3hr_myanmar_asr_raw_audio
收藏Hugging Face2025-06-05 更新2025-06-06 收录
下载链接:
https://huggingface.co/datasets/freococo/3hr_myanmar_asr_raw_audio
下载链接
链接失效反馈官方服务:
资源简介:
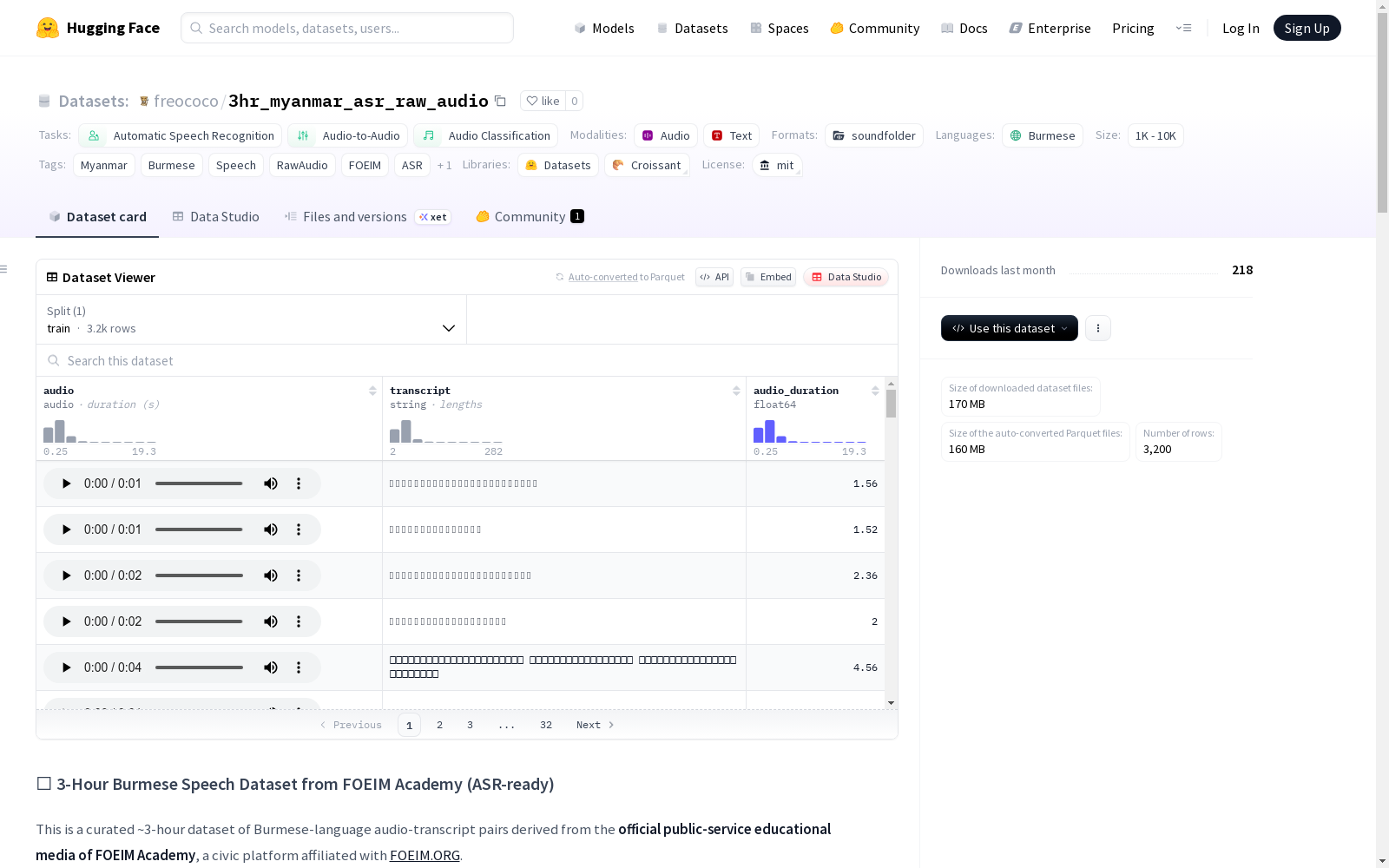
这是一个大约3小时的缅甸语语音-文本对数据集,来源于FOEIM学院的官方公共服务教育媒体。数据集经过精心策划,适用于细粒度的自动语音识别(ASR)训练和测试。所有数据都是从时间戳字幕文件(.srt)对齐并分割成高质量的单声道.mp3文件,并附带对齐的文本。数据集包含3200个缅甸语口语片段,总时长约2.90小时,片段长度从0.25秒到19.34秒不等。数据已经过清理、对齐和标准化,适合用于语音模型。文本来自公共.srt字幕,讲者口音在整个数据集中保持一致。
This is a roughly 3-hour Burmese speech-text paired dataset sourced from the official public service educational media of FOEIM Institute. It has been meticulously curated for fine-grained automatic speech recognition (ASR) training and testing. All data is aligned and segmented from timestamped subtitle files (.srt) into high-quality monaural .mp3 files, paired with aligned transcriptions. The dataset contains 3200 Burmese speech segments, with a total duration of approximately 2.90 hours, and the length of each segment ranges from 0.25 seconds to 19.34 seconds. The data has been cleaned, aligned and standardized, making it suitable for speech models. The transcriptions are derived from public .srt subtitles, and the speaker's accent remains consistent across the entire dataset.
创建时间:
2025-06-05
原始信息汇总
📚 3-Hour缅甸语语音数据集概述
基本信息
- 名称: 3-Hour Burmese Speech Dataset from FOEIM Academy (ASR-ready)
- 许可证: MIT
- 语言: 缅甸语 (my)
- 作者: freococo
- 来源: FOEIM.ORG 官方公共服务教育媒体
- 任务类别: 自动语音识别(ASR)、音频到音频、音频分类
数据集亮点
- 数据量: 3,200个缅甸语语音片段
- 总时长: 约2.90小时
- 片段长度: 0.25秒至19.34秒
- 特点: 干净、对齐、标准化,适用于语音模型
- 转录来源: 直接从公开的.srt字幕文件中提取
- 说话者: 统一口音,保证一致性
数据格式
- metadata.csv包含以下列:
file_name: 音频文件相对路径(如audio/audio_20250605_0123.mp3)transcript: Unicode缅甸语转录文本audio_duration: 音频时长(秒,浮点数)
数据集统计
- 总文件数: 3,200
- 总时长: 2.90小时
- 平均片段长度: 3.26秒
- 最短片段: 0.25秒
- 最长片段: 19.34秒
独特之处
- 来源独特: 来自公共教育语音资源
- 语言特点: 干净的缅甸语发音,极少代码转换
- 内容重点: 公民教育、历史、伦理和公民意识
使用示例
python from datasets import load_dataset, Audio
ds = load_dataset("freococo/3hr_myanmar_asr_raw_audio") ds = ds.cast_column("file_name", Audio()) print(ds[0])
引用格式
@dataset{freococo_myanmar_asr_2025_foeim, title = {3-Hour Burmese ASR Dataset (FOEIM)}, author = {freococo}, year = {2025}, url = {https://huggingface.co/datasets/freococo/3hr_myanmar_asr_raw_audio}, note = {Curated from FOEIM Academy public videos. Licensed under MIT.} }
许可证与致谢
- 许可证: MIT
- 致谢: FOEIM.ORG及其教育者、制作人和演讲者
搜集汇总
数据集介绍
构建方式
该数据集源自FOEIM Academy的公共服务教育媒体内容,通过系统化处理时间戳字幕文件(.srt)构建而成。音频数据被精确分割为时长0.25至19.34秒的片段,转换为高质量的MP3单声道格式,并与转录文本实现严格对齐。整个过程注重数据清洁与标准化,确保语音与文本的高度一致性。
特点
数据集包含3,200个缅甸语语音片段,总时长约2.90小时,平均片段长度为3.26秒。其独特之处在于全部语音均来自公共教育领域,发音清晰且方言统一,极少出现语码转换现象。内容聚焦公民教育、历史与伦理领域,区别于常见的宗教或议会语音数据集,具有显著的领域特异性。
使用方法
用户可通过Hugging Face的datasets库直接加载数据集,使用Audio处理器自动解析音频列。该数据集适用于缅甸语自动语音识别模型的训练与测试,尤其适合短语音段识别任务。其标准化格式支持端到端的模型训练流程,也可用于语音翻译或音素级分析研究。
背景与挑战
背景概述
缅甸语自动语音识别研究长期面临数据资源匮乏的困境,特别是在教育领域的高质量语音语料尤为稀缺。2025年,由FOEIM Academy联合研究者freococo共同构建的3小时缅甸语语音数据集应运而生,该数据集源自该机构公开教育媒体的字幕对齐音频,包含3,200条经过严格校验的语音-文本对,总时长约2.90小时。该数据集不仅填补了缅甸教育领域语音数据的空白,更为低资源语言的自动语音识别技术发展提供了重要支撑,对推动缅甸语自然语言处理研究具有显著意义。
当前挑战
本数据集致力于解决缅甸语自动语音识别模型训练中面临的数据稀缺性问题,其核心挑战在于低资源语言的语音数据采集与标准化处理。构建过程中需克服多重困难:首先需从连续教育视频中精确提取时间戳对齐的音频片段,确保语音与字幕的毫秒级同步;其次要处理缅甸语特有的 Unicode 文本规范化问题,消除方言变体和代码转换现象;最后还需保持语音样本在说话人、录音环境和内容主题方面的一致性,以构建适用于教育场景的高质量语音语料库。
常用场景
经典使用场景
在缅甸语自动语音识别研究中,该数据集作为高质量训练语料,广泛应用于端到端语音识别模型的构建与优化。其经过严格对齐的音频-文本对特别适合训练基于CTC或Attention机制的声学模型,研究者可通过fine-tuning方式快速构建缅甸语语音识别系统,显著提升低资源语言场景下的识别准确率。
衍生相关工作
基于该数据集衍生的经典工作包括缅甸语端到端语音识别系统Burmese-Whisper的开发,以及跨语言语音表示学习模型SEW的缅甸语适配研究。这些工作显著推动了缅甸语语音技术社区的发展,为后续研究者提供了可复现的基准模型和标准化评估流程。
数据集最近研究
最新研究方向
在低资源语言语音技术领域,缅甸语自动语音识别研究正面临数据稀缺的挑战。该数据集以其纯净的公民教育语音内容和标准发音特性,为端到端语音模型优化提供了高质量训练样本。当前研究聚焦于利用此类领域特定数据提升方言适应性模型性能,同时探索多模态教育内容生成技术在公民教育场景的应用。该数据集的发布恰逢缅甸数字遗产保护倡议兴起,为语言技术赋能社会教育提供了重要基础设施,推动了东南亚低资源语言技术研究的创新发展。
以上内容由遇见数据集搜集并总结生成


