TinyStories-QA-SFT
收藏Hugging Face2025-05-10 更新2025-05-11 收录
下载链接:
https://huggingface.co/datasets/ReactiveAI/TinyStories-QA-SFT
下载链接
链接失效反馈官方服务:
资源简介:
ReactiveAI的TinyStories-QA-SFT数据集是一个基于roneneldan/TinyStories数据集制作的监督微调数据集,用于Reactive Transformer模型的第二阶段训练验证。数据集包含问题和答案对,都是合成的,不包含真实世界的知识。适用于小型研究模型的训练。
ReactiveAI's TinyStories-QA-SFT dataset is a supervised fine-tuning (SFT) dataset constructed based on the roneneldan/TinyStories dataset, intended for the second-stage training and validation of the Reactive Transformer model. The dataset comprises synthetic question-answer pairs and does not contain any real-world knowledge. It is suitable for training small-scale research models.
创建时间:
2025-05-10
搜集汇总
数据集介绍
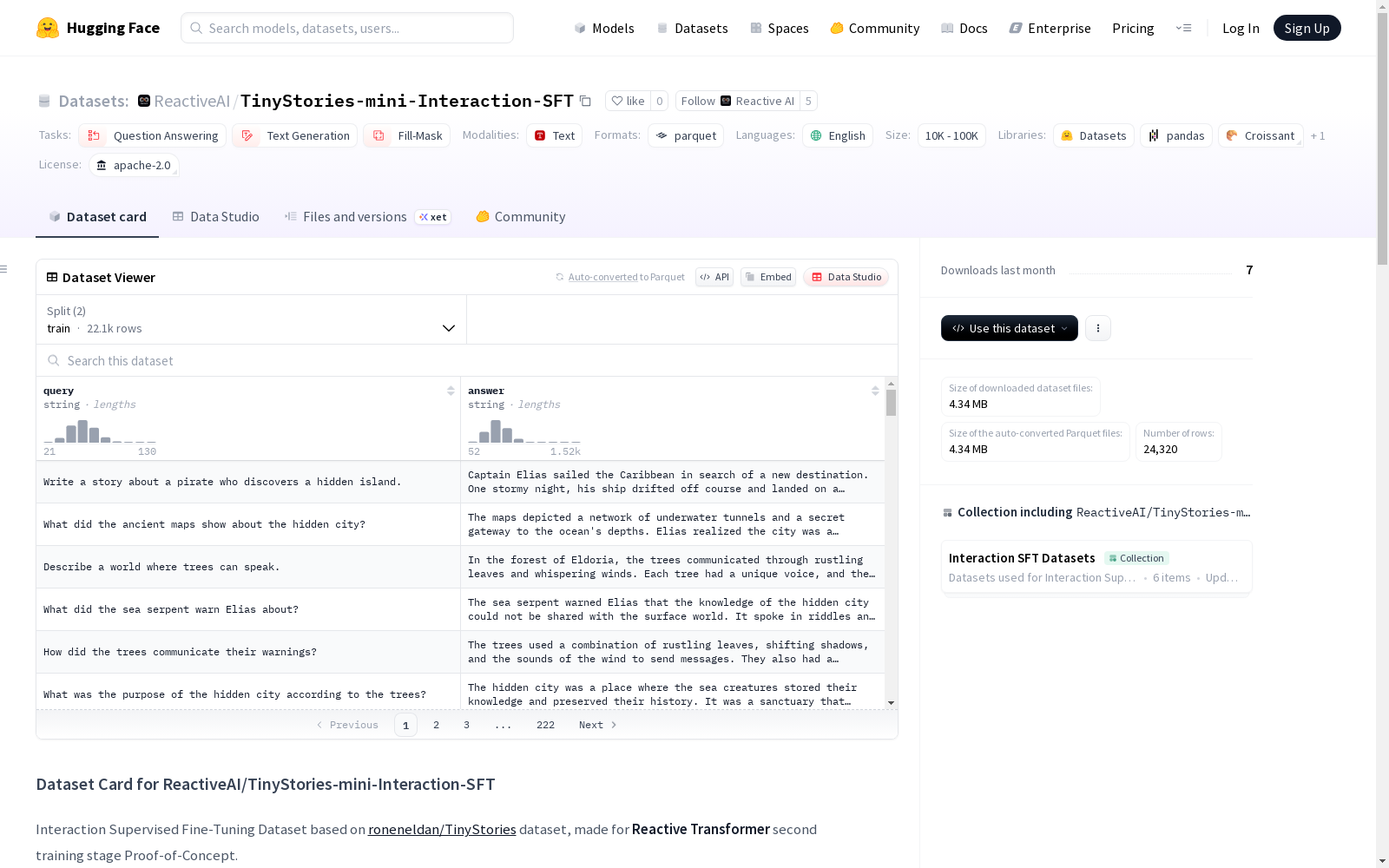
构建方式
在自然语言处理领域,TinyStories-QA-SFT数据集专为反应式Transformer架构的监督微调阶段而构建。该数据集基于roneneldan/TinyStories的叙事框架,通过Qwen3-4B模型以合成方式生成所有数据记录。生成过程中采用0.7的温度参数与默认采样设置,每批次产出约20组问答对,确保数据格式严格遵循[Q]查询[A]应答的交互范式,总规模包含2.1万训练样本与2千验证样本。
特点
该数据集最显著的特征在于其精巧的结构设计,每条数据由查询与应答两个文本字段构成,总长度严格控制在256个标记以内。查询段通常简明扼要,应答段则呈现更丰富的叙事展开,这种不对称结构完美契合反应式模型的短时记忆处理机制。所有内容均源自合成生成的简单故事场景,既规避了现实知识的复杂性,又通过主题连贯的批量生成方式模拟真实对话的连续性。
使用方法
研究人员可将该数据集直接应用于微型语言模型的监督微调,特别是针对反应式Transformer架构的第二阶段训练。使用时需将数据按7:1比例划分为训练集与验证集,注意每条交互记录应作为独立序列输入模型。由于数据本身具有主题聚类特性,建议在训练过程中实施动态混洗策略以增强模型泛化能力,但需严格限定在学术研究场景,避免用于生产环境。
背景与挑战
背景概述
自然语言处理领域对高效对话系统的探索催生了TinyStories-QA-SFT数据集的诞生。该数据集由Reactive AI团队于2024年基于TinyStories语料库构建,专为反应式Transformer架构的第二阶段训练设计。其核心在于通过问答对形式模拟交互场景,将对话历史从传统序列处理转移至短期记忆模块,为轻量化语言模型提供结构化监督微调数据,推动事件驱动型神经网络在资源受限环境中的应用。
当前挑战
该数据集致力于解决轻量级对话系统在交互格式适配中的语义连贯性挑战,其生成过程面临双重困难:一方面需确保问答对在256令牌限制内保持逻辑自洽,另一方面受限于合成数据的同质化倾向,批量生成时易出现话题重复现象。此外,基于大语言模型自动生成的数据可能隐含现实知识偏差,对纯合成语料的可靠性构成潜在影响。
常用场景
经典使用场景
在自然语言处理领域,TinyStories-QA-SFT数据集主要应用于反应式Transformer架构的监督微调阶段。该数据集通过精心设计的问答对格式,为模型提供了标准化的交互训练样本,使其能够学习在限定上下文长度内生成连贯的响应。这种训练方式特别适合探索短序列处理能力,为研究轻量级语言模型提供了理想的实验平台。
衍生相关工作
基于该数据集衍生的重要工作包括RxT-Alpha-Micro系列模型的开发与验证。这些研究探索了反应式架构在轻量级语言模型中的应用潜力,推动了事件驱动型语言处理范式的发展。相关研究进一步扩展了短期记忆机制在对话系统中的应用场景,为构建更高效的人机交互系统提供了新的技术路径。
数据集最近研究
最新研究方向
在轻量级语言模型研究领域,TinyStories-QA-SFT数据集正推动事件驱动架构的前沿探索。该数据集专为反应式Transformer模型的交互式监督微调设计,通过合成问答对构建简洁的交互格式,将对话历史从传统序列处理转移至内部短期记忆模块。这一创新显著降低了计算复杂度,为微型模型在资源受限环境中的部署开辟了新路径。当前研究聚焦于如何利用此类数据集优化记忆机制与交互生成的协同效率,同时探索其在边缘智能与实时对话系统中的潜在应用价值,为下一代高效能语言模型的架构革新提供了关键实验基础。
以上内容由遇见数据集搜集并总结生成


