准测试中的实用性与可扩展性。
背景与挑战
背景概述
在人工智能语言模型快速发展的背景下,针对区域化知识评估的需求日益凸显。HKMMLU数据集作为2025年发布的综合性评估基准,由研究团队基于香港特别行政区的多元文化背景构建,涵盖STEM、社会科学、人文学科及其他领域共66个学科主题。该数据集通过26,698道选择题与88,292项翻译任务,系统评估模型对粤语语言特性及香港社会文化的理解能力,为多语言大模型在特定地域场景下的性能度量提供了重要标尺。
当前挑战
构建过程面临双重挑战:在领域问题层面,需克服香港地区双语混杂语境下的语义歧义,同时确保涵盖法律、文化等敏感领域的政治准确性;在技术实现层面,既要保持66个学科间知识体系的平衡性,又需解决粤语与普通话间方言转换的语义保真问题。数据采集过程中还涉及专业领域知识的权威性验证,以及多维度评估指标的系统性整合。
常用场景
经典使用场景
在语言模型评估领域,HKMMLU数据集作为综合性基准测试工具,其经典应用场景聚焦于多任务语言理解能力的系统性评测。该数据集通过涵盖STEM、社会科学、人文学科及其他领域的66个专业主题,结合粤语与普通话的翻译任务,构建了多维度的评估框架,为研究者在跨语言、跨文化语境下的模型表现提供了标准化测量工具。
实际应用
在实际应用层面,HKMMLU被广泛运用于智能教育系统的知识库构建、跨境法律咨询服务的语义理解优化,以及区域化内容生成模型的调优过程。其涵盖的香港中学文凭考试科目与专业领域知识,可直接支撑教育科技产品的内容质量评估,并为面向粤港澳大湾区的商业智能系统提供文化适配性验证。
衍生相关工作
基于该数据集衍生的经典研究包括多模态语言模型的区域知识对齐方法、跨语言语义表示的统一框架构建,以及针对粤语-普通话双语理解的注意力机制改进。这些工作通过利用数据集丰富的学科分类体系,推动了语言模型在特定文化语境下的认知深度与泛化能力的协同发展。
以上内容由遇见数据集搜集并总结生成


