有没有相关的论文或文献参考?
这个数据集是基于什么背景创建的?
数据集的作者是谁?
能帮我联系到这个数据集的作者吗?
这个数据集如何下载?
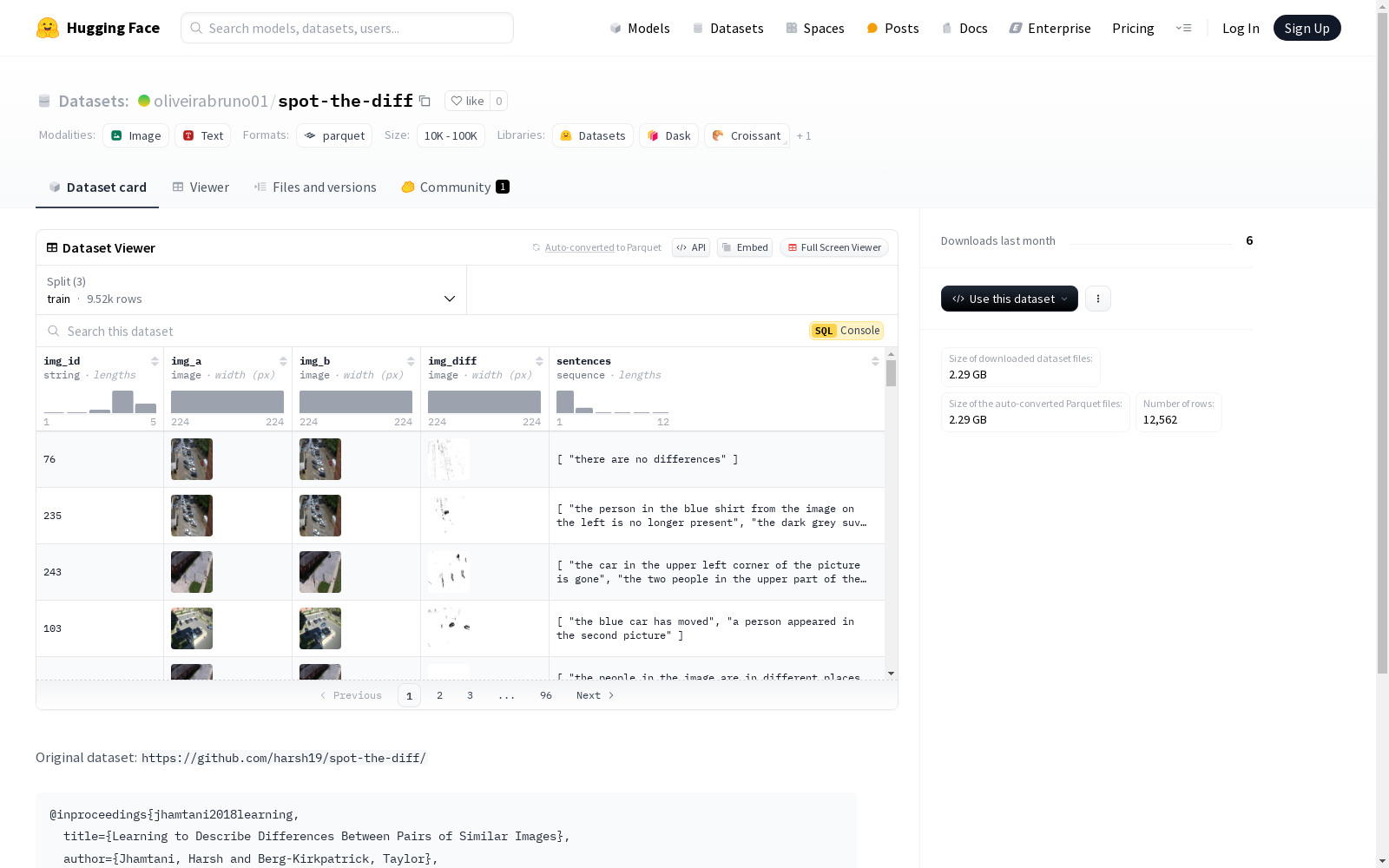
特征:
img_id: 字符串类型,图像的唯一标识符。img_a: 图像类型,第一张图像。img_b: 图像类型,第二张图像。img_diff: 图像类型,差异图像。sentences: 字符串序列,描述差异的句子。数据集划分:
train: 训练集,包含9524个样本,大小为1904363199.892字节。test: 测试集,包含1404个样本,大小为268451640.804字节。val: 验证集,包含1634个样本,大小为308229248.356字节。数据集大小:
default
data/train-*data/test-*data/val-*https://github.com/harsh19/spot-the-diff/@inproceedings{jhamtani2018learning, title={Learning to Describe Differences Between Pairs of Similar Images}, author={Jhamtani, Harsh and Berg-Kirkpatrick, Taylor}, booktitle={Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing (EMNLP)}, year={2018} }
学生课堂行为数据集 (SCB-dataset3)
学生课堂行为数据集(SCB-dataset3)由成都东软学院创建,包含5686张图像和45578个标签,重点关注六种行为:举手、阅读、写作、使用手机、低头和趴桌。数据集覆盖从幼儿园到大学的不同场景,通过YOLOv5、YOLOv7和YOLOv8算法评估,平均精度达到80.3%。该数据集旨在为学生行为检测研究提供坚实基础,解决教育领域中学生行为数据集的缺乏问题。
arXiv 收录
Breast Ultrasound Images (BUSI)
小型(约500×500像素)超声图像,适用于良性和恶性病变的分类和分割任务。
github 收录
中国高分辨率高质量PM2.5数据集(2000-2023)
ChinaHighPM2.5数据集是中国高分辨率高质量近地表空气污染物数据集(ChinaHighAirPollutants, CHAP)中PM2.5数据集。该数据集利用人工智能技术,使用模式资料填补了卫星MODIS MAIAC AOD产品的空间缺失值,结合地基观测、大气再分析和排放清单等大数据生产得到2000年至今全国无缝隙地面PM2.5数据。数据十折交叉验证决定系数R2为0.92,均方根误差RMSE为10.76 µg/m3。主要范围为整个中国地区,空间分辨率为1 km,时间分辨率为日、月、年,单位为µg/m3。注意:该数据集持续更新,如需要更多数据,请发邮件联系作者(weijing_rs@163.com; weijing@umd.edu)。 数据文件中包含NC转GeoTiff的四种代码(Python、Matlab、IDL和R语言)nc2geotiff codes。
国家青藏高原科学数据中心 收录
中国100m人口密度数据集(2000-2020年)
本数据集为中国100m人口密度数据集,数据来源于WorldPop平台,该数据集为UN-adjusted 且 Constrained 版本。 数据集按照年份共计包含21个tif栅格数据,worldpop-year-merged.tif。
国家地球系统科学数据中心 收录
PlantVillage
在这个数据集中,39 种不同类别的植物叶子和背景图像可用。包含 61,486 张图像的数据集。我们使用了六种不同的增强技术来增加数据集的大小。这些技术是图像翻转、伽玛校正、噪声注入、PCA 颜色增强、旋转和缩放。
OpenDataLab 收录