DCLM_German
收藏Hugging Face2025-06-12 更新2025-06-13 收录
下载链接:
https://huggingface.co/datasets/faidrap/DCLM_German
下载链接
链接失效反馈官方服务:
资源简介:
DCLM-German数据集是一个包含德语的语言数据集,经过LLM预训练处理,并使用FastText语言检测进行过滤。数据集来源于Common Crawl数据,经过精炼网络、去重和FastText过滤处理。数据集包含43,452个压缩的JSONL文件。
The DCLM-German dataset is a German-language linguistic dataset that has undergone LLM pre-training and was filtered via FastText language detection. It is sourced from Common Crawl data, and has been processed through web content refinement, deduplication, and FastText-based filtering. The dataset consists of 43,452 compressed JSONL files.
创建时间:
2025-06-05
搜集汇总
数据集介绍
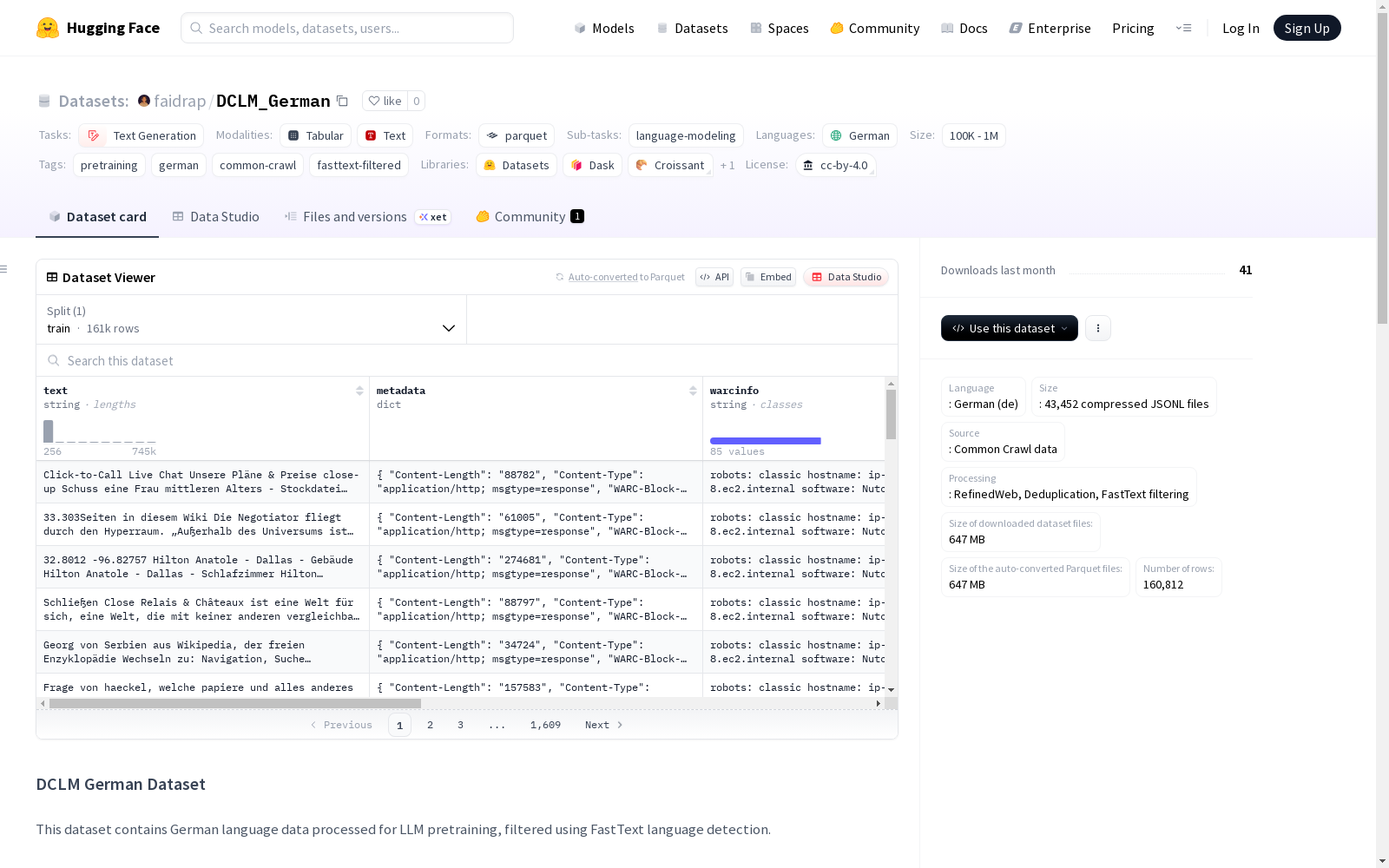
构建方式
在德语自然语言处理领域,大规模语料库的构建对语言模型预训练至关重要。DCLM_German数据集源自Common Crawl网络爬虫数据,经过RefinedWeb流程的精细化处理,采用FastText语言检测技术确保德语文本的纯净度,并通过去重机制消除冗余信息,最终形成43,452个压缩JSONL文件的高质量语料集合。
特点
该数据集作为德语单语语料库,其显著特征体现在严格的语种筛选机制上,每个文本段落均附带FastText语言概率标注,例如示例中整页德语置信度高达91.7%。数据单元保留完整的网络文档元数据,包括WARC记录标识、内容类型和时间戳等,为研究网络文本特性提供多维分析视角。
使用方法
研究者可通过Hugging Face datasets库直接加载该数据集,支持流式读取模式以应对大规模数据处理需求。典型应用场景包括德语语言模型预训练、文本生成任务基准测试等。使用时应遵循CC-BY-4.0许可协议,并引用相关作者提供的标准文献格式。
背景与挑战
背景概述
德语大规模语言模型预训练数据集DCLM_German由研究者Faidra Anastasia Patsatzi于2024年构建,旨在填补德语自然语言处理领域高质量预训练语料的空白。该数据集基于Common Crawl网络爬虫数据,采用RefinedWeb预处理流程,并经过严格的去重与FastText语言检测过滤,专注于提升德语语言模型的表征学习能力与生成性能。其构建反映了多语言自然语言处理研究中对于低资源语言语料标准化与规模化的迫切需求,为德语语境下的文本生成、语言建模等任务提供了重要基础资源。
当前挑战
该数据集致力于解决德语语言模型预训练中数据质量不一与噪声过滤的核心挑战,尤其针对网络文本中存在的语法错误、语义冗余及多语言混杂等问题。在构建过程中,面临Common Crawl原始数据规模庞大且结构异质带来的处理复杂度,需通过高效的分布式去重算法与高精度语言识别技术确保语料纯净度。同时,需平衡语料覆盖广度与文本质量,避免过度过滤导致语义多样性损失,这对数据清洗策略的设计与计算资源分配提出了较高要求。
常用场景
经典使用场景
在德语自然语言处理领域,DCLM_German数据集作为大规模预训练语料库,主要应用于德语语言模型的预训练任务。该数据集经过FastText语言检测过滤和精细化处理,为研究者提供了高质量德语文本资源,支持自回归和掩码语言建模等经典训练范式。其海量的文本规模与严谨的数据清洗流程,为构建高性能德语语言模型奠定了坚实基础。
实际应用
在实际应用层面,基于该数据集训练的德语语言模型已广泛应用于智能客服系统、学术文献自动摘要、跨语言信息检索等场景。其高质量的语言表征能力为德语地区的金融、法律、医疗等专业领域提供了可靠的文本处理基础。同时,该数据集支撑的模型在德语教育科技领域也发挥着重要作用,如语法检查、作文评分等应用。
衍生相关工作
该数据集催生了多个具有影响力的德语NLP研究工作,包括德语BERT变体模型的开发、德语文本生成系统的优化以及跨语言对齐研究。基于其构建的预训练模型在德语语法错误检测、语义相似度计算等下游任务中表现出色。相关研究不仅推动了德语语言模型架构的创新,还为低资源语言处理提供了可借鉴的数据处理范式。
以上内容由遇见数据集搜集并总结生成


