imagenet-1k-256
收藏Hugging Face2025-04-28 更新2025-04-29 收录
下载链接:
https://huggingface.co/datasets/pshishodia/imagenet-1k-256
下载链接
链接失效反馈官方服务:
资源简介:
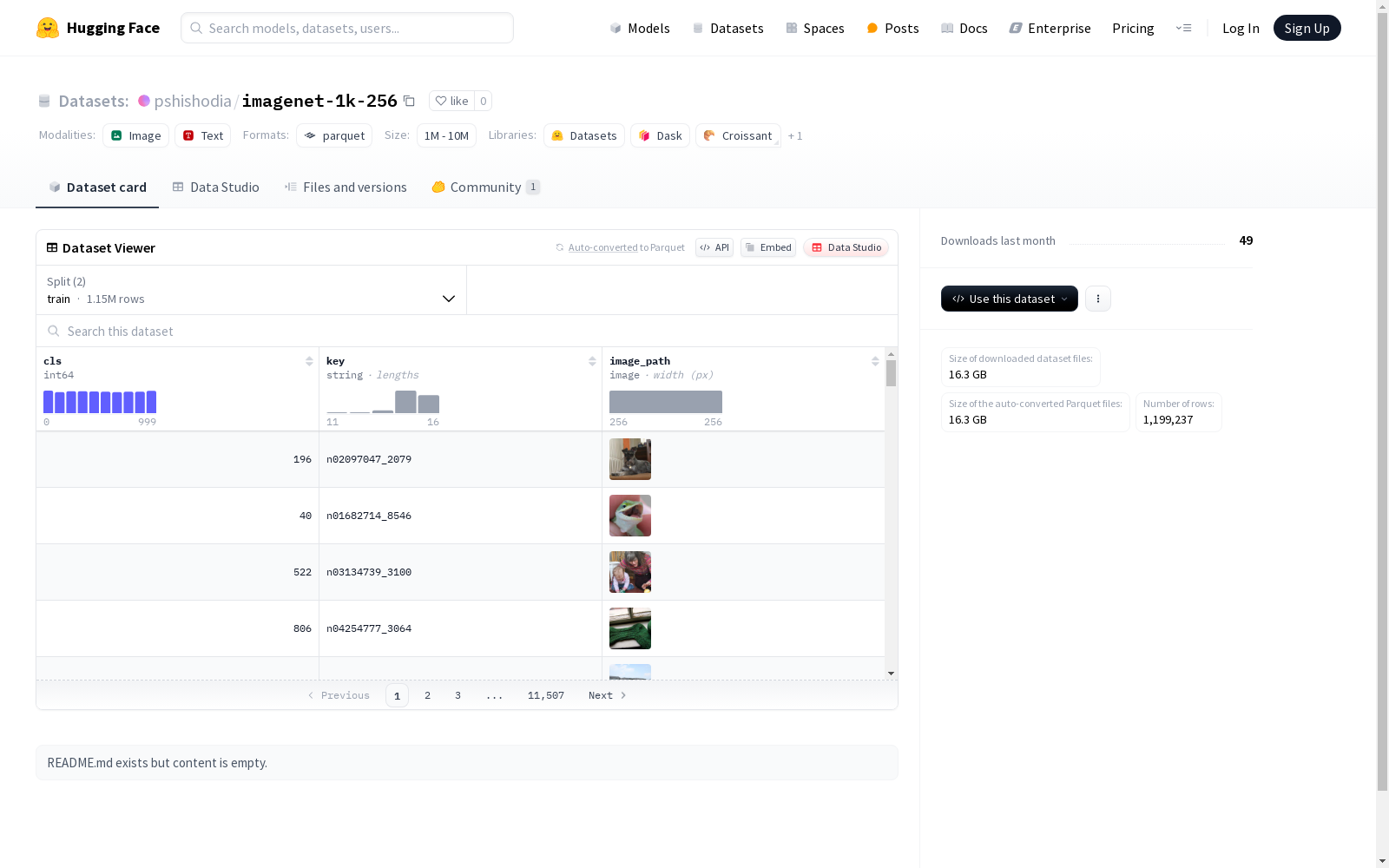
该数据集包含了分类标签(cls)、唯一标识符(key)和图片路径(image_path)三个字段。它被划分为训练集和验证集,适用于图像分类任务。训练集有1150610张图片,验证集有48627张图片。
This dataset contains three fields: classification label (cls), unique identifier (key), and image path (image_path). It is split into training and validation subsets, and is suitable for image classification tasks. The training set consists of 1,150,610 images, while the validation set includes 48,627 images.
创建时间:
2025-04-26
原始信息汇总
ImageNet-1K-256 数据集概述
数据集基本信息
- 数据集名称: ImageNet-1K-256
- 下载大小: 16,279,899,929 字节
- 数据集大小: 16,303,633,145.53 字节
数据集特征
- 特征字段:
cls: 数据类型为int64key: 数据类型为stringimage_path: 数据类型为image
数据集划分
- 训练集 (train):
- 样本数量: 1,150,610
- 数据大小: 15,639,991,874.53 字节
- 验证集 (validation):
- 样本数量: 48,627
- 数据大小: 663,641,271 字节
数据文件配置
- 默认配置 (default):
- 训练集路径:
data/train-* - 验证集路径:
data/validation-*
- 训练集路径:
搜集汇总
数据集介绍
构建方式
imagenet-1k-256数据集作为计算机视觉领域的经典基准,其构建过程体现了严谨的学术规范。该数据集基于ImageNet项目的原始图像数据,通过系统性的降采样处理将图像分辨率统一调整为256x256像素,既保留了足够的视觉信息又优化了计算效率。数据划分严格遵循原始ImageNet-1K的标准,包含115万训练样本和4.8万验证样本,每个样本均附带类别标签和唯一标识符,确保数据结构的完整性和可追溯性。
特点
该数据集最显著的特征在于其平衡的类别分布与标准化的图像规格。所有图像经过专业预处理后形成统一的RGB三通道格式,有效消除了原始数据中的分辨率差异问题。数据组织采用层次化结构,通过cls字段标注1000个细粒度类别,key字段提供唯一索引,image_path则指向标准化存储的图像文件。这种设计既支持大规模分布式训练,也便于进行跨模型的对比实验。
使用方法
使用imagenet-1k-256时,研究者可通过HuggingFace数据集库直接加载预处理好的数据分片。典型流程包括初始化数据集加载器、指定训练/验证划分,以及利用内置迭代器访问图像-标签对。图像数据以PIL格式提供,可直接输入主流深度学习框架的预处理管道。对于分布式训练场景,建议根据key字段实现确定性分片策略,确保实验的可重复性。验证集应严格用于模型评估,以维持学术研究的严谨规范。
背景与挑战
背景概述
ImageNet-1k-256数据集源自计算机视觉领域具有里程碑意义的ImageNet项目,由斯坦福大学李飞飞教授团队于2009年首次发布。作为ImageNet大规模视觉识别挑战赛(ILSVRC)的核心数据源,该数据集专注于解决图像分类与对象检测等基础视觉任务。其256像素版本通过标准化图像尺寸优化了计算效率,为深度卷积神经网络的发展提供了关键训练素材。数据集涵盖1000个物体类别,超过百万张标注图像,极大推动了深度学习模型在特征提取与迁移学习方面的突破。
当前挑战
该数据集面临的核心挑战在于细粒度分类的判别边界模糊问题,尤其对于外观相似的子类别(如不同犬种)存在标注歧义。构建过程中需克服大规模图像标注的精度控制难题,包括众包标注一致性校验与错误样本清洗。256像素下采样虽提升计算效率,却导致部分高频特征丢失,影响小尺度物体的识别性能。此外,数据分布偏斜问题显著,部分长尾类别样本不足,加剧了模型过拟合风险。
常用场景
经典使用场景
在计算机视觉领域,imagenet-1k-256数据集作为经典的图像分类基准数据集,被广泛用于评估深度学习模型的性能。该数据集包含1000个类别的图像,每个类别均有大量标注样本,为研究者提供了丰富的训练和验证数据。其256x256像素的分辨率设计,既保留了足够的视觉细节,又降低了计算复杂度,成为模型训练的理想选择。
实际应用
在实际应用中,imagenet-1k-256数据集训练的模型被广泛应用于智能安防、医疗影像分析、自动驾驶等场景。预训练在该数据集上的模型可作为特征提取器,迁移至下游任务,大幅降低特定领域的数据需求。工业界常利用该数据集进行模型性能基准测试,确保算法在实际部署中的可靠性。
衍生相关工作
围绕imagenet-1k-256数据集,学术界衍生出众多经典工作。AlexNet首次在该数据集上展现深度学习的潜力,ResNet通过残差连接解决了深层网络训练难题,Vision Transformer则开创了基于自注意力机制的图像分类新范式。这些工作不仅推动了计算机视觉的发展,也为其他领域的研究提供了重要借鉴。
以上内容由遇见数据集搜集并总结生成


