NORB 3D物体图像识别数据集
收藏帕依提提2024-03-04 收录
下载链接:
https://www.payititi.com/opendatasets/show-26417.html
下载链接
链接失效反馈官方服务:
资源简介:
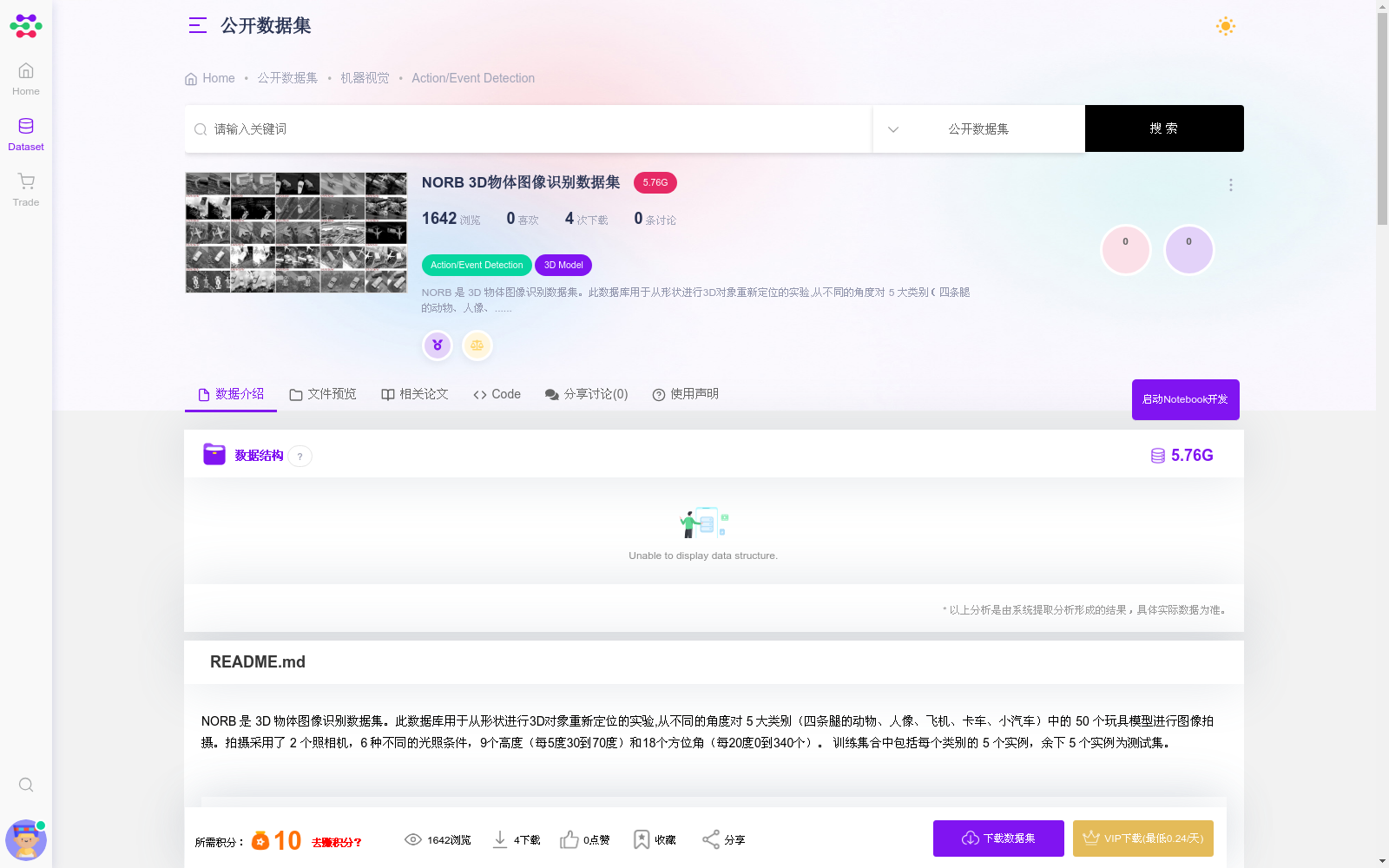
NORB 是 3D 物体图像识别数据集。此数据库用于从形状进行3D对象重新定位的实验,从不同的角度对 5 大类别(四条腿的动物、人像、飞机、卡车、小汽车)中的 50 个玩具模型进行图像拍摄。拍摄采用了 2 个照相机,6 种不同的光照条件,9个高度(每5度30到70度)和18个方位角(每20度0到340个)。 训练集合中包括每个类别的 5 个实例,余下 5 个实例为测试集。 gzip压缩文件以供下载。在未压缩之后,它们采用简单的二进制矩阵格式,文件后缀为“.mat”。文件格式将在后面的部分中介绍。 “-dat”文件存储图像序列。“-cat”文件存储相应的图像类别。每个“-dat”文件存储29,160个图像对(6个类别,5个实例,6个照明,9个高程和18个方位角)。第6类用于没有对象的图像,可用于训练系统拒绝图像,而不是5个对象类别。每个相应的“-cat”文件包含29,160个类别标签(动物为0,人为1,飞机为2,卡车为3,汽车为4,空白为5)。 每个“-info”文件存储29,160个10维向量,其包含关于相应图像的附加信息。向量中的前4个元素是: - 1.类别中的实例(0到9) - 2.高程(0到8,表示相机是30,35,40,45,50,55,60,分别距离水平65,70度) - 3.方位角(0,2,4,...,34,乘以10得到方位角度) - 4.照明条件(0到5) 和接下来的6个元素描述了当叠加到杂乱的背景上时添加到对象的扰动。(见下一节) 对于常规培训和测试,“-dat”和“-cat”文件就足够了。如果需要某些其他形式的分类或预处理,则提供“-info”文件。 捕获后,处理每个图像,使对象在图像中居中(对象像素的质心位于图像的中心),缩放使得边界框大约为80x80像素,并放置在制服上背景,包括投射阴影。 然后将3个变化源添加到数据集中: - 对象被攻击 - 对象叠加到复杂背景上 - 将distractor对象添加到背景中 物体以5种方式随机地被扰乱。它们按0.78到1.0之间的因子进行缩放; 面内旋转-5至+5度; 并在水平和垂直方向上移动-6到+6像素。图像强度(在0到255的范围内)是-20到+20之间的随机值; 图像对比度在0.8到1.3的范围内。这些扰动存储在“-info”文件的最后6个元素中: - 5.水平移位(-6到+6) - 6.垂直移位(-6到+6) - 7.亮度变化(-20到+20) - 8.对比度(0.8到1.3) - 9.对象比例(0.78到1.0) - 10.旋转(-5到+5度) 从Corel图像库的自然场景图像的子集中提取复杂背景图像。这些图像包含具有大区域对比度的场景,例如湖泊山脉和不规则区域边界。 每个图像都添加一个分心器对象。牵开器位于图像的边界,但可能使主要物体在中心变得杂乱。 有些图像只有背景和干扰物。这些图像属于他们自己的类别,如类别文件中所示。 文件以所谓的“二进制矩阵”文件格式存储,该文件格式是用于各种元素类型的向量和多维矩阵的简单格式。二进制矩阵文件以文件头开头,该文件头描述矩阵的类型和大小,然后是矩阵的二进制图像。 标题最好由C结构描述: struct header { int magic; // 4字节 int ndim; // 4个字节,小尾数 int dim [3]; }; 请注意,当矩阵的维度少于3维时,比如说它是1D向量,那么dim [1]和dim [2]都是1.当矩阵的维度超过3时,标题后面会跟着更大的维度信息。否则,在文件头到来之后,矩阵数据与最后一维中的索引一起存储的变化最快。 幻数编码矩阵的元素类型: -用于0x1E3D4C51单精度矩阵 - 0x1E3D4C52用于打包矩阵 - 0x1E3D4C53用于双精度矩阵 - 0x1E3D4C54为一个整数矩阵 - 0x1E3D4C55为字节矩阵 - 0x1E3D4C56一小段矩阵 由于文件是在Intel机器上生成的,因此它们使用little-endian方案对4字节整数进行编码。在使用big-endian的机器上读取文件时要特别注意。 - “-dat”文件存储尺寸为29160x2x108x108的4D张量。 - “-cat”文件存储尺寸为29,160的1D向量。 - “-info”文件存储尺寸为29160x10的2D矩阵。 这是一段Matlab代码,用于说明如何阅读一些示例文件。(为了避免endian混淆,我们读取标题的字节): >> fid = fopen('norb-5x46789x9x18x6x2x108x108-training-10-dat.mat','r'); >> fread(fid,4,'uchar'); %result = [85 76 61 30],它是一个字节矩阵 >> fread(fid,4,'uchar'); %result = [4 0 0 0],ndim = 4 >> fread(fid,4,'uchar'); %result = [232 113 0 0],dim0 = 29160(= 113 * 256 + 232) >> fread(fid,4,'uchar'); %result = [2 0 0 0],dim1 = 2 >> fread(fid,4,'uchar'); %result = [108 0 0 0],dim2 = 108 >> fread(fid,4,'uchar'); %result = [108 0 0 0],dim3 = 108 >> imshow(transpose(reshape(fread(108 * 108),108,108)),[0 255]); %显示第一张图片 >> fid = fopen('norb-5x46789x9x18x6x2x108x108-training-10-cat.mat','r'); >> fread(fid,4,'uchar'); %[84 76 61 30],整数矩阵 >> fread(fid,4,'uchar'); %[1 0 0 0] ndim = 1 >> fread(fid,4,'uchar'); %[232 113 0 0] dim0 = 29160(= 113 * 256 + 232) >> fread(fid,4,'uchar'); %[1 0 0 0](忽略这个) >> fread(fid,4,'uchar'); %[1 0 0 0](忽略这个) >> fread(fid,10,'int'); %[0 1 2 3 4 5 0 1 2 3](在小端CPU上) >> fid = fopen('norb-5x46789x9x18x6x2x108x108-training-10-info.mat','r'); >> fread(fid,4,'uchar'); %[84 76 61 30],整数矩阵 >> fread(fid,4,'uchar'); %[2 0 0 0] ndim = 2 >> fread(fid,4,'uchar'); %[232 113 0 0] dim0 = 29160(= 113 * 256 + 232) >> fread(fid,4,'uchar'); %[10 0 0 0] dim1 = 10 >> fread(fid,4,'uchar'); %[1 0 0 0](忽略这个) >> fread(fid,10,'int'); %[8 5 10 4 -3 0 -6 1 0 -4](在小端CPU上) 这是从“norb-5x46789x9x18x6x2x108x108-training-10-dat.mat”读取的前30个图像对的屏幕截图,排列自上而下和从左到右(列主要)。每对下面的标题显示相应“-cat.mat”和“-info.mat”文件中的内容。它们是“类别/实例/高程/方位角/照明”。对于背景图像,后面的4个数字都是-1。
NORB is a 3D object image recognition dataset. This database is used for experiments on 3D object re-localization from shape. Images were captured for 50 toy models across 5 major categories (four-legged animals, human figures, airplanes, trucks, cars) from different viewpoints. Two cameras were used, with 6 different lighting conditions, 9 elevation angles (30 to 70 degrees in 5-degree increments) and 18 azimuth angles (0 to 340 degrees in 20-degree increments). The training set includes 5 instances per category, while the remaining 5 instances form the test set. The datasets are provided as gzip-compressed files for download. After decompression, they use a simple binary matrix format with the file suffix ".mat". The file format is described in detail in the following sections.
The "-dat" files store image sequences. The "-cat" files store the corresponding image category labels. Each "-dat" file contains 29,160 image pairs (6 categories, 5 instances, 6 lighting conditions, 9 elevations and 18 azimuths). The 6th category corresponds to images without any objects, which can be used to train systems to reject non-object images instead of the 5 object categories. Each corresponding "-cat" file contains 29,160 category labels (0 for animal, 1 for human, 2 for airplane, 3 for truck, 4 for car, 5 for background/empty).
Each "-info" file stores 29,160 10-dimensional vectors containing additional information about the corresponding images. The first 4 elements of each vector are:
1. Instance index within the category (0 to 9)
2. Elevation index (0 to 8, corresponding to camera elevations of 30, 35, 40, 45, 50, 55, 60, 65, 70 degrees relative to the horizontal plane)
3. Azimuth index (0, 2, 4, ..., 34, multiplied by 10 to get the actual azimuth angle)
4. Lighting condition index (0 to 5)
The remaining 6 elements describe perturbations applied to the object when it is overlaid on a cluttered background (see the next section).
For standard training and testing, the "-dat" and "-cat" files are sufficient. The "-info" files are provided if other forms of classification or preprocessing are required.
After capture, each image is processed such that the object is centered in the image (the centroid of the object's pixels is located at the image center), scaled so that the bounding box is approximately 80x80 pixels, and placed on a uniform background including cast shadows. Three sources of variation are then added to the dataset:
- The object is perturbed
- The object is overlaid onto a complex background
- Distractor objects are added to the background
Objects are randomly perturbed in 5 ways: they are scaled by a factor between 0.78 and 1.0; rotated in-plane by -5 to +5 degrees; and shifted horizontally and vertically by -6 to +6 pixels. Image intensity (in the range 0 to 255) is adjusted by a random value between -20 and +20; image contrast is adjusted to a range of 0.8 to 1.3. These perturbations are stored in the last 6 elements of the "-info" file:
5. Horizontal shift (-6 to +6)
6. Vertical shift (-6 to +6)
7. Brightness variation (-20 to +20)
8. Contrast (0.8 to 1.3)
9. Object scale (0.78 to 1.0)
10. Rotation (-5 to +5 degrees)
Complex background images are extracted from a subset of natural scene images from the Corel Image Library. These images contain scenes with large-area contrasts, such as lakes, mountains and irregular region boundaries. Each image has one distractor object added. Distractors are placed near the image boundaries, but may clutter the central area where the main object is located. Some images contain only background and distractors; these belong to their own category as indicated in the category files.
The files are stored in the so-called "binary matrix" file format, a simple format for vectors and multi-dimensional matrices of various element types. A binary matrix file starts with a file header that describes the matrix type and size, followed by the binary matrix data. The header is best described by a C structure:
c
struct header {
int magic; // 4 bytes
int ndim; // 4 bytes, little-endian
int dim[3];
};
Note that when the matrix has fewer than 3 dimensions, e.g., a 1D vector, then dim[1] and dim[2] are both 1. When the matrix has more than 3 dimensions, additional dimension information follows the header. Otherwise, after the header, the matrix data is stored with the index in the last dimension changing the fastest.
The magic number encodes the element type of the matrix:
- 0x1E3D4C51 for single-precision matrices
- 0x1E3D4C52 for packed matrices
- 0x1E3D4C53 for double-precision matrices
- 0x1E3D4C54 for integer matrices
- 0x1E3D4C55 for byte matrices
- 0x1E3D4C56 for short matrices
Since the files were generated on Intel machines, they use the little-endian scheme to encode 4-byte integers. Special care must be taken when reading the files on machines using big-endian.
The "-dat" files store a 4D tensor of size 29160x2x108x108. The "-cat" files store a 1D vector of size 29,160. The "-info" files store a 2D matrix of size 29160x10.
Here is a sample Matlab code illustrating how to read some example files (to avoid endianness confusion, we read the header bytes):
matlab
>> fid = fopen('norb-5x46789x9x18x6x2x108x108-training-10-dat.mat', 'r');
>> fread(fid, 4, 'uchar'); % result = [85 76 61 30], which is a byte matrix
>> fread(fid, 4, 'uchar'); % result = [4 0 0 0], ndim = 4
>> fread(fid, 4, 'uchar'); % result = [232 113 0 0], dim0 = 29160 (= 113 * 256 + 232)
>> fread(fid, 4, 'uchar'); % result = [2 0 0 0], dim1 = 2
>> fread(fid, 4, 'uchar'); % result = [108 0 0 0], dim2 = 108
>> fread(fid, 4, 'uchar'); % result = [108 0 0 0], dim3 = 108
>> imshow(transpose(reshape(fread(108 * 108), 108, 108)), [0 255]); % Display the first image
>> fid = fopen('norb-5x46789x9x18x6x2x108x108-training-10-cat.mat', 'r');
>> fread(fid, 4, 'uchar'); % [84 76 61 30], integer matrix
>> fread(fid, 4, 'uchar'); % [1 0 0 0] ndim = 1
>> fread(fid, 4, 'uchar'); % [232 113 0 0] dim0 = 29160 (= 113 * 256 + 232)
>> fread(fid, 4, 'uchar'); % [1 0 0 0] (ignore this)
>> fread(fid, 4, 'uchar'); % [1 0 0 0] (ignore this)
>> fread(fid, 10, 'int'); % [0 1 2 3 4 5 0 1 2 3] (on little-endian CPUs)
>> fid = fopen('norb-5x46789x9x18x6x2x108x108-training-10-info.mat', 'r');
>> fread(fid, 4, 'uchar'); % [84 76 61 30], integer matrix
>> fread(fid, 4, 'uchar'); % [2 0 0 0] ndim = 2
>> fread(fid, 4, 'uchar'); % [232 113 0 0] dim0 = 29160 (= 113 * 256 + 232)
>> fread(fid, 4, 'uchar'); % [10 0 0 0] dim1 = 10
>> fread(fid, 4, 'uchar'); % [1 0 0 0] (ignore this)
>> fread(fid, 10, 'int'); % [8 5 10 4 -3 0 -6 1 0 -4] (on little-endian CPUs)
This is a screenshot of the first 30 image pairs read from "norb-5x46789x9x18x6x2x108x108-training-10-dat.mat", arranged top-to-bottom and left-to-right (column-major order). The caption below each pair shows the content from the corresponding "-cat.mat" and "-info.mat" files. They are formatted as "category/instance/elevation/azimuth/lighting". For background images, the last four numbers are all -1.
提供机构:
帕依提提
搜集汇总
数据集介绍
背景与挑战
背景概述
NORB 3D物体图像识别数据集包含5大类别(四条腿的动物、人像、飞机、卡车、小汽车)的50个玩具模型图像,拍摄条件包括6种光照、9个高度和18个方位角。数据集分为训练集和测试集,适用于3D对象重新定位和图像识别研究。
以上内容由遇见数据集搜集并总结生成


