LEGO-Puzzles
收藏github2025-04-09 更新2025-04-10 收录
下载链接:
https://github.com/Tangkexian/LEGO-Puzzles
下载链接
链接失效反馈官方服务:
资源简介:
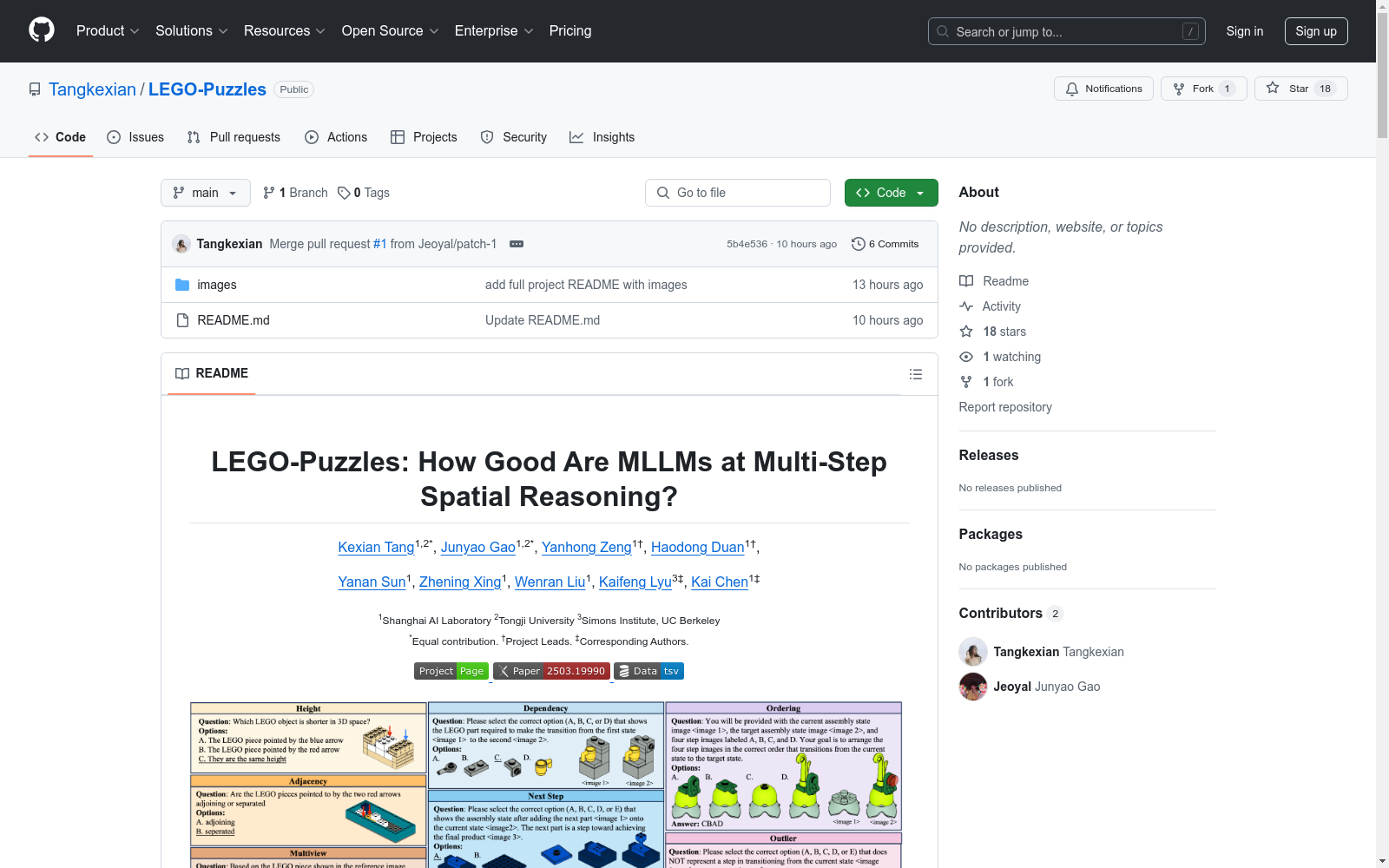
LEGO-Puzzles是一个可扩展且系统化的基准测试,旨在评估多模态大语言模型(MLLMs)在多步空间推理方面的能力。该数据集包含1,100个样本,涵盖空间理解、单步顺序推理和多步顺序推理三大任务类别。
LEGO-Puzzles is a scalable and systematic benchmark designed to evaluate the performance of multimodal large language models (MLLMs) in multi-step spatial reasoning. This dataset contains 1,100 samples, covering three task categories: spatial understanding, single-step sequential reasoning, and multi-step sequential reasoning.
创建时间:
2025-04-08
原始信息汇总
LEGO-Puzzles数据集概述
1. 数据集简介
- 名称: LEGO-Puzzles
- 目的: 评估多模态大语言模型(MLLMs)在多步空间推理任务中的表现
- 核心任务:
- 空间理解(Spatial Understanding)
- 单步序列推理(Single-Step Sequential Reasoning)
- 多步序列推理(Multi-Step Sequential Reasoning)
2. 数据集构成
- 总样本量: 1,100个
- 任务分布:
- 空间理解: 36.4%
- 单步序列推理: 36.4%
- 多步序列推理: 27.3%
- 子集:
- LEGO-Puzzles-Lite: 220个样本(用于人机对比)
3. 任务类型
- 主要形式:
- 视觉问答(VQA)
- 图像生成任务(5种)
- 评估维度:
- 外观相似性(Appearance Similarity)
- 指令遵循(Instruction Following)
4. 评估方法
- Next-k-Step基准:
- 测试模型预测k步后组装状态的能力
- 分析不同k值下的表现
- 包含思维链(CoT)提示的对比实验
5. 主要评估结果
- 测试模型: 20种前沿MLLM
- 表现最佳模型: GPT-4o和Gemini-2.0-Flash
- 人机对比:
- 人类标注者显著优于所有MLLM
- 特别是在3D空间对齐、旋转处理和多步组装跟踪任务中
6. 使用方式
-
集成框架: VLMEvalKit
-
评估命令: bash python run.py --data LEGO --model <your_model_name> --verbose
-
支持模式:
- 推理+评估
- 仅推理
- 多GPU加速
7. 相关资源
- 论文: arXiv:2503.19990
- 数据: HuggingFace数据集
- 项目页: LEGO-Puzzles官网
8. 引用格式
bibtex @article{tang2025lego, title={LEGO-Puzzles: How Good Are MLLMs at Multi-Step Spatial Reasoning?}, author={Tang, Kexian and Gao, Junyao and Zeng, Yanhong and Duan, Haodong and Sun, Yanan and Xing, Zhening and Liu, Wenran and Lyu, Kaifeng and Chen, Kai}, journal={arXiv preprint arXiv:2503.19990}, year={2025} }
搜集汇总
数据集介绍
构建方式
LEGO-Puzzles数据集通过精心设计的乐高组装任务,系统化评估多模态大语言模型的空间推理能力。研究团队构建了1100个样本,覆盖空间理解、单步顺序推理和多步顺序推理三大核心任务类别,每个任务均以视觉问答或图像生成形式呈现。数据采集过程严格模拟人类空间认知发展路径,通过乐高积木的真实配置实现可解释性评估,同时引入Next-k-Step细粒度测试框架以分析模型在递增复杂度下的推理能力。
特点
该数据集创新性地将空间推理分解为渐进式挑战,包含36.4%的空间理解任务、36.4%的单步推理任务及27.3%的多步推理任务。其独特价值在于融合传统视觉问答与图像生成评估,要求模型既能解析空间关系又能模拟结构转换。特别设计的LEGO-Puzzles-Lite子集实现了人机性能对标,而五类图像生成任务则开创性地测试了模型的空间状态预测能力,为多模态系统评估提供了多维度的测量标尺。
使用方法
研究者可通过VLMEvalKit框架快速部署评估流程,支持单命令启动模型测试。数据集已深度集成多GPU加速和API密钥管理功能,用户仅需配置环境变量即可评估包括GPT-4o在内的各类多模态模型。评估模式灵活可选,既支持完整的推理-评估流水线,也可单独执行推理阶段。开源工具链提供精确匹配和人工评判双轨评分机制,特别针对生成类任务设计了外观相似度和指令遵循度双重评估标准,确保评测结果的全面性与可靠性。
背景与挑战
背景概述
LEGO-Puzzles数据集由上海人工智能实验室与同济大学等机构的研究团队于2025年提出,旨在系统评估多模态大语言模型(MLLMs)在空间推理方面的能力。该数据集灵感来源于人类通过积木组装发展空间认知的过程,将空间理解转化为一系列乐高拼装任务,涵盖视觉感知与序列推理的双重挑战。作为首个专注于多步空间推理的基准测试,其核心研究问题聚焦于MLLMs在三维空间对齐、旋转处理和连续组装追踪等复杂场景下的表现。该数据集包含1,100个样本,划分为空间理解、单步序列推理和多步序列推理三大任务类别,并通过引入图像生成任务和Next-k-Step评估框架,为多模态系统的空间认知研究建立了标准化测试平台。
当前挑战
在领域问题层面,LEGO-Puzzles揭示了当前MLLMs面临的三重挑战:多步空间推理中三维几何关系的动态建模能力不足,序列决策时难以维持空间一致性,以及生成任务中结构合理性与指令遵循度的显著缺陷。构建过程中,研究团队需攻克跨模态对齐的标注难题,包括如何将抽象的空间变换转化为可量化的评估指标,以及设计兼顾物理合理性与认知复杂度的乐高组装序列。实验数据表明,即使是性能领先的GPT-4o模型,其在多步推理任务中的准确率仍较人类基准低37.2%,凸显了空间认知建模这一根本性技术瓶颈。
常用场景
经典使用场景
在人工智能领域,空间推理能力一直是多模态大语言模型(MLLMs)研究的核心挑战之一。LEGO-Puzzles数据集通过精心设计的乐高积木组装任务,为评估模型在空间理解、单步序列推理和多步序列推理等方面的能力提供了标准化测试平台。该数据集包含1100个样本,覆盖11种任务类型,广泛应用于模型在视觉问答和图像生成任务中的性能评估。
解决学术问题
LEGO-Puzzles数据集有效解决了多模态大语言模型在复杂空间推理任务中的评估难题。通过系统化的任务设计,该数据集能够精确测量模型在三维空间对齐、旋转处理和连续组装追踪等关键能力上的表现。实验数据表明,当前最先进的MLLMs在空间推理任务上仍显著落后于人类水平,这为改进模型架构和训练方法提供了明确方向。
衍生相关工作
围绕LEGO-Puzzles数据集已衍生出多项重要研究,包括Next-k-Step细粒度推理基准和LEGO-Puzzles-Lite精简子集。这些工作不仅扩展了原始数据集的应用维度,还催生了新型评估方法,如结合思维链(CoT)提示的多步推理评估框架,为后续研究提供了丰富的方法论参考。
以上内容由遇见数据集搜集并总结生成


