Disaster Image Dataset
收藏arXiv2021-07-03 更新2024-07-30 收录
下载链接:
https://niloy193.github.io/Disaster-Dataset
下载链接
链接失效反馈官方服务:
资源简介:
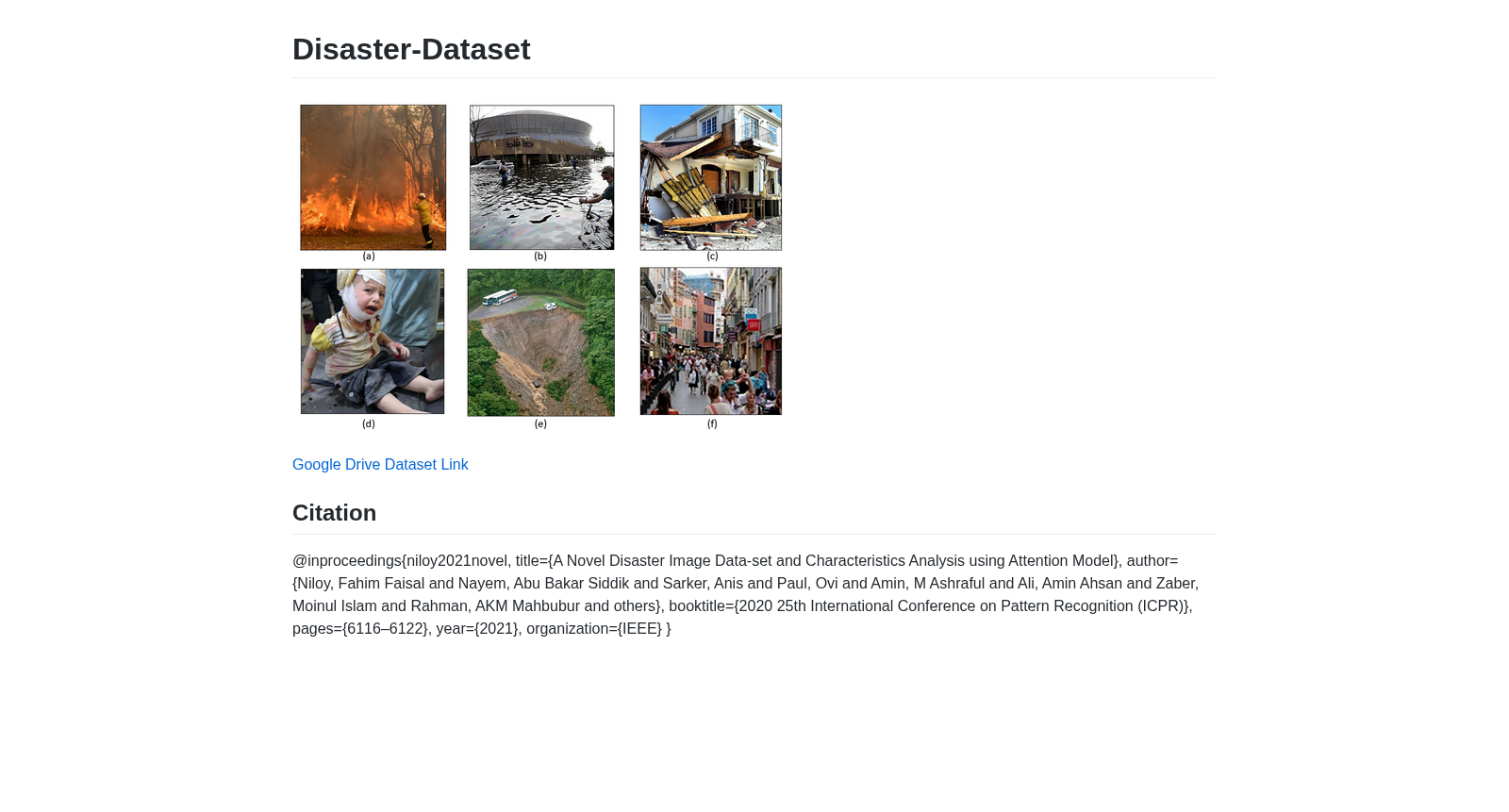
该数据集包含来自不同来源的火灾、水灾和地震等三种不同灾害的图像,以及因自然或人为灾害受损的基础设施和因战争或事故受伤的人的图像。还包括一类名为'无损害'的图像,这些图像没有灾害或损害迹象。数据集共有13,720张手动标注的图像,每张图像由三个人标注。
This dataset contains images of three types of disasters including fires, floods and earthquakes from various sources, as well as images of infrastructure damaged by natural or man-made disasters and images of people injured due to wars or accidents. It also includes a category named 'No Damage', which refers to images without any signs of disasters or damage. The dataset has a total of 13,720 manually annotated images, and each image is annotated by three people.
创建时间:
2021-07-03
搜集汇总
数据集介绍
构建方式
在灾害图像识别领域,构建高质量数据集是推动深度学习模型发展的关键。本数据集通过系统化流程收集了13,720张图像,涵盖火灾、水灾、土地灾害、基础设施损坏、人员伤亡及非灾害六类。图像源自新闻门户、社交媒体及现有标准数据集,并聚焦于澳大利亚野火、印度洪水等近期灾害事件以增强时效性。每张图像由三名经过培训的标注员独立注释,仅当至少两人达成一致时才纳入数据集,确保了标注的可靠性。此外,数据集包含200张测试图像的边界框注释,用于评估模型注意力定位能力。
特点
该数据集在灾害图像分类中展现出显著的多样性与结构性优势。其覆盖六大类别及十个子类,如火灾类别下的城市火灾与野外火灾,土地灾害下的滑坡与干旱,从而提供了丰富的语义层次。图像来源广泛,涉及全球多个地理区域,减少了地域偏差。通过平均图像JPEG文件大小分析,本数据集在多数类别中表现出更高的信息密度,证实其多样性优于现有数据集。同时,精心设计的非灾害类别包含人类、建筑街道、野生动物森林及海洋子类,作为各灾害类别的负样本,增强了分类器的判别能力。
使用方法
该数据集适用于训练和评估深度学习模型在灾害图像分类与注意力定位任务中的性能。研究人员可采用五折交叉验证来评估数据集的均匀性,其中每折使用80%的图像训练,20%测试,确保无重叠。在测试阶段,可使用提供的200张独立测试图像评估模型泛化能力。为分析模型注意力机制,可结合类激活图(CAM)或三层注意力模型(TLAM)等架构,通过比较模型注意力热图与人工标注的边界框,计算平均交并比(mIoU)以量化注意力定位准确性。数据集的公开可用性支持其在灾害响应系统中的实际应用验证。
背景与挑战
背景概述
随着全球气候变化与人口密度增加,自然灾害与人为灾害频发,对应急响应系统提出了更高要求。在此背景下,由孟加拉国独立大学AGenCy实验室的研究团队于2021年创建的Disaster Image Dataset,旨在解决灾害图像分类领域缺乏标准化、多样化数据的问题。该数据集包含13,720张手动标注的图像,涵盖火灾、水灾、土地灾害、基础设施损坏、人员伤亡及非损坏六大类别,并细分为十个子类,覆盖了广泛的地理区域与灾害场景。其核心研究问题是通过提供高质量、多样化的图像数据,提升深度学习模型在灾害识别与分类中的性能与注意力定位能力,对灾害管理、计算机视觉及应急响应领域具有重要的推动作用。
当前挑战
在灾害图像分类领域,现有数据集常面临类别覆盖不全、图像多样性不足、标注质量参差不齐等挑战,导致模型难以准确识别复杂灾害场景并聚焦关键区域。Disaster Image Dataset的构建过程中,研究人员需克服图像收集的多样性难题,包括从新闻门户、社交媒体等多源渠道获取代表性图像,并确保涵盖不同地理区域与灾害类型。同时,标注工作涉及三名独立标注员的一致性验证,以消除主观偏差,并需处理低分辨率、嵌入文本等低质量图像的筛选问题。此外,数据集的测试集设计需包含具有挑战性的图像,如语义相似场景,以评估模型的鲁棒性与注意力定位能力。
常用场景
经典使用场景
在计算机视觉与灾害管理交叉领域,Disaster Image Dataset 为灾害图像的自动分类与识别提供了基准测试平台。该数据集通过涵盖火灾、水灾、土地灾害、基础设施损坏、人员伤亡及非灾害六类图像,并细分为十个子类别,构建了一个多类别、高多样性的图像分类任务。研究者通常利用该数据集训练深度卷积神经网络,如VGG-16、ResNet等,结合注意力机制(如CAM、TLAM)进行端到端的图像分类模型开发与评估,旨在提升模型对复杂灾害场景的判别能力与注意力定位精度。
解决学术问题
该数据集有效应对了灾害图像识别领域长期存在的若干学术挑战。首先,它通过收集全球多区域的灾害图像,缓解了以往数据集地理覆盖狭窄导致的模型泛化能力不足问题。其次,其精心设计的子类别结构与高多样性样本,促使模型学习更具判别性的灾害特征,而非依赖背景干扰物(如消防车),从而提升了分类器的注意力定位准确性。此外,数据集中包含的边界框标注测试集,为量化模型注意力与人类视觉关注的一致性提供了评估基准,推动了可解释性计算机视觉研究在灾害分析中的应用。
衍生相关工作
基于该数据集,学术界衍生出一系列聚焦于灾害视觉分析的经典研究工作。例如,研究者利用其多类别特性开发了融合多模态信息(如图像与文本)的灾害检测框架,提升了社交媒体中灾害信息的检索精度。另有工作借鉴其注意力验证机制,提出了改进的梯度加权类激活映射方法,以增强模型的可解释性。此外,该数据集常被用作基准,与卫星遥感图像数据集进行跨模态联合训练,以构建空天地一体化的灾害监测系统,推动了灾害信息学与遥感科学的交叉融合。
以上内容由遇见数据集搜集并总结生成


