有没有相关的论文或文献参考?
这个数据集是基于什么背景创建的?
数据集的作者是谁?
能帮我联系到这个数据集的作者吗?
这个数据集如何下载?
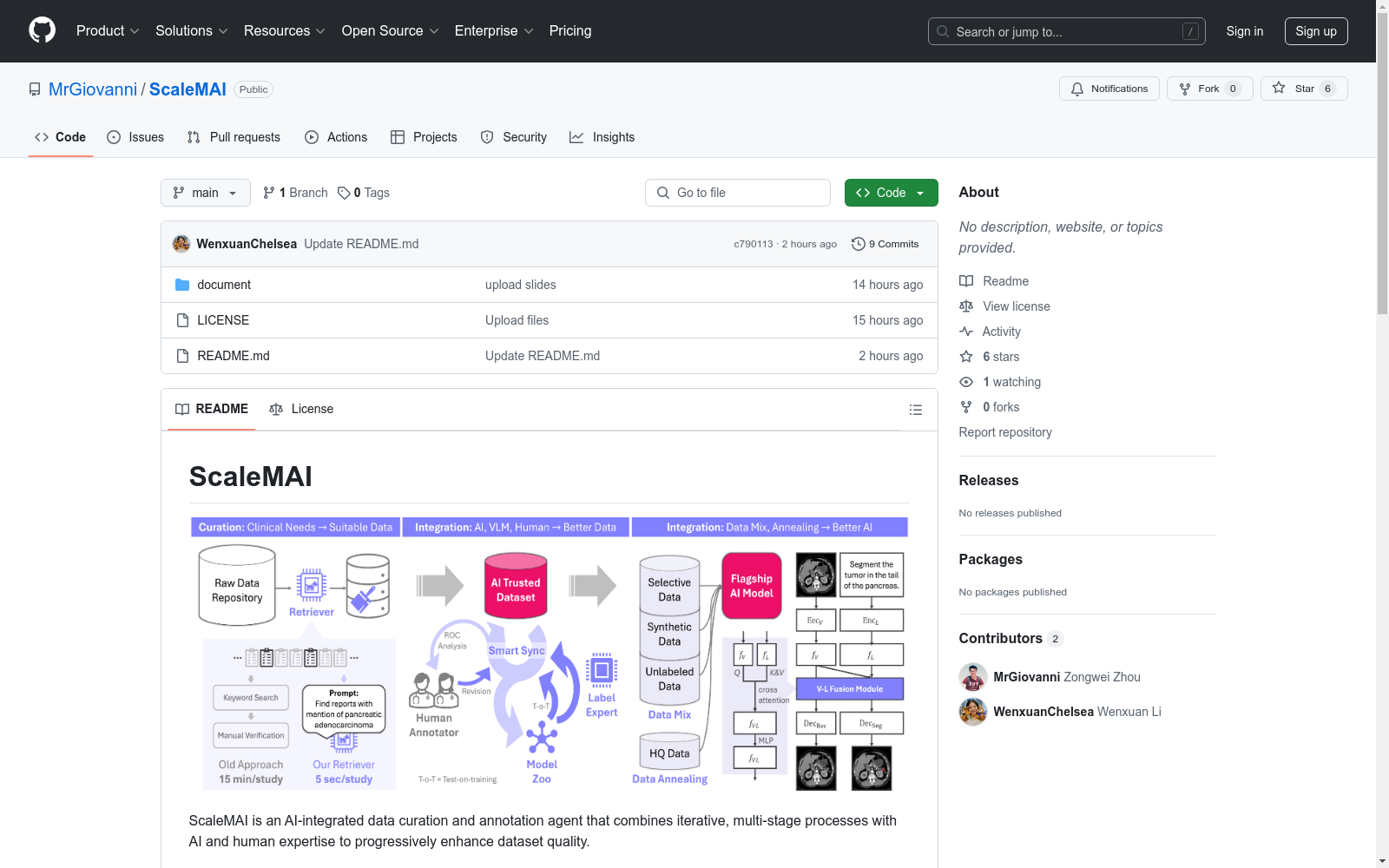
ScaleMAI 是一个集成了人工智能的数据整理和标注工具,结合了多阶段的迭代过程与人工智能及人类专家的知识,逐步提升数据集的质量。
PancreaVerse 是一个用于胰腺癌研究的可信数据集,包含以下关键信息:
| 数据集名称 | 类别数量 | CT扫描数量 | 数据来源中心数量 |
|---|---|---|---|
| TCIA-CBCT | 0 | 40 | 1 |
| MSD-Pancreas | 2 | 420 | 1 |
| TCIA-panNET | 0 | 38 | 1 |
| PANORAMA | 6 | 3,000 | 7 |
| PancreaVerse | 27 | 25,362 | 112 |
bibtex @article{li2025scalemai, title={ScaleMAI: Accelerating the Development of Trusted Datasets and AI Models}, author={Wenxuan Li and Pedro R. A. S. Bassi and Tianyu Lin and Yu-Cheng Chou and Xinze Zhou and Yucheng Tang and Fabian Isensee and Kang Wang and Qi Chen and Xiaowei Xu and Xiaoxi Chen and Lizhou Wu and Qilong Wu and Yannick Kirchhoff and Maximilian Rokuss and Saikat Roy and Yuxuan Zhao and Dexin Yu and Kai Ding and Constantin Ulrich and Klaus Maier-Hein and Yang Yang and Alan L. Yuille and Zongwei Zhou}, journal={arXiv preprint arXiv:2501.03410}, year={2025}, url={https://github.com/MrGiovanni/ScaleMAI} }
本工作得到了Lustgarten胰腺癌研究基金会和McGovern基金会的支持。论文内容涉及正在申请的专利。
GAOKAO-Bench
GAOKAO-Bench是由复旦大学计算机科学与技术学院创建的数据集,涵盖了2010至2022年间中国高考的所有科目题目,共计2811题。该数据集包含1781道客观题和1030道主观题,题型多样,包括单选、填空、改错、开放性问题等。数据集通过自动化脚本和人工标注将PDF格式的题目转换为JSON文件,数学公式则转换为LATEX格式。GAOKAO-Bench旨在为大型语言模型提供一个全面且贴近实际应用的评估基准,特别是在解决中国高考相关问题上的表现。
arXiv 收录
FER2013
FER2013数据集是一个广泛用于面部表情识别领域的数据集,包含28,709个训练样本和7,178个测试样本。图像属性为48x48像素,标签包括愤怒、厌恶、恐惧、快乐、悲伤、惊讶和中性。
github 收录
中国农村金融统计数据
该数据集包含了中国农村金融的统计信息,涵盖了农村金融机构的数量、贷款余额、存款余额、金融服务覆盖率等关键指标。数据按年度和地区分类,提供了详细的农村金融发展状况。
www.pbc.gov.cn 收录
中国农村教育发展报告
该数据集包含了中国农村教育发展的相关数据,涵盖了教育资源分布、教育质量、学生表现等多个方面的信息。
www.moe.gov.cn 收录
微博与抖音评论数据集
数据集源自微博平台与抖音平台的评论信息,基于两个热点事件来对评论等信息进行爬取收集形成数据集。原数据一共3W5条,但消极评论与中立评论远远大于积极评论。因此作特殊处理后,积极数据2601条,消极数据2367条,中立数据2725条,共7693条数据。
github 收录