sts-all-nli-darija
收藏Hugging Face2025-11-15 更新2025-11-16 收录
下载链接:
https://huggingface.co/datasets/KBayoud/sts-all-nli-darija
下载链接
链接失效反馈官方服务:
资源简介:
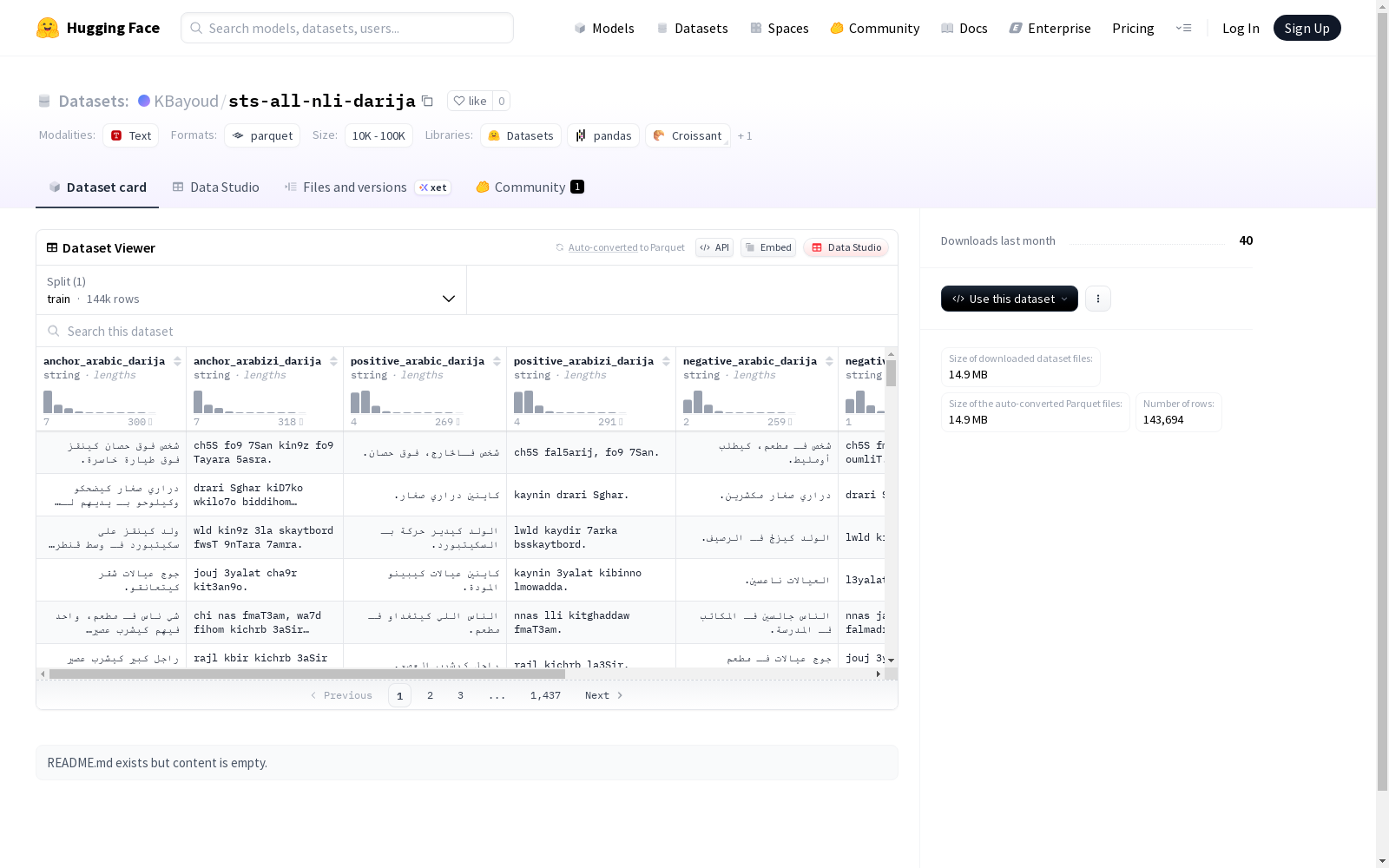
该数据集包含了阿拉伯语方言Darija和Arabizi以及通用阿拉伯语的正例、负例和锚点文本。数据集被划分为训练集,其中包含了129,939个示例,总大小为69,352,573字节。
This dataset contains positive, negative, and anchor texts in Darija (a dialectal Arabic variety), Arabizi, and Standard Arabic. It is split into a training set, which includes 129,939 instances with a total size of 69,352,573 bytes.
创建时间:
2025-11-13
原始信息汇总
STS-All-NLI-Darija 数据集概述
数据集基本信息
- 数据集名称: STS-All-NLI-Darija
- 存储位置: https://huggingface.co/datasets/KBayoud/sts-all-nli-darija
- 数据格式: 结构化文本数据
- 总样本数: 129,939
- 数据集大小: 69,352,573 字节
- 下载大小: 12,717,046 字节
数据特征结构
数据集包含以下文本字段:
阿拉伯语达里贾方言版本
- anchor_arabic_darija
- positive_arabic_darija
- negative_arabic_darija
阿拉伯字母音译版本
- anchor_arabizi_darija
- positive_arabizi_darija
- negative_arabizi_darija
标准文本版本
- anchor
- positive
- negative
数据划分
- 唯一划分: train
- 训练集样本数: 129,939
- 训练集文件路径: data/train-*
数据类型
所有特征字段均为字符串类型(string)
搜集汇总
数据集介绍
构建方式
在摩洛哥阿拉伯语自然语言处理研究领域,sts-all-nli-darija数据集通过精心设计的对比学习框架构建而成。该数据集以语义文本相似性任务为基础,采用三元组结构组织语料,每个样本包含锚点文本、正例文本和负例文本的平行对照。原始数据经过多阶段处理,分别生成标准阿拉伯语变体和阿拉伯字母转写变体,形成六种平行文本字段,最终构建包含近13万组训练样本的大规模语料库。
特点
该数据集最显著的特征在于其多模态语言表达形式,同时呈现摩洛哥阿拉伯语的标准阿拉伯语书写和阿拉伯字母转写两种表征方式。数据集通过锚点-正例-负例的三元组结构,构建了丰富的语义对比关系,为语义相似度计算提供多维度监督信号。其平行文本设计使得模型能够学习不同书写系统之间的语义对应关系,为低资源语言处理任务提供了独特的跨表征学习机会。
使用方法
研究人员可将该数据集直接应用于摩洛哥阿拉伯语的语义相似度计算和对比学习任务。使用时应同时考虑两种书写变体的特征提取,通过锚点与正负例的语义关系构建训练目标。典型应用场景包括训练双语语义编码器、开发跨书写系统的语义匹配模型,以及作为预训练语料提升模型对摩洛哥阿拉伯语的语言理解能力。数据加载可通过标准数据集接口实现,支持批量处理和分布式训练。
背景与挑战
背景概述
在自然语言处理领域,低资源语言的语义理解一直面临严峻挑战。sts-all-nli-darija数据集聚焦于摩洛哥达里贾方言的语义相似度计算与自然语言推理任务,该方言作为阿拉伯语的口语变体长期缺乏标准化文本资源。数据集通过构建包含阿拉伯文字与阿拉伯字母转写文本的平行语料,填补了达里贾方言在语义表示研究中的空白,为跨语言模型迁移学习提供了重要支撑。
当前挑战
达里贾方言的语料构建面临双重挑战:其口语化特性导致文字转写存在拼写变异,同时阿拉伯字母转写体系缺乏统一标准加剧了数据噪声。在语义任务层面,方言与标准阿拉伯语间的语法差异使得传统语义相似度算法难以直接迁移,而低资源特性又限制了深度学习模型的表征能力。此外,数据集中锚点句与正负例的语义关联需要人工标注者具备方言与文化背景知识,进一步增加了标注复杂度。
常用场景
经典使用场景
在摩洛哥阿拉伯语自然语言处理研究中,该数据集通过锚定句与正负例句的对比结构,为语义文本相似度任务提供了标准评估框架。其独特的阿拉伯语与阿拉伯字母转写双版本设计,使研究者能够系统分析方言文本在不同表征形式下的语义一致性,成为跨语言表示学习领域的经典基准工具。
实际应用
在摩洛哥地区的智能客服与社交媒体分析系统中,该数据集支撑的语义模型能准确理解方言用户的真实意图。医疗健康领域的问诊平台借助其训练的相似度检测模块,可自动匹配方言症状描述与标准医学术语,有效改善了非阿拉伯语母语患者的医疗服务可及性。
衍生相关工作
基于该数据集衍生的DarijaBERT预训练模型开创了摩洛哥方言深度表征的先河,后续研究则拓展出多模态方言理解框架。其数据构造范式更启发了突尼斯方言、阿尔及利亚方言等马格里布地区语言资源的建设,形成了以对比学习为核心的方言处理技术体系。
以上内容由遇见数据集搜集并总结生成


