WebGuard
收藏Hugging Face2025-07-24 更新2025-07-25 收录
下载链接:
https://huggingface.co/datasets/osunlp/WebGuard
下载链接
链接失效反馈官方服务:
资源简介:
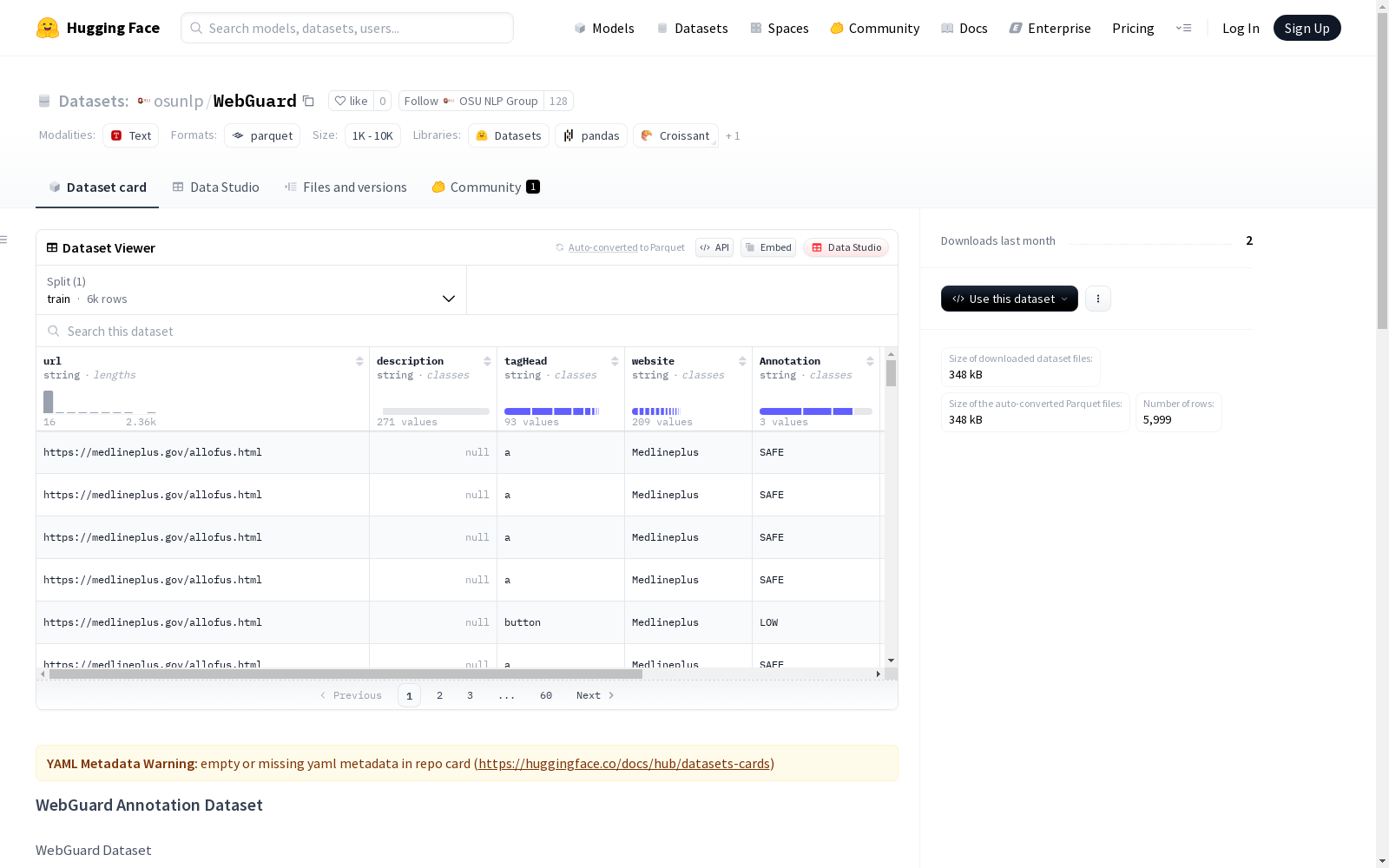
WebGuard注释数据集是一个包含浏览器交互安全注释的数据集,共5,999条记录。每条记录包含URL、动作描述(可能为空)、目标元素的HTML标签类型、截图链接、审查分类(安全/不安全/低风险/高风险)以及网站名称或类别。
The WebGuard Annotation Dataset is a dataset containing browser interaction security annotations, with a total of 5,999 records. Each record includes the URL, action description (which may be empty), the HTML tag type of the target element, screenshot link, review classification (safe/unsafe/low-risk/high-risk), and the website name or category.
提供机构:
OSU NLP Group
创建时间:
2025-07-24
原始信息汇总
WebGuard Annotation Dataset 概述
数据集基本信息
- 名称: WebGuard Annotation Dataset
- 内容: 包含浏览器交互的网页安全标注
- 数据量: 5,999条网页安全标注
- 年份: 2024
- 许可证: Unknown
数据字段说明
url: 执行操作的URLdescription: 操作描述(可能为空)tagHead: 目标元素的HTML标签类型Screenshot: 截图视图的Google Drive链接Annotation: 审核分类(SAFE/UNSAFE/LOW/HIGH)website: 网站名称/类别
使用方式
python from datasets import load_dataset
加载数据集
dataset = load_dataset("osunlp/WebGuard")
访问数据
for example in dataset["train"]: print(f"URL: {example[url]}") print(f"Description: {example[description]}") print(f"Tag: {example[tagHead]}") print(f"Screenshot: {example[Screenshot]}") print(f"Annotation: {example[Annotation]}") print(f"Website: {example[website]}") print("---")
引用信息
bibtex @dataset{webguard_annotations, title={WebGuard Web Safety Annotations}, year={2024}, note={Web safety annotation dataset for browser interactions} }
搜集汇总
数据集介绍
构建方式
WebGuard数据集通过系统化采集浏览器交互行为构建而成,聚焦于网络行为安全评估领域。研究团队对5,999个网页交互动作进行多维度标注,包括URL地址、操作描述、HTML元素类型等结构化字段,并辅以截图可视化证据。每个条目均经过专业安全评级,形成SAFE/UNSAFE/LOW/HIGH四级风险标注体系,确保数据构建过程兼具技术严谨性和安全评估专业性。
使用方法
研究者可通过HuggingFace数据集库便捷加载WebGuard数据集,标准化的字段结构便于快速开展模型训练。典型使用流程包括:初始化加载数据集后,可遍历访问每个样本的URL、操作描述、HTML标签等关键字段;截图链接为可视化分析提供便利;风险标注字段可直接作为监督信号训练分类模型。该数据结构设计尤其适合端到端的网络安全风险评估模型开发,支持从基础特征提取到多模态融合等多种技术路线。
背景与挑战
背景概述
WebGuard数据集由OSUNLP研究团队于2024年发布,专注于网络浏览安全领域的研究。该数据集收录了5,999条网页交互行为的安全标注数据,通过系统化地标注URL、HTML元素类型、行为描述及风险等级,为浏览器安全防护机制的研究提供了重要基准。其创新性在于首次将网页交互行为细分为SAFE/UNSAFE/LOW/HIGH四级风险体系,填补了传统二分类标注在风险梯度刻画上的不足。该数据集的建立显著推动了人机交互安全、恶意网页检测等领域的研究进展,为构建下一代智能网页风险预警系统奠定了数据基础。
当前挑战
该数据集面临的核心挑战体现在两个维度:在领域问题层面,网页交互行为具有高度动态性和上下文依赖性,单一静态标注难以全面反映实际风险场景,特别是对于基于JavaScript的复杂交互行为;同时,风险等级的边界定义存在主观性,不同标注者可能对相同交互行为产生分歧性判断。在构建过程层面,主要挑战来自大规模网页截图数据的存储与标注效率问题,Google Drive链接存储方式存在长期可访问性风险;此外,HTML标签的多样性导致tagHead字段存在语义鸿沟,简单标签类型难以充分表征元素的行为风险特征。
常用场景
经典使用场景
WebGuard数据集作为网络行为安全分析的重要资源,广泛应用于浏览器交互风险评估领域。该数据集通过标注网页操作行为的风险等级(SAFE/UNSAFE/LOW/HIGH),为研究者提供了分析恶意网页特征的基础数据。在网络安全研究中,学者们常利用该数据集训练机器学习模型,以识别钓鱼网站、恶意脚本注入等网络威胁。
解决学术问题
该数据集有效解决了网络行为安全评估中缺乏标准化标注数据的难题。通过提供近6000条包含URL、HTML标签、操作描述及风险标注的完整记录,研究者能够系统性地分析危险网页的共性特征。这在提升自动化风险检测模型的准确率、探索新型网络攻击模式等学术问题上具有重要价值,推动了人机交互安全领域的方法论创新。
实际应用
在实际应用中,WebGuard数据集被集成到浏览器安全插件和网络监控系统中。安全厂商利用其训练的风险分类模型,能够实时预警用户访问高风险网页的操作。教育机构则基于该数据集开发网络安全培训系统,通过标注案例直观展示危险网页的识别特征,显著提升了普通用户的网络风险防范意识。
数据集最近研究
最新研究方向
随着网络安全隐患日益复杂化,WebGuard数据集为浏览器交互安全研究提供了重要基准。当前研究聚焦于利用多模态学习框架,结合网页截图视觉特征与HTML结构标签,构建端到端的风险预测模型。在人工智能安全领域,该数据集正被用于探索基于注意力机制的异常行为检测算法,以识别钓鱼网站和恶意脚本注入等新型威胁。近期研究趋势表明,学者们尝试将时序建模技术应用于连续浏览行为的风险评估,通过分析用户操作序列中的潜在风险模式,提升对渐进式网络攻击的预警能力。
以上内容由遇见数据集搜集并总结生成


