danish-foundation-models/danish-dynaword
收藏Hugging Face2026-04-30 更新2024-12-21 收录
下载链接:
https://hf-mirror.com/datasets/danish-foundation-models/danish-dynaword
下载链接
链接失效反馈官方服务:
资源简介:
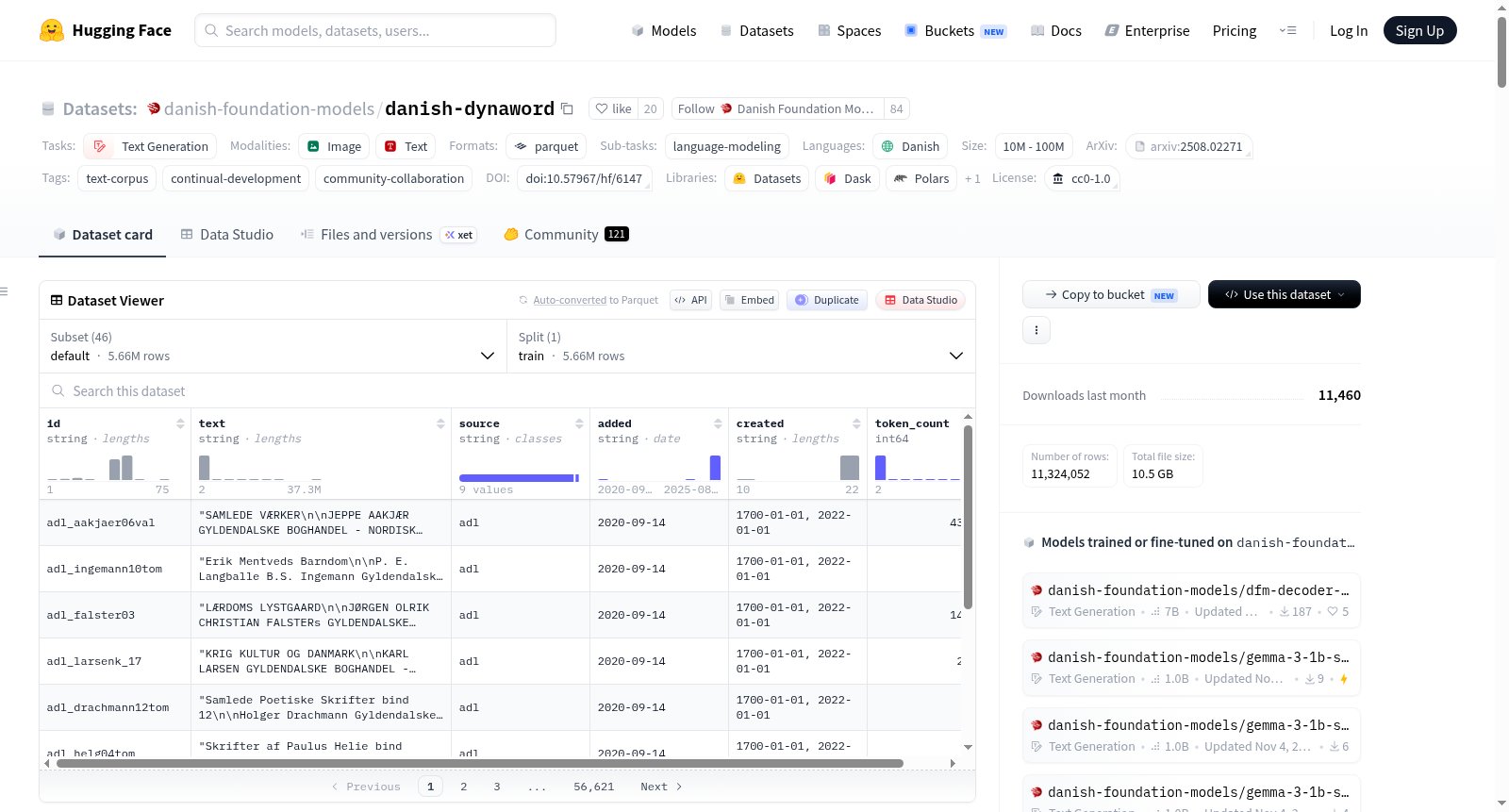
Danish Dynaword是一个不断更新的丹麦自由文本数据集集合,涵盖多个领域。该数据集旨在持续更新新的数据源,主要用于语言模型的开发,但也适用于其他用途,如语言发展和跨领域差异的研究。数据集包含来自不同来源的文本,每个条目都包含一个文本及其相关元数据。
The Danish dynaword is a continually developed collection of Danish free-form text datasets from various domains. It is intended to be continually updated with new data sources. If you would like to contribute a dataset see the [contribute section](#contributing-to-the-dataset). The dataset includes multiple configurations (subsets) each with its own data files in Parquet format. The dataset is monolingual, containing text in Danish, and is curated with the intention of making large quantities of Danish text data available for various NLP tasks such as language modeling. Each data instance includes metadata such as source, unique identifier, date added, date range of creation, license, and domain. The dataset is provided in a single train split. The README also mentions the languages included in the dataset, which are denoted using BCP-47 language tags.
提供机构:
danish-foundation-models
搜集汇总
数据集介绍
构建方式
丹麦语作为斯堪的纳维亚语系的重要成员,其语言资源的丰富程度直接影响着自然语言处理技术的发展。Danish Dynaword数据集正是为应对这一需求而生,它通过持续收集与整合来自多个领域的丹麦语自由文本构建而成。该数据集的构建并未依赖人工标注,而是广泛汇集了众包来源的原始语料,涵盖法律文献、新闻、书籍、对话、社交媒体、网页内容、百科全书、医学文献、方言文本及有声读物等四十余个子集。每个子集均以Parquet格式存储,且均采用开放许可协议,确保其在大型语言模型训练中的合规性与可复用性。
特点
该数据集的显著特征在于其持续发展的动态特性与高度多元化的语料覆盖面。其收录文本超过566万篇,包含约68.3亿个Token(基于Llama 3分词器计算),平均每篇文本长度约为1210个Token。语料来源横跨法律、新闻与书籍等传统领域,亦囊括方言与社交媒体等非正式语言变体,尤其收录了博恩霍尔姆方言与南日德兰方言等珍贵资源。所有子集均采用CC-0、CC-BY-SA等开放许可,数据集整体元数据以CC-0协议发布,显著降低了用户在使用时的版权顾虑。
使用方法
用户可通过Hugging Face Datasets库便捷加载该数据集,支持完整下载与流式加载两种模式。加载时只需指定数据集名称'danish-foundation-models/danish-dynaword'并选择'split='train'',即可获取全部语料。若需针对特定子集进行操作,例如加载文学子集时,可通过配置名称'adl'实现精准提取。为了确保实验的可复现性,用户还可以通过指定版本号(revision参数)锁定特定版本的数据集内容,从而在持续更新的语料环境中维持研究的一致性。
背景与挑战
背景概述
丹麦语作为一门低资源语言,在大规模语言模型的预训练语料构建中长期面临数据匮乏的困境。由丹麦基础模型团队于2023年创建的Danish Dynaword数据集,旨在系统性地汇聚来自法律、新闻、书籍、社交媒体等数十个领域的公开文本,形成一个持续演进、开放许可的高质量丹麦语语料库。该数据集收录了超过56万份文档、约68亿词元,其核心研究问题在于为丹麦语大语言模型的训练提供规模充足、领域多样且版权清晰的文本资源。Danish Dynaword的发布显著推动了北欧地区自然语言处理的发展,为低资源语言的语料库建设树立了可复制的范式。
当前挑战
Danish Dynaword所解决的领域核心挑战是丹麦语大语言模型训练数据的稀缺性与多样性不足。在数据构建过程中,团队面临多重困难:首先,需从四十余个异构来源中整合文本,确保覆盖法律、医学、方言等专业领域的同时,协调不同数据集的开放许可协议;其次,对历史手写文本、方言语料等低资源子集进行数字化与清洗颇具难度;最后,数据集的持续更新机制要求建立高效的社区贡献流程与质量控制标准,以维持语料的新鲜度与可靠性。
常用场景
经典使用场景
Danish Dynaword作为丹麦语自然语言处理领域的基石性语料库,其经典使用场景主要聚焦于大规模语言模型的预训练任务。凭借其涵盖法律、新闻、书籍、对话、社交媒体、百科全书、医学等十余个领域的广泛文本,该数据集为训练具备多领域理解能力的丹麦语Transformer架构模型提供了海量、多样且开放许可的训练素材。研究者常将其作为无监督语言建模(Language Modeling)的基础语料,通过自回归或掩码语言建模目标,使模型习得丹麦语的语法结构、语义表征及篇章连贯能力。该语料库的持续发展特性,亦使其成为研究语言模型在动态语料更新下持续学习能力(Continual Learning)的理想基准。
实际应用
在实际产业应用中,Danish Dynaword扮演着丹麦语生成式AI基座模型核心训练数据的角色。基于该语料库训练的模型可被部署于多种商业场景:例如,在法律科技领域,支持自动摘要司法判决书(retsinformationdk子集)或辅助起草法律文书;在媒体与出版行业中,用于自动化新闻摘要生成、古文献数字化转录后的文本润色(如历史手写体数据集);在公共管理层面,赋能市政会议记录的智能归档与关键议题提取。此外,对话类子集(如议会辩论、访谈、影视字幕)使得训练面向丹麦用户的智能客服系统或语音助手成为可能,而包含方言与方言变体的语料(如博恩霍尔姆方言)则有助于开发更具包容性的语音交互界面,服务少数族裔社区。
衍生相关工作
Danish Dynaword的诞生催生了一系列围绕丹麦语预训练模型的经典工作。最直接的衍生成果是danish-foundation-models组织发布的一系列基于该语料库训练的基础模型,这些模型采用了主流的LLaMA架构,并探索了不同参数规模下的语言理解与生成能力。在方法论层面,研究者利用该数据集的数据消融实验(Data Ablation Study),系统分析了不同来源子集(如法律与社交媒体)对模型在下游任务(如命名实体识别、文本分类)性能的贡献权重,揭示了语料多样性比单纯增加数据量更为关键。此外,该语料库的动态更新特性促进了持续预训练(Continual Pretraining)与知识遗忘(Catastrophic Forgetting)缓解策略的研究,这些工作为其他低资源语言构建可持续演进的NLP基础设施提供了可复现的实践范式与基准参考。
以上内容由遇见数据集搜集并总结生成


