humanify/real_dia_dataset
收藏Hugging Face2026-04-11 更新2026-04-12 收录
下载链接:
https://hf-mirror.com/datasets/humanify/real_dia_dataset
下载链接
链接失效反馈官方服务:
资源简介:
---
dataset_info:
- config_name: CHiME6
features:
- name: session_id
dtype: string
- name: audio
dtype: audio
- name: targets
list:
list: int8
- name: speaker_ids
list: string
- name: duration
dtype: float64
- name: num_speakers
dtype: int32
- name: valid_offsets
list: float64
splits:
- name: train
num_bytes: 4695519672
num_examples: 16
download_size: 4728426870
dataset_size: 4695519672
- config_name: Dipco
features:
- name: session_id
dtype: string
- name: audio
dtype: audio
- name: targets
list:
list: int8
- name: speaker_ids
list: string
- name: duration
dtype: float64
- name: num_speakers
dtype: int32
- name: valid_offsets
list: float64
splits:
- name: train
num_bytes: 316726142
num_examples: 5
download_size: 318962486
dataset_size: 316726142
- config_name: Dipco_test
features:
- name: session_id
dtype: string
- name: audio
dtype: audio
- name: targets
list:
list: int8
- name: speaker_ids
list: string
- name: duration
dtype: float64
- name: num_speakers
dtype: int32
- name: valid_offsets
list: float64
splits:
- name: train
num_bytes: 301726535
num_examples: 5
download_size: 303858084
dataset_size: 301726535
- config_name: ICSI
features:
- name: session_id
dtype: string
- name: audio
dtype: audio
- name: targets
list:
list: int8
- name: speaker_ids
list: string
- name: duration
dtype: float64
- name: num_speakers
dtype: int32
- name: valid_offsets
list: float64
splits:
- name: train
num_bytes: 8326846018
num_examples: 75
download_size: 8439896806
dataset_size: 8326846018
- config_name: NOTSOFAR
features:
- name: session_id
dtype: string
- name: audio
dtype: audio
- name: targets
list:
list: int8
- name: speaker_ids
list: string
- name: duration
dtype: float64
- name: num_speakers
dtype: int32
- name: valid_offsets
list: float64
splits:
- name: train
num_bytes: 334050347
num_examples: 28
download_size: 336568165
dataset_size: 334050347
- config_name: aishell4
features:
- name: session_id
dtype: string
- name: audio
dtype: audio
- name: targets
list:
list: int8
- name: speaker_ids
list: string
- name: duration
dtype: float64
- name: num_speakers
dtype: int32
- name: valid_offsets
list: float64
splits:
- name: train
num_bytes: 99182770420
num_examples: 191
download_size: 99295119799
dataset_size: 99182770420
- config_name: aishell4_test
features:
- name: session_id
dtype: string
- name: audio
dtype: audio
- name: targets
list:
list: int8
- name: speaker_ids
list: string
- name: duration
dtype: float64
- name: num_speakers
dtype: int32
- name: valid_offsets
list: float64
splits:
- name: train
num_bytes: 11738893290
num_examples: 20
download_size: 11755959799
dataset_size: 11738893290
- config_name: aishell5
features:
- name: session_id
dtype: string
- name: audio
dtype: audio
- name: targets
list:
list: int8
- name: speaker_ids
list: string
- name: duration
dtype: float64
- name: num_speakers
dtype: int32
- name: valid_offsets
list: float64
splits:
- name: train
num_bytes: 12434302815
num_examples: 568
download_size: 12466722299
dataset_size: 12434302815
- config_name: alimeeting
features:
- name: session_id
dtype: string
- name: audio
dtype: audio
- name: targets
list:
list: int8
- name: speaker_ids
list: string
- name: duration
dtype: float64
- name: num_speakers
dtype: int32
- name: valid_offsets
list: float64
splits:
- name: train
num_bytes: 102700641574
num_examples: 209
download_size: 102767567345
dataset_size: 102700641574
- config_name: ami_ihm
features:
- name: session_id
dtype: string
- name: audio
dtype:
audio:
sampling_rate: 16000
- name: targets
list:
list: int8
- name: speaker_ids
list: string
- name: duration
dtype: float64
- name: num_speakers
dtype: int32
- name: valid_offsets
list: float64
splits:
- name: train
num_bytes: 9382939945
num_examples: 136
download_size: 9448752470
dataset_size: 9382939945
- config_name: ami_ihm_test
features:
- name: session_id
dtype: string
- name: audio
dtype:
audio:
sampling_rate: 16000
- name: targets
list:
list: int8
- name: speaker_ids
list: string
- name: duration
dtype: float64
- name: num_speakers
dtype: int32
- name: valid_offsets
list: float64
splits:
- name: train
num_bytes: 1050447703
num_examples: 16
download_size: 1057588350
dataset_size: 1050447703
- config_name: ami_sdm
features:
- name: session_id
dtype: string
- name: audio
dtype:
audio:
sampling_rate: 16000
- name: targets
list:
list: int8
- name: speaker_ids
list: string
- name: duration
dtype: float64
- name: num_speakers
dtype: int32
- name: valid_offsets
list: float64
splits:
- name: train
num_bytes: 9264815339
num_examples: 134
download_size: 9329797855
dataset_size: 9264815339
- config_name: ami_sdm_test
features:
- name: session_id
dtype: string
- name: audio
dtype:
audio:
sampling_rate: 16000
- name: targets
list:
list: int8
- name: speaker_ids
list: string
- name: duration
dtype: float64
- name: num_speakers
dtype: int32
- name: valid_offsets
list: float64
splits:
- name: train
num_bytes: 1050471619
num_examples: 16
download_size: 1057612366
dataset_size: 1050471619
- config_name: callhome
features:
- name: session_id
dtype: string
- name: audio
dtype: audio
- name: targets
list:
list: int8
- name: speaker_ids
list: string
- name: duration
dtype: float64
- name: num_speakers
dtype: int32
- name: valid_offsets
list: float64
splits:
- name: train
num_bytes: 4697040686
num_examples: 280
download_size: 4712743291
dataset_size: 4697040686
- config_name: msdwild
features:
- name: session_id
dtype: string
- name: audio
dtype: audio
- name: targets
list:
list: int8
- name: speaker_ids
list: string
- name: duration
dtype: float64
- name: num_speakers
dtype: int32
- name: valid_offsets
list: float64
splits:
- name: train
num_bytes: 5931033171
num_examples: 608
download_size: 5954296497
dataset_size: 5931033171
- config_name: voxconverse
features:
- name: session_id
dtype: string
- name: audio
dtype:
audio:
sampling_rate: 16000
- name: targets
list:
list: int8
- name: speaker_ids
list: string
- name: duration
dtype: float64
- name: num_speakers
dtype: int32
- name: valid_offsets
list: float64
splits:
- name: train
num_bytes: 2234495902
num_examples: 179
download_size: 2258083984
dataset_size: 2234495902
- config_name: voxconverse_test
features:
- name: session_id
dtype: string
- name: audio
dtype:
audio:
sampling_rate: 16000
- name: targets
list:
list: int8
- name: speaker_ids
list: string
- name: duration
dtype: float64
- name: num_speakers
dtype: int32
- name: valid_offsets
list: float64
splits:
- name: train
num_bytes: 4950892052
num_examples: 206
download_size: 5028729077
dataset_size: 4950892052
configs:
- config_name: CHiME6
data_files:
- split: train
path: CHiME6/train-*
- config_name: Dipco
data_files:
- split: train
path: Dipco/train-*
- config_name: Dipco_test
data_files:
- split: train
path: Dipco_test/train-*
- config_name: ICSI
data_files:
- split: train
path: ICSI/train-*
- config_name: NOTSOFAR
data_files:
- split: train
path: NOTSOFAR/train-*
- config_name: aishell4
data_files:
- split: train
path: aishell4/train-*
- config_name: aishell4_test
data_files:
- split: train
path: aishell4_test/train-*
- config_name: aishell5
data_files:
- split: train
path: aishell5/train-*
- config_name: alimeeting
data_files:
- split: train
path: alimeeting/train-*
- config_name: ami_ihm
data_files:
- split: train
path: ami_ihm/train-*
- config_name: ami_ihm_test
data_files:
- split: train
path: ami_ihm_test/train-*
- config_name: ami_sdm
data_files:
- split: train
path: ami_sdm/train-*
- config_name: ami_sdm_test
data_files:
- split: train
path: ami_sdm_test/train-*
- config_name: callhome
data_files:
- split: train
path: callhome/train-*
- config_name: msdwild
data_files:
- split: train
path: msdwild/train-*
- config_name: voxconverse
data_files:
- split: train
path: voxconverse/train-*
- config_name: voxconverse_test
data_files:
- split: train
path: voxconverse_test/train-*
---
数据集信息如下:
- 配置名称:CHiME6
特征字段:
- 会话ID(session_id):数据类型为字符串
- 音频(audio):音频数据类型
- 目标(targets):二维8位有符号整数列表
- 说话人ID(speaker_ids):字符串列表
- 时长(duration):数据类型为64位浮点数
- 说话人数量(num_speakers):数据类型为32位有符号整数
- 有效偏移量(valid_offsets):64位浮点数列表
划分集:
- 训练集:字节数为4695519672,样本数量为16
下载大小:4728426870,数据集总大小:4695519672
- 配置名称:Dipco
特征字段:
- 会话ID(session_id):数据类型为字符串
- 音频(audio):音频数据类型
- 目标(targets):二维8位有符号整数列表
- 说话人ID(speaker_ids):字符串列表
- 时长(duration):数据类型为64位浮点数
- 说话人数量(num_speakers):数据类型为32位有符号整数
- 有效偏移量(valid_offsets):64位浮点数列表
划分集:
- 训练集:字节数为316726142,样本数量为5
下载大小:318962486,数据集总大小:316726142
- 配置名称:Dipco_test
特征字段:
- 会话ID(session_id):数据类型为字符串
- 音频(audio):音频数据类型
- 目标(targets):二维8位有符号整数列表
- 说话人ID(speaker_ids):字符串列表
- 时长(duration):数据类型为64位浮点数
- 说话人数量(num_speakers):数据类型为32位有符号整数
- 有效偏移量(valid_offsets):64位浮点数列表
划分集:
- 训练集:字节数为301726535,样本数量为5
下载大小:303858084,数据集总大小:301726535
- 配置名称:ICSI
特征字段:
- 会话ID(session_id):数据类型为字符串
- 音频(audio):音频数据类型
- 目标(targets):二维8位有符号整数列表
- 说话人ID(speaker_ids):字符串列表
- 时长(duration):数据类型为64位浮点数
- 说话人数量(num_speakers):数据类型为32位有符号整数
- 有效偏移量(valid_offsets):64位浮点数列表
划分集:
- 训练集:字节数为8326846018,样本数量为75
下载大小:8439896806,数据集总大小:8326846018
- 配置名称:NOTSOFAR
特征字段:
- 会话ID(session_id):数据类型为字符串
- 音频(audio):音频数据类型
- 目标(targets):二维8位有符号整数列表
- 说话人ID(speaker_ids):字符串列表
- 时长(duration):数据类型为64位浮点数
- 说话人数量(num_speakers):数据类型为32位有符号整数
- 有效偏移量(valid_offsets):64位浮点数列表
划分集:
- 训练集:字节数为334050347,样本数量为28
下载大小:336568165,数据集总大小:334050347
- 配置名称:aishell4
特征字段:
- 会话ID(session_id):数据类型为字符串
- 音频(audio):音频数据类型
- 目标(targets):二维8位有符号整数列表
- 说话人ID(speaker_ids):字符串列表
- 时长(duration):数据类型为64位浮点数
- 说话人数量(num_speakers):数据类型为32位有符号整数
- 有效偏移量(valid_offsets):64位浮点数列表
划分集:
- 训练集:字节数为99182770420,样本数量为191
下载大小:99295119799,数据集总大小:99182770420
- 配置名称:aishell4_test
特征字段:
- 会话ID(session_id):数据类型为字符串
- 音频(audio):音频数据类型
- 目标(targets):二维8位有符号整数列表
- 说话人ID(speaker_ids):字符串列表
- 时长(duration):数据类型为64位浮点数
- 说话人数量(num_speakers):数据类型为32位有符号整数
- 有效偏移量(valid_offsets):64位浮点数列表
划分集:
- 训练集:字节数为11738893290,样本数量为20
下载大小:11755959799,数据集总大小:11738893290
- 配置名称:aishell5
特征字段:
- 会话ID(session_id):数据类型为字符串
- 音频(audio):音频数据类型
- 目标(targets):二维8位有符号整数列表
- 说话人ID(speaker_ids):字符串列表
- 时长(duration):数据类型为64位浮点数
- 说话人数量(num_speakers):数据类型为32位有符号整数
- 有效偏移量(valid_offsets):64位浮点数列表
划分集:
- 训练集:字节数为12434302815,样本数量为568
下载大小:12466722299,数据集总大小:12434302815
- 配置名称:alimeeting
特征字段:
- 会话ID(session_id):数据类型为字符串
- 音频(audio):音频数据类型
- 目标(targets):二维8位有符号整数列表
- 说话人ID(speaker_ids):字符串列表
- 时长(duration):数据类型为64位浮点数
- 说话人数量(num_speakers):数据类型为32位有符号整数
- 有效偏移量(valid_offsets):64位浮点数列表
划分集:
- 训练集:字节数为102700641574,样本数量为209
下载大小:102767567345,数据集总大小:102700641574
- 配置名称:ami_ihm
特征字段:
- 会话ID(session_id):数据类型为字符串
- 音频(audio):采样率为16000的音频数据类型
- 目标(targets):二维8位有符号整数列表
- 说话人ID(speaker_ids):字符串列表
- 时长(duration):数据类型为64位浮点数
- 说话人数量(num_speakers):数据类型为32位有符号整数
- 有效偏移量(valid_offsets):64位浮点数列表
划分集:
- 训练集:字节数为9382939945,样本数量为136
下载大小:9448752470,数据集总大小:9382939945
- 配置名称:ami_ihm_test
特征字段:
- 会话ID(session_id):数据类型为字符串
- 音频(audio):采样率为16000的音频数据类型
- 目标(targets):二维8位有符号整数列表
- 说话人ID(speaker_ids):字符串列表
- 时长(duration):数据类型为64位浮点数
- 说话人数量(num_speakers):数据类型为32位有符号整数
- 有效偏移量(valid_offsets):64位浮点数列表
划分集:
- 训练集:字节数为1050447703,样本数量为16
下载大小:1057588350,数据集总大小:1050447703
- 配置名称:ami_sdm
特征字段:
- 会话ID(session_id):数据类型为字符串
- 音频(audio):采样率为16000的音频数据类型
- 目标(targets):二维8位有符号整数列表
- 说话人ID(speaker_ids):字符串列表
- 时长(duration):数据类型为64位浮点数
- 说话人数量(num_speakers):数据类型为32位有符号整数
- 有效偏移量(valid_offsets):64位浮点数列表
划分集:
- 训练集:字节数为9264815339,样本数量为134
下载大小:9329797855,数据集总大小:9264815339
- 配置名称:ami_sdm_test
特征字段:
- 会话ID(session_id):数据类型为字符串
- 音频(audio):采样率为16000的音频数据类型
- 目标(targets):二维8位有符号整数列表
- 说话人ID(speaker_ids):字符串列表
- 时长(duration):数据类型为64位浮点数
- 说话人数量(num_speakers):数据类型为32位有符号整数
- 有效偏移量(valid_offsets):64位浮点数列表
划分集:
- 训练集:字节数为1050471619,样本数量为16
下载大小:1057612366,数据集总大小:1050471619
- 配置名称:callhome
特征字段:
- 会话ID(session_id):数据类型为字符串
- 音频(audio):音频数据类型
- 目标(targets):二维8位有符号整数列表
- 说话人ID(speaker_ids):字符串列表
- 时长(duration):数据类型为64位浮点数
- 说话人数量(num_speakers):数据类型为32位有符号整数
- 有效偏移量(valid_offsets):64位浮点数列表
划分集:
- 训练集:字节数为4697040686,样本数量为280
下载大小:4712743291,数据集总大小:4697040686
- 配置名称:msdwild
特征字段:
- 会话ID(session_id):数据类型为字符串
- 音频(audio):音频数据类型
- 目标(targets):二维8位有符号整数列表
- 说话人ID(speaker_ids):字符串列表
- 时长(duration):数据类型为64位浮点数
- 说话人数量(num_speakers):数据类型为32位有符号整数
- 有效偏移量(valid_offsets):64位浮点数列表
划分集:
- 训练集:字节数为5931033171,样本数量为608
下载大小:5954296497,数据集总大小:5931033171
- 配置名称:voxconverse
特征字段:
- 会话ID(session_id):数据类型为字符串
- 音频(audio):采样率为16000的音频数据类型
- 目标(targets):二维8位有符号整数列表
- 说话人ID(speaker_ids):字符串列表
- 时长(duration):数据类型为64位浮点数
- 说话人数量(num_speakers):数据类型为32位有符号整数
- 有效偏移量(valid_offsets):64位浮点数列表
划分集:
- 训练集:字节数为2234495902,样本数量为179
下载大小:2258083984,数据集总大小:2234495902
- 配置名称:voxconverse_test
特征字段:
- 会话ID(session_id):数据类型为字符串
- 音频(audio):采样率为16000的音频数据类型
- 目标(targets):二维8位有符号整数列表
- 说话人ID(speaker_ids):字符串列表
- 时长(duration):数据类型为64位浮点数
- 说话人数量(num_speakers):数据类型为32位有符号整数
- 有效偏移量(valid_offsets):64位浮点数列表
划分集:
- 训练集:字节数为4950892052,样本数量为206
下载大小:5028729077,数据集总大小:4950892052
数据集配置如下:
- 配置名称:CHiME6:数据文件划分训练集,路径为CHiME6/train-*
- 配置名称:Dipco:数据文件划分训练集,路径为Dipco/train-*
- 配置名称:Dipco_test:数据文件划分训练集,路径为Dipco_test/train-*
- 配置名称:ICSI:数据文件划分训练集,路径为ICSI/train-*
- 配置名称:NOTSOFAR:数据文件划分训练集,路径为NOTSOFAR/train-*
- 配置名称:aishell4:数据文件划分训练集,路径为aishell4/train-*
- 配置名称:aishell4_test:数据文件划分训练集,路径为aishell4_test/train-*
- 配置名称:aishell5:数据文件划分训练集,路径为aishell5/train-*
- 配置名称:alimeeting:数据文件划分训练集,路径为alimeeting/train-*
- 配置名称:ami_ihm:数据文件划分训练集,路径为ami_ihm/train-*
- 配置名称:ami_ihm_test:数据文件划分训练集,路径为ami_ihm_test/train-*
- 配置名称:ami_sdm:数据文件划分训练集,路径为ami_sdm/train-*
- 配置名称:ami_sdm_test:数据文件划分训练集,路径为ami_sdm_test/train-*
- 配置名称:callhome:数据文件划分训练集,路径为callhome/train-*
- 配置名称:msdwild:数据文件划分训练集,路径为msdwild/train-*
- 配置名称:voxconverse:数据文件划分训练集,路径为voxconverse/train-*
- 配置名称:voxconverse_test:数据文件划分训练集,路径为voxconverse_test/train-*
提供机构:
humanify
搜集汇总
数据集介绍
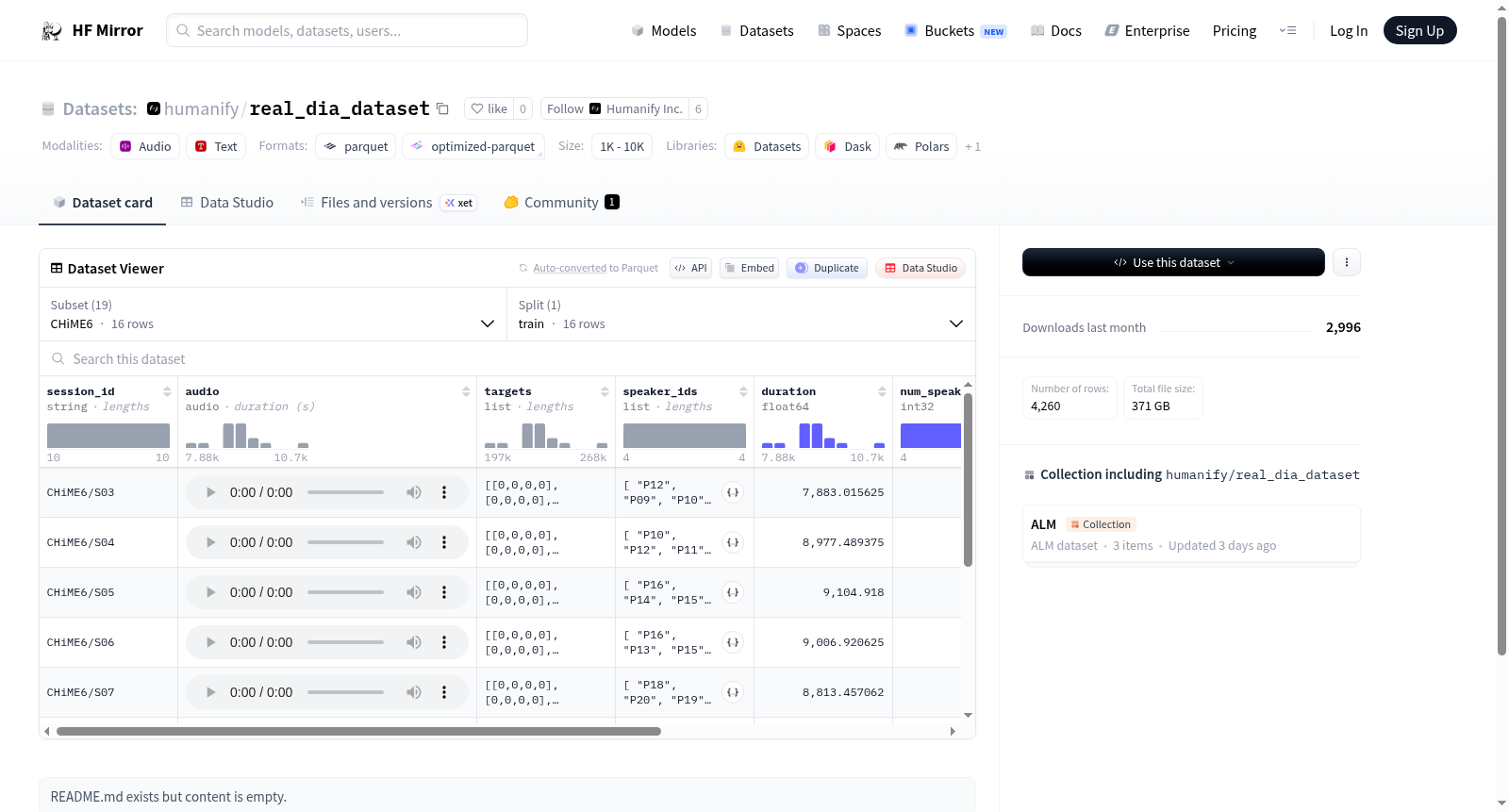
构建方式
在语音处理领域,real_dia_dataset的构建体现了对真实对话场景的深度整合。该数据集通过系统性地汇集多个知名子集,如CHiME6、ICSI、AISHELL等,涵盖了会议、电话、日常对话等多种语音交互环境。每个子集均经过标准化处理,统一了音频采样率、说话人标识及时间偏移等关键特征,确保了数据在格式上的一致性。构建过程中,原始音频数据被精确分割并标注了说话人活动的时间区间,形成了结构化的多说话人语音片段集合,为后续的模型训练提供了坚实的底层支持。
特点
real_dia_dataset的显著特点在于其广泛覆盖了多样化的真实世界对话场景,从嘈杂的会议环境到清晰的电话录音,均被纳入其中。数据集不仅提供了高质量的音频波形,还包含了精细的说话人身份标签、活动时间戳以及参与人数等元数据。这些特征使得该数据集能够有效模拟复杂的声学条件与说话人交互模式,为语音分离、说话人日志生成等任务提供了丰富的训练与评估素材。其大规模和多场景的特性,极大地促进了模型在现实应用中的泛化能力。
使用方法
针对语音分离与识别研究,real_dia_dataset的使用方法较为直观。研究人员可通过HuggingFace平台直接加载特定子集,如ami_ihm或voxconverse,获取包含音频、说话人标签及时间信息的结构化数据。在模型训练阶段,可以利用音频波形与对应的目标说话人活动矩阵进行监督学习,优化分离或检测性能。数据集支持灵活的分割与组合,允许用户根据实验需求定制训练集与测试集,从而在统一的框架下评估算法在不同声学环境下的表现。
背景与挑战
背景概述
real_dia_dataset 是一个专注于远场对话场景的音频数据集,由多个子集构成,涵盖了如 CHiME6、ICSI、AISHELL-4/5、AliMeeting 等知名会议与电话录音语料。该数据集由语音处理领域的研究机构与社区共同构建,旨在应对复杂声学环境下的说话人日志与语音识别任务。其核心研究问题在于解决多说话人重叠、背景噪声干扰以及远场录音条件下的语音分离与识别难题,对推动对话系统、智能助手及会议转录技术的发展具有深远影响。
当前挑战
该数据集所解决的领域挑战主要集中于远场多说话人语音处理,包括说话人日志中的重叠语音分割、噪声鲁棒性建模以及跨场景的泛化能力。构建过程中面临的挑战涉及多源数据的标准化整合,如不同采样率、录音设备与场景声学特性的统一;同时,高质量标注的获取成本高昂,需克服语音活动检测与说话人身份标注在复杂声学条件下的准确性难题,确保数据的一致性与可靠性。
常用场景
经典使用场景
在语音处理领域,real_dia_dataset作为多源真实对话音频的集合,其经典使用场景聚焦于说话人日志任务。该数据集整合了CHiME6、AMI、AISHELL等多个知名子集,涵盖了会议、电话、日常对话等多种真实环境录音,为研究者提供了丰富的多说话人音频样本。通过标注的说话人身份和时间戳信息,该数据集常用于训练和评估说话人分割与聚类算法,推动对话场景下说话人识别技术的发展。
衍生相关工作
围绕real_dia_dataset,衍生了一系列经典研究工作,例如端到端神经说话人日志系统的开发与优化。这些工作利用数据集的多样性子集,提出了基于深度聚类的说话人嵌入方法,以及结合语音分离的联合建模框架。部分研究进一步探索了少样本学习和跨域适应策略,以应对数据稀缺和领域差异挑战。这些成果不仅推动了说话人日志技术的理论突破,也为相关竞赛和工业应用提供了核心算法支撑。
数据集最近研究
最新研究方向
在远场语音处理领域,real_dia_dataset以其多场景、多语言的真实对话录音,成为声学建模与说话人日志研究的关键资源。当前前沿研究聚焦于利用该数据集探索端到端神经网络在复杂声学环境下的鲁棒性,特别是在多说话人重叠语音的分离与识别任务中。随着智能会议系统和远程协作工具的普及,该数据集支撑了基于深度学习的说话人角色识别和语音活动检测技术的突破,显著提升了自动语音识别系统在嘈杂环境下的性能。其整合的多个子集如CHiME6、AISHELL等,为跨领域迁移学习和模型泛化能力评估提供了标准化基准,推动了语音处理技术向更自然、更高效的人机交互方向发展。
以上内容由遇见数据集搜集并总结生成


