CALVIN
收藏arXiv2022-07-13 更新2024-06-21 收录
下载链接:
http://calvin.cs.uni-freiburg.de
下载链接
链接失效反馈官方服务:
资源简介:
CALVIN是由德国弗莱堡大学创建的一个开放源代码模拟基准数据集,旨在学习长期语言条件下的机器人操作任务。该数据集包含约24小时的远程操作非结构化游戏数据和20000条语言指令,支持多种传感器,如RGB-D图像、本体感受信息和基于视觉的触觉传感。CALVIN数据集的创建旨在使研究人员能够开发能够解决多种机器人操作任务的代理,这些任务通过人类语言指定,并从机载传感器获取输入。数据集的应用领域包括机器人学习和自然语言处理,旨在解决机器人如何通过自然语言指令执行复杂操作任务的问题。
CALVIN is an open-source simulated benchmark dataset developed by the University of Freiburg, Germany, for learning long-horizon language-conditioned robotic manipulation tasks. The dataset contains approximately 24 hours of remotely operated unstructured gameplay data and 20,000 language instructions, supporting multiple sensor modalities including RGB-D images, proprioceptive information, and vision-based tactile sensing. The core purpose of the CALVIN dataset is to enable researchers to develop agents capable of solving a variety of robotic manipulation tasks specified via human natural language, which take inputs from on-board sensors. Its application areas include robotic learning and natural language processing, aiming to address the problem of how robots can perform complex manipulation tasks by following natural language instructions.
提供机构:
弗莱堡大学, 德国
创建时间:
2021-12-07
搜集汇总
数据集介绍
构建方式
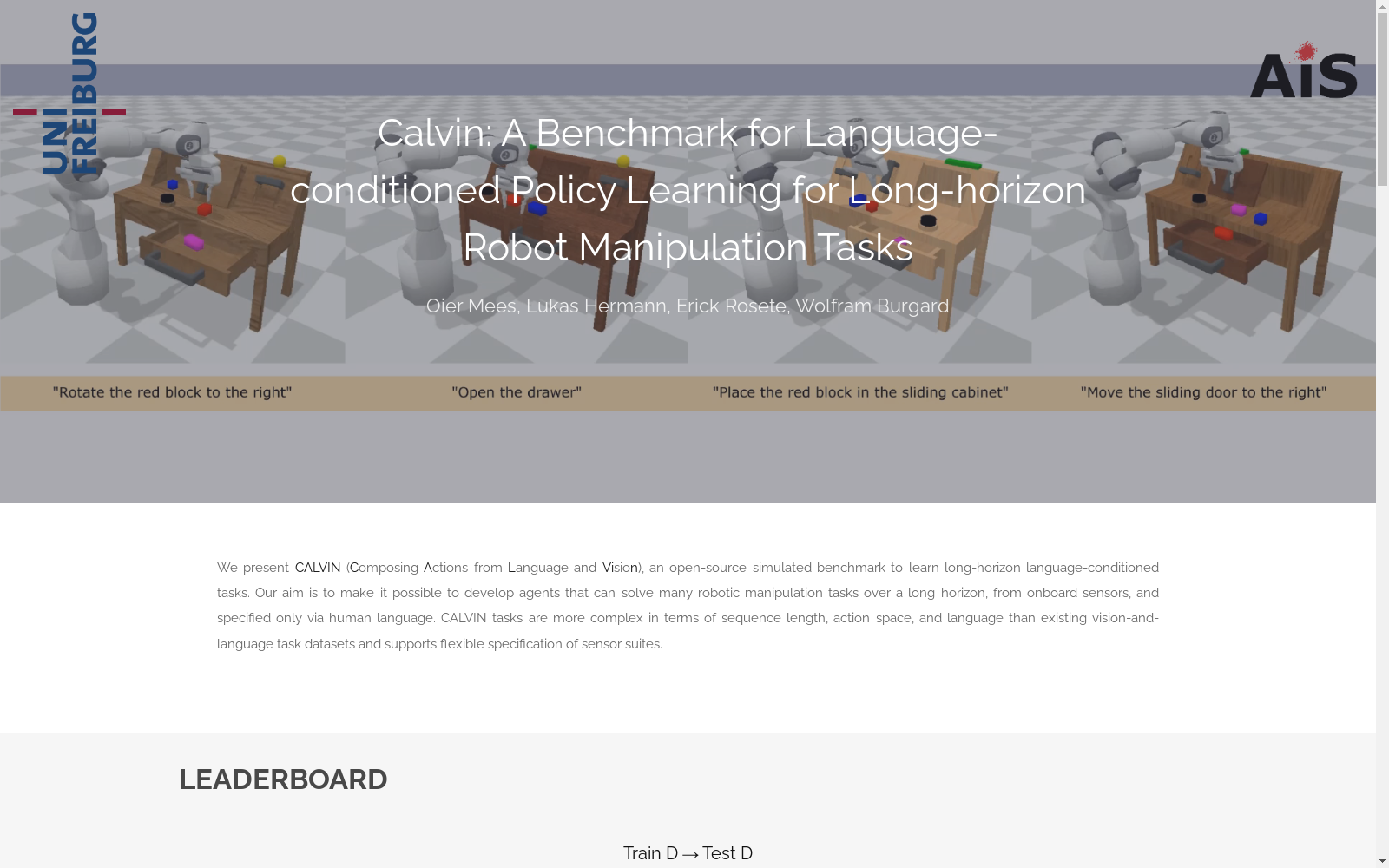
CALVIN数据集是一个用于多任务桌面操作的模拟基准,包含四个场景分割(A、B、C和D),共34个基本任务,以及24,000个人工遥操作演示,每个演示都标注了语言指令。该数据集的构建目的是为了评估机器人策略在模拟环境中的性能,特别是完成一系列连续任务的能力。
使用方法
使用CALVIN数据集进行机器人策略训练和评估通常包括以下几个步骤:首先,选择合适的VLM模型作为基础,如LLaVA、Flamingo或KosMos等。然后,根据研究需要,选择合适的VLA结构,如单步模型、交叠模型或策略头模型等。接下来,将VLM模型转换为VLA模型,并在CALVIN数据集上进行训练。训练完成后,使用数据集的D分割部分对模型进行评估,主要关注连续任务的成功率和平均任务长度等指标。此外,还可以将模型应用于真实世界的机器人操作任务中,以验证其在实际应用中的效果。
背景与挑战
背景概述
随着机器人技术的发展,构建能够感知、推理并与物理环境交互的通用机器人策略一直是机器人领域的一大挑战。近年来,通过在机器人数据上微调视觉语言模型(VLMs)并进行一定的架构调整,人们积极探索学习机器人基础模型。由此产生的模型,也称为视觉语言动作模型(VLAs),在模拟和现实世界的任务中展现出良好的性能。然而,从VLMs到VLAs的转换并非易事,因为现有的VLAs在骨干网络、动作预测公式、数据分布和训练策略上存在差异。为了系统理解VLAs的设计选择,本研究揭示了显著影响VLAs性能的关键因素,并重点关注了三个基本设计选择:选择哪种骨干网络、如何制定VLAs架构以及何时添加跨体现数据。研究结果表明,基于VLMs的VLAs在构建通用机器人策略方面具有有效性和效率,并开发了一种新的VLAs家族RoboVLMs,它需要很少的手动设计,并在三个模拟任务和现实世界实验中取得了新的最先进性能。
当前挑战
VLAs面临的挑战主要包括:1)所解决的领域问题,即如何将VLMs的强大能力应用于机器人动作预测和执行;2)构建过程中所遇到的挑战,包括选择合适的VLM骨干网络、设计有效的VLAs架构、确定何时以及如何使用跨体现数据。此外,VLAs在现实世界应用中的泛化能力和数据效率也是一个重要的挑战。
常用场景
经典使用场景
CALVIN数据集作为模拟多任务桌面操作的标准基准,被广泛用于评估机器人操作策略的性能。它包含24K个由人类远程操作演示的任务,每个任务都带有语言指令。数据集根据不同的场景设置分为四个部分(A、B、C、D),并提供了34个基本任务,这些任务涵盖了机器人操作中的各种技能,例如旋转、移动、抬起、放置等。CALVIN数据集的经典使用场景包括评估机器人策略在模拟环境中的性能,特别是其在不同场景设置下的泛化能力和数据效率。
解决学术问题
CALVIN数据集解决了机器人操作领域的一个关键学术研究问题,即如何构建能够感知、推理并与物理环境交互的通用机器人策略。通过在CALVIN数据集上微调视觉语言模型(VLMs),可以生成视觉语言动作模型(VLAs),这些模型在模拟和真实世界的任务中都表现出良好的性能。CALVIN数据集的意义在于它为评估VLAs的性能提供了一个标准基准,并帮助研究人员理解VLAs在不同场景和任务中的表现。
实际应用
CALVIN数据集的实际应用场景包括开发能够执行复杂任务的通用机器人策略。通过在CALVIN数据集上训练VLAs,可以使机器人能够理解和执行由人类提供的语言指令,从而在多种环境中完成各种任务。例如,机器人可以学习如何在厨房环境中按照指令操作,或者在工厂环境中进行组装工作。CALVIN数据集的实际应用对于推动机器人技术在工业、医疗、家庭等领域的应用具有重要意义。
数据集最近研究
最新研究方向
CALVIN 数据集的最新研究方向主要聚焦于构建能够感知、推理并与物理环境互动的通用机器人策略。研究强调了基于大型预训练视觉语言模型(VLMs)的视觉语言动作模型(VLAs)在模拟和现实世界任务中的潜力。通过注入动作组件,VLAs 展示了强大的性能和泛化能力。然而,从 VLMs 到 VLAs 的转换并非易事,因为现有的 VLAs 在其骨干网络、动作预测公式、数据分布和训练方案方面存在差异。本研究揭示了影响 VLA 性能的关键因素,并着重回答了三个基本设计选择:选择哪种骨干网络、如何构建 VLA 架构以及何时添加跨身体数据。研究结果表明,VLAs 需要少量手动设计,并在三个模拟任务和现实世界实验中取得了新的最先进性能。此外,高度灵活的 RoboVLMs 框架已公开,以促进未来研究。该框架支持轻松集成新的 VLMs 和各种设计选择的自由组合。
相关研究论文
- 1Towards Generalist Robot Policies: What Matters in Building Vision-Language-Action Models清华大学, 字节跳动研究, 中科院自动化所MAIS-NLPR, 上海交通大学, 新加坡国立大学 · 2024年
以上内容由遇见数据集搜集并总结生成


