windtunnel-20k
收藏Hugging Face2024-09-30 更新2024-12-12 收录
下载链接:
https://huggingface.co/datasets/inductiva/windtunnel-20k
下载链接
链接失效反馈官方服务:
资源简介:
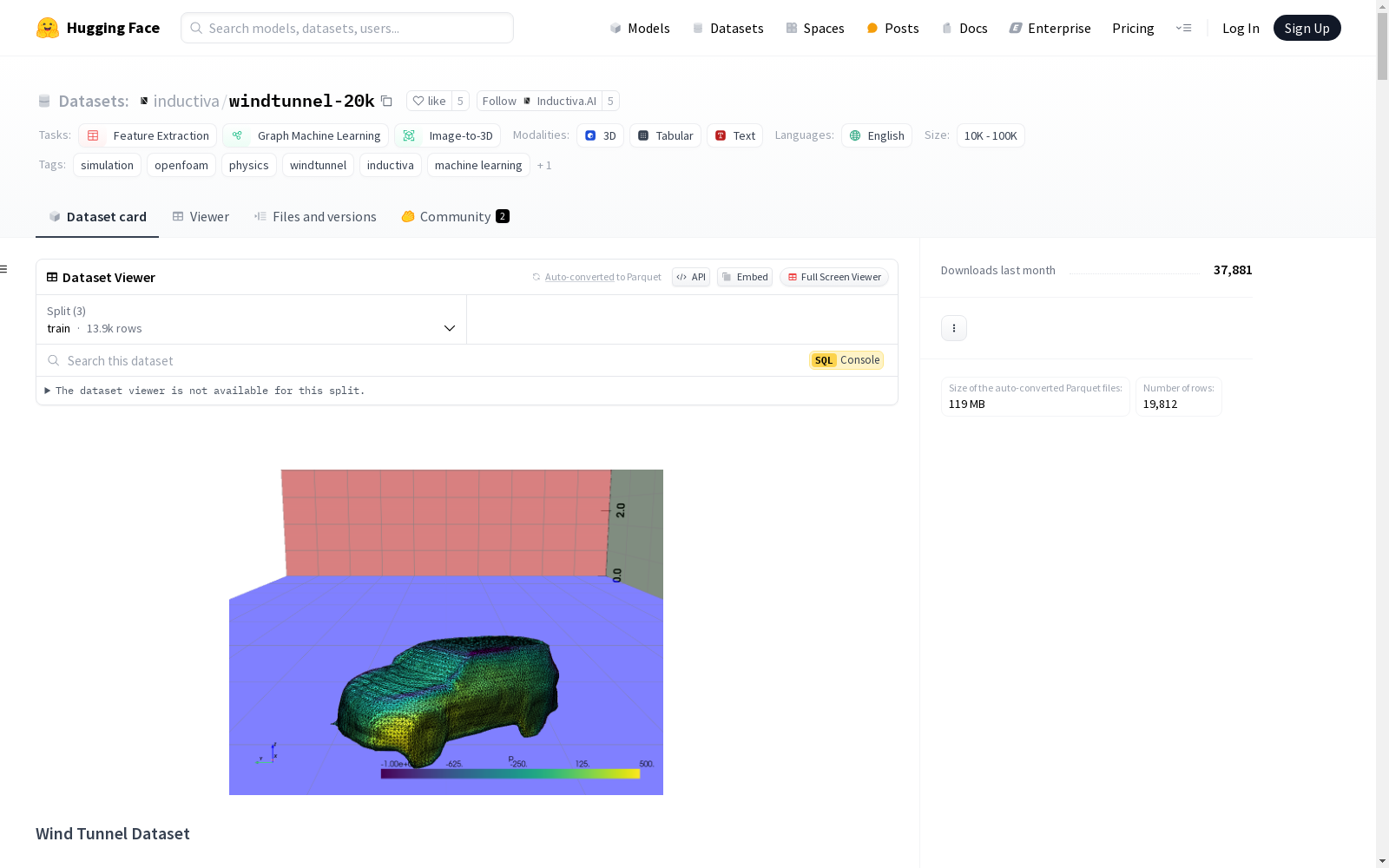
风洞20K数据集包含20,000个在虚拟风洞中放置的1,000个独特类汽车物体的OpenFOAM模拟。每个物体在20种不同条件下进行模拟,包括4种随机风速和5种旋转角度。每个模拟运行300次迭代以确保稳定结果。数据集分为三个子集:70%用于训练,20%用于验证,10%用于测试。物体网格使用Instant Mesh模型生成,并从斯坦福汽车数据集中获取。数据集包括输入网格、OpenFOAM网格、压力场数据、流线以及元数据。该数据集适用于特征提取、图机器学习和图像到3D转换等任务。
The Wind Tunnel 20K Dataset consists of 20,000 OpenFOAM simulations of 1,000 unique car-class objects placed in a virtual wind tunnel. Each object is simulated under 20 distinct conditions, including 4 random wind speeds and 5 rotation angles. Each simulation runs for 300 iterations to ensure stable results. The dataset is split into three subsets: 70% for training, 20% for validation, and 10% for testing. Object meshes are generated using the Instant Mesh model and sourced from the Stanford Car Dataset. The dataset includes input meshes, OpenFOAM meshes, pressure field data, streamlines, and metadata. This dataset is applicable to tasks such as feature extraction, graph machine learning, and image-to-3D conversion.
创建时间:
2024-09-26
原始信息汇总
Wind Tunnel 20K Dataset
概述
- 名称: Wind Tunnel 20K Dataset
- 大小: 10K<n<100K
- 任务类别:
- 特征提取
- 图机器学习
- 图像到3D
- 语言: 英语
- 标签:
- 模拟
- OpenFOAM
- 物理
- 风洞
- Inductiva
- 机器学习
- 合成
数据集描述
- 包含: 19,812个OpenFOAM模拟,涉及1,000个独特的汽车类物体在虚拟风洞中的模拟。
- 模拟条件: 每个物体在20种不同条件下进行模拟,包括4种随机风速(10到50 m/s)和5种旋转角度(0°、180°和3个随机角度)。
- 网格生成: 使用Instant Mesh模型从Stanford Cars Dataset的图像生成汽车类物体的网格。
- 模拟迭代: 每个模拟运行300次迭代以确保稳定和可靠的结果。
- 数据集划分: 数据集分为训练集(70%)、验证集(20%)和测试集(10%)。
数据生成过程
- 生成输入网格: 使用Instant Mesh模型从Stanford Cars Dataset生成输入网格,并进行后处理。
- 运行OpenFOAM模拟: 使用Inductiva API在云上并行运行OpenFOAM模拟。
- 后处理OpenFOAM输出: 生成流线和压力场网格。
数据集结构
data ├── train │ ├── <SIMULATION_ID> │ │ ├── input_mesh.obj │ │ ├── openfoam_mesh.obj │ │ ├── pressure_field_mesh.vtk │ │ ├── simulation_metadata.json │ │ └── streamlines_mesh.ply │ └── ... ├── validation │ └── ... └── test └── ...
数据文件
- input_mesh.obj: 使用InstantMesh模型生成的输入网格。
- openfoam_mesh.obj: OpenFOAM模拟生成的输出网格。
- pressure_field_mesh.vtk: 包含压力场数据的VTK文件。
- streamlines_mesh.ply: 包含流线的PLY文件。
- metadata.json: 包含模拟的输入参数和输出结果的元数据。
数据集统计
- 有效样本: 19,812个有效样本。
- 失败样本: 188个模拟因数值错误失败。
- 存储需求: 约300 GB。
下载数据集
-
安装Datasets包: python pip install datasets
-
使用snapshot_download(): python import huggingface_hub dataset_name = "inductiva/windtunnel-20k" huggingface_hub.snapshot_download(repo_id=dataset_name, repo_type="dataset")
-
使用load_dataset(): python import datasets dataset = datasets.load_dataset("inductiva/windtunnel-20k", streaming=False) print(dataset)
OpenFOAM参数
- 配置文件: 使用Inductiva Template Manager参数化OpenFOAM配置文件。
- 配置文件位置: https://github.com/inductiva/wind-tunnel/tree/main/windtunnel/templates
搜集汇总
数据集介绍
构建方式
Wind Tunnel 20K数据集的构建过程基于虚拟风洞环境下的汽车空气动力学模拟。首先,通过Instant Mesh模型从Stanford Cars数据集的图像中生成1000个汽车样式的3D网格。随后,利用OpenFOAM软件在虚拟风洞中对这些网格进行模拟,模拟条件包括4种风速和5种旋转角度,每种组合运行300次迭代以确保结果的稳定性。整个模拟过程通过Inductiva API在云端并行执行,最终生成了19,812个有效模拟样本。数据集按70%训练、20%验证和10%测试的比例划分。
特点
Wind Tunnel 20K数据集的特点在于其规模化和多样性。数据集包含19,812个OpenFOAM模拟结果,覆盖了1000个独特的汽车样式网格,每个网格在20种不同条件下进行测试。模拟结果包括压力场、流线图等丰富的物理场数据,并以OBJ、VTK和PLY格式存储。此外,数据集中的网格经过后处理,保留了部分缺陷,如不对称性和孔洞,这些特征有助于机器学习模型的鲁棒性训练。数据集的总存储需求约为300GB,支持按需下载部分数据。
使用方法
Wind Tunnel 20K数据集的使用方法灵活多样。用户可以通过Hugging Face的Datasets包下载完整数据集或特定部分。数据集支持流式加载,便于处理大规模数据。每个模拟样本包含输入网格、OpenFOAM输出网格、压力场数据、流线图以及元数据文件。元数据文件记录了模拟的输入参数(如风速、旋转角度)和输出结果(如阻力系数、升力系数)。用户可以利用这些数据进行机器学习模型的训练、验证和测试,特别是在空气动力学预测和物理场重建任务中。
背景与挑战
背景概述
Wind Tunnel 20K数据集由Inductiva团队于近年创建,旨在填补计算流体力学(CFD)与机器学习(ML)交叉领域的数据空白。该数据集包含19,812个基于OpenFOAM的虚拟风洞模拟,涵盖了1,000个独特的汽车状物体在不同风速和旋转角度下的流体动力学行为。通过利用斯坦福汽车数据集中的图像生成3D网格,并结合OpenFOAM进行大规模模拟,该数据集为研究人员提供了一个高质量的基准,用于训练和验证基于机器学习的CFD模型。其核心研究问题在于如何通过机器学习加速CFD模拟,同时保持与传统方法相当的精度。该数据集对CFD和ML社区的研究具有重要推动作用,尤其是在虚拟风洞场景下的流体动力学预测方面。
当前挑战
Wind Tunnel 20K数据集的构建面临多重挑战。首先,生成高质量的3D网格是CFD模拟的基础,但现有公开数据集在网格质量和多样性方面存在显著不足。尽管采用了先进的图像到网格生成模型(如InstantMesh),生成的网格仍存在不规则表面、孔洞和不对称等缺陷,需通过后处理优化。其次,大规模CFD模拟的计算资源需求极高,单次模拟的复杂性和时间成本使得生成数万次模拟的数据集极具挑战性。Inductiva团队通过云平台和并行计算技术解决了这一问题,但仍需处理模拟失败和数据存储等实际问题。此外,如何确保模拟结果的物理准确性和数据多样性,以支持机器学习模型的泛化能力,也是该数据集构建中的关键挑战。
常用场景
经典使用场景
Wind Tunnel 20K数据集在计算流体动力学(CFD)领域具有广泛的应用,尤其是在虚拟风洞实验中模拟汽车空气动力学特性。该数据集通过OpenFOAM模拟生成,涵盖了19,812次仿真,涉及1,000个独特的汽车模型在不同风速和旋转角度下的表现。研究人员可以利用该数据集训练机器学习模型,以预测空气动力学性能,从而加速传统CFD仿真的计算过程。
实际应用
在实际应用中,Wind Tunnel 20K数据集为汽车设计、航空航天工程以及风力发电等领域提供了重要的参考数据。工程师可以利用该数据集优化车辆外形设计,减少空气阻力,提升燃油效率。同时,该数据集还可用于开发更高效的机器学习模型,以替代传统CFD仿真,降低计算成本和时间。
衍生相关工作
Wind Tunnel 20K数据集的发布推动了多个相关领域的研究进展。基于该数据集,研究人员开发了多种机器学习模型,用于预测空气动力学性能。此外,该数据集还促进了图像到3D网格生成技术的发展,如InstantMesh模型的应用。这些衍生工作不仅扩展了数据集的应用范围,也为未来的CFD与机器学习结合研究提供了新的方向。
以上内容由遇见数据集搜集并总结生成


