pxhere
收藏Hugging Face2025-05-24 更新2025-05-25 收录
下载链接:
https://huggingface.co/datasets/nyuuzyou/pxhere
下载链接
链接失效反馈官方服务:
资源简介:
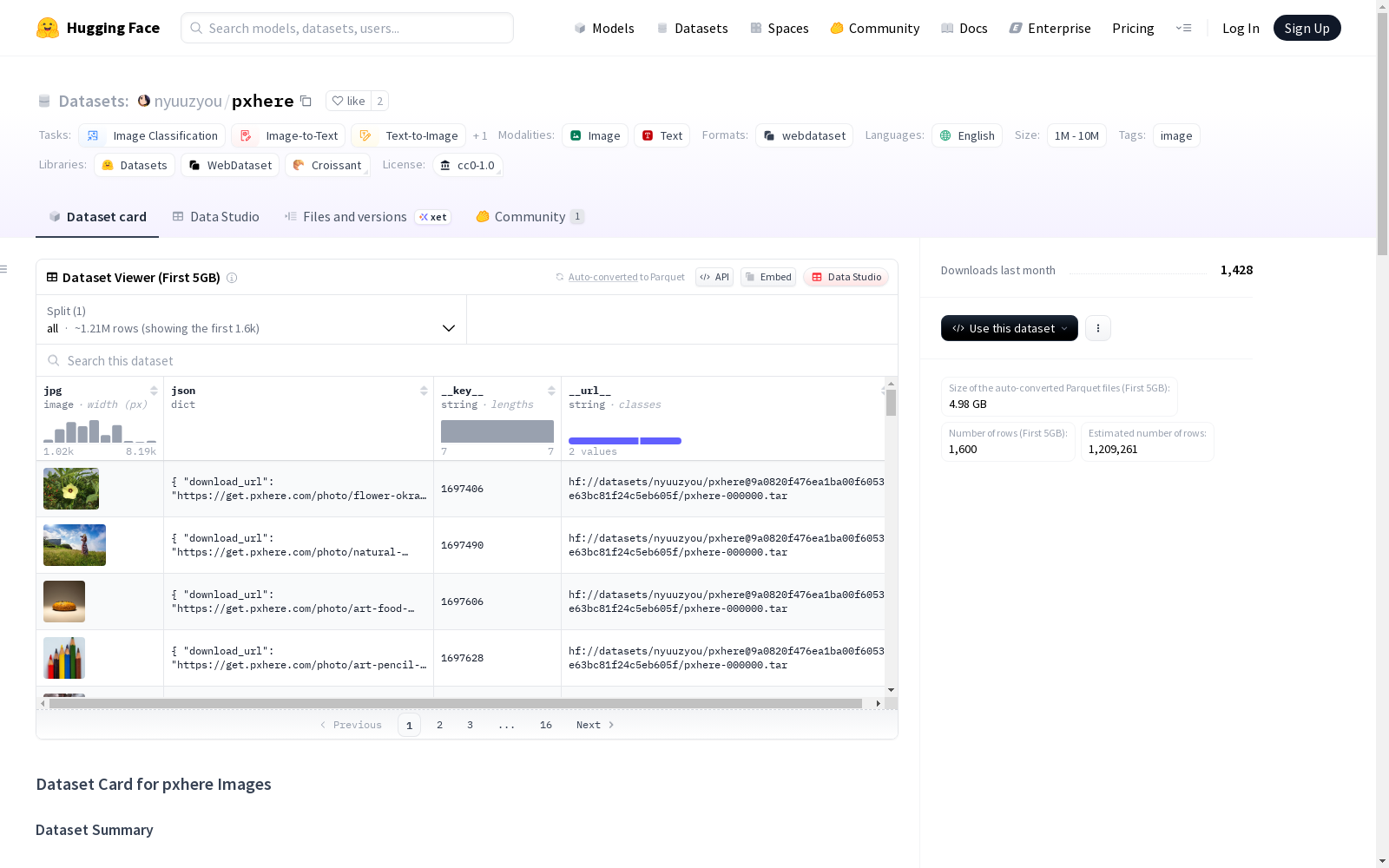
PxHere Images 数据集是一个包含约110万张高分辨率照片的大型集合,这些照片来源于pxhere.com,一个免费的股票照片网站。照片内容覆盖自然、人物、城市环境、物体、动物和风景等多个主题。所有图片都遵循Creative Commons Zero (CC0)许可,可以免费用于个人和商业用途,无需署名。该数据集以WebDataset格式组织,适合大规模的机器学习应用,如图像分类、图像到文本生成和计算机视觉研究。
The PxHere Images Dataset is a large collection of approximately 1.1 million high-resolution photos sourced from pxhere.com, a free stock photo website. The content of these photos covers multiple themes including nature, people, urban environments, objects, animals, landscapes and more. All images are licensed under Creative Commons Zero (CC0), permitting free personal and commercial use without attribution requirements. This dataset is organized in WebDataset format, which is suitable for large-scale machine learning applications such as image classification, image-to-text generation and computer vision research.
创建时间:
2025-05-14
原始信息汇总
数据集概述:PxHere Images
数据集摘要
- 来源:pxhere.com(免费图库网站)
- 内容:约1,100,000张高质量摄影作品
- 分辨率:原始全分辨率
- 主题范围:自然、人物、城市环境、物体、动物、景观等
- 格式:WebDataset格式(
.tar文件) - 授权:CC0 1.0(可自由用于个人和商业用途)
语言信息
- 主要语言:英语(en)
- 图像标题和标签主要为英文
数据集结构
数据文件
- 文件数量:761个归档文件
- 文件命名:
pxhere-000000.tar至pxhere-001100.tar - 每个归档包含:约1,000张图像及对应JSON元数据
数据字段(JSON元数据)
image_id:PxHere.com上的唯一标识符(作为文件名)download_url:原始下载URLtags:图像相关标签数组uploaded:上传日期(MM/DD/YYYY格式)exif_info:包含原始照片的EXIF元数据(如可用)camera_model:相机型号resolution:图像尺寸(宽×高,像素)aperture:光圈值focal_length:焦距shutter_speed:曝光时间iso:ISO感光度lens_details_raw:镜头和曝光详情组合
数据划分
| 划分 | 样本数量 |
|---|---|
train |
≈1,100,000 |
数据格式
- 图像格式:原始格式(主要为JPEG)
- 命名规则:使用
image_id作为文件名 - 元数据:与图像同名的JSON文件
- 打包方式:WebDataset格式(tar归档),每归档约1,000张图像
授权信息
- 授权类型:Creative Commons Zero (CC0) 1.0
- 授权条款:
- 无需署名
- 允许个人和商业用途
- 允许修改和再分发
- 无使用限制或费用
- 详细授权信息:https://creativecommons.org/publicdomain/zero/1.0/
搜集汇总
数据集介绍
构建方式
pxhere数据集构建于免费图库网站PxHere.com的海量高质量摄影作品,采用系统化采集策略确保数据多样性。原始图像通过自动化爬取流程获取,保留完整的元数据信息,包括拍摄参数、标签体系及上传日期等关键属性。数据以WebDataset格式组织,将约110万张图像划分为761个压缩档案,每个档案包含约1000张全分辨率图片及对应的JSON格式元数据文件,这种结构设计显著提升了大规模机器学习任务的加载效率。
特点
该数据集最显著的特征在于其全面覆盖自然景观、城市风貌、人物肖像等多元主题,所有图像均采用CC0许可协议,免除商业使用的版权顾虑。技术层面,每张图像附带详尽的EXIF元数据,包含相机型号、光圈焦距等专业摄影参数,为计算机视觉研究提供丰富特征维度。数据组织形式采用高效的WebDataset架构,支持流式读取,特别适合处理超百万量级的图像分析任务。
使用方法
研究者可通过解压WebDataset格式的压缩包直接获取图像序列,配套的JSON元数据文件包含结构化标签信息,便于构建图像分类或跨模态学习任务。由于采用标准tar归档格式,该数据集兼容PyTorch的WebDataset加载器,能够实现高效的数据流式处理。针对不同分辨率需求,用户可依据EXIF中的原始尺寸信息进行筛选,而丰富的标签体系为监督学习提供了多角度的标注维度。
背景与挑战
背景概述
PxHere图像数据集作为一项重要的计算机视觉资源,由PxHere.com这一免费图库平台于近年构建并公开发布。该数据集汇集了约110万张高分辨率摄影作品,涵盖自然景观、人文环境、静物特写等多重主题,为图像分类、文本生成及跨模态学习研究提供了丰富的素材基础。所有图像均遵循CC0许可协议,确保了学术与商业应用的广泛自由度。数据集采用WebDataset格式组织,显著提升了大规模机器学习任务中数据加载与处理的效率,对推动开放数据生态和视觉智能发展具有重要价值。
当前挑战
构建PxHere数据集面临多重技术挑战:跨模态任务中图像与文本标签的语义对齐需要解决标注噪声问题,部分用户生成的标签存在歧义或冗余;海量高分辨率图像的存储与分布式处理对计算架构提出苛刻要求,原始EXIF元数据的异构性增加了特征提取复杂度。领域应用层面,数据分布的长尾现象导致细粒度分类性能受限,且CC0协议虽保障法律合规性,但需防范潜在的内容偏见风险。这些挑战共同构成了该数据集在质量优化与实用化进程中的关键瓶颈。
常用场景
经典使用场景
在计算机视觉领域,pxhere数据集凭借其百万级高质量图像资源,成为图像分类任务的重要基准。研究人员利用其丰富的场景类别和精细标注的标签体系,构建了涵盖自然景观、城市建筑、动植物等多维度的分类模型。该数据集特别适合训练深度卷积神经网络,其图像分辨率保持原始尺寸,为模型提供了丰富的视觉细节特征。
衍生相关工作
基于pxhere数据集衍生的经典研究包括多标签图像分类框架ML-GCN,该工作利用图卷积网络建模标签相关性。在跨模态领域,研究者构建了Vision-Language Pretraining模型,通过对比学习对齐图像与文本特征。数据集中的EXIF元数据还催生了摄影参数预测网络ExifNet,该模型能逆向推断拍摄设备的配置参数。
数据集最近研究
最新研究方向
在计算机视觉与多模态学习领域,pxhere数据集因其海量高分辨率图像和宽松的CC0授权协议,正成为生成式AI研究的重要资源。该数据集被广泛应用于文本到图像生成模型的训练,特别是Stable Diffusion等开源项目的参数优化,研究者通过其丰富的场景标注和EXIF元数据,探索摄影风格迁移与设备特征关联性。近期热点聚焦于图像描述生成的细粒度控制,利用pxhere的结构化标签体系构建视觉-语言对齐模型,同时在伦理维度引发关于合成图像版权边界的讨论,为数字内容创作提供了合规的素材基础。
以上内容由遇见数据集搜集并总结生成


