the-stack-v2-train-smol-ids-updated-content
收藏Hugging Face2025-09-13 更新2025-09-14 收录
下载链接:
https://huggingface.co/datasets/thepowerfuldeez/the-stack-v2-train-smol-ids-updated-content
下载链接
链接失效反馈官方服务:
资源简介:
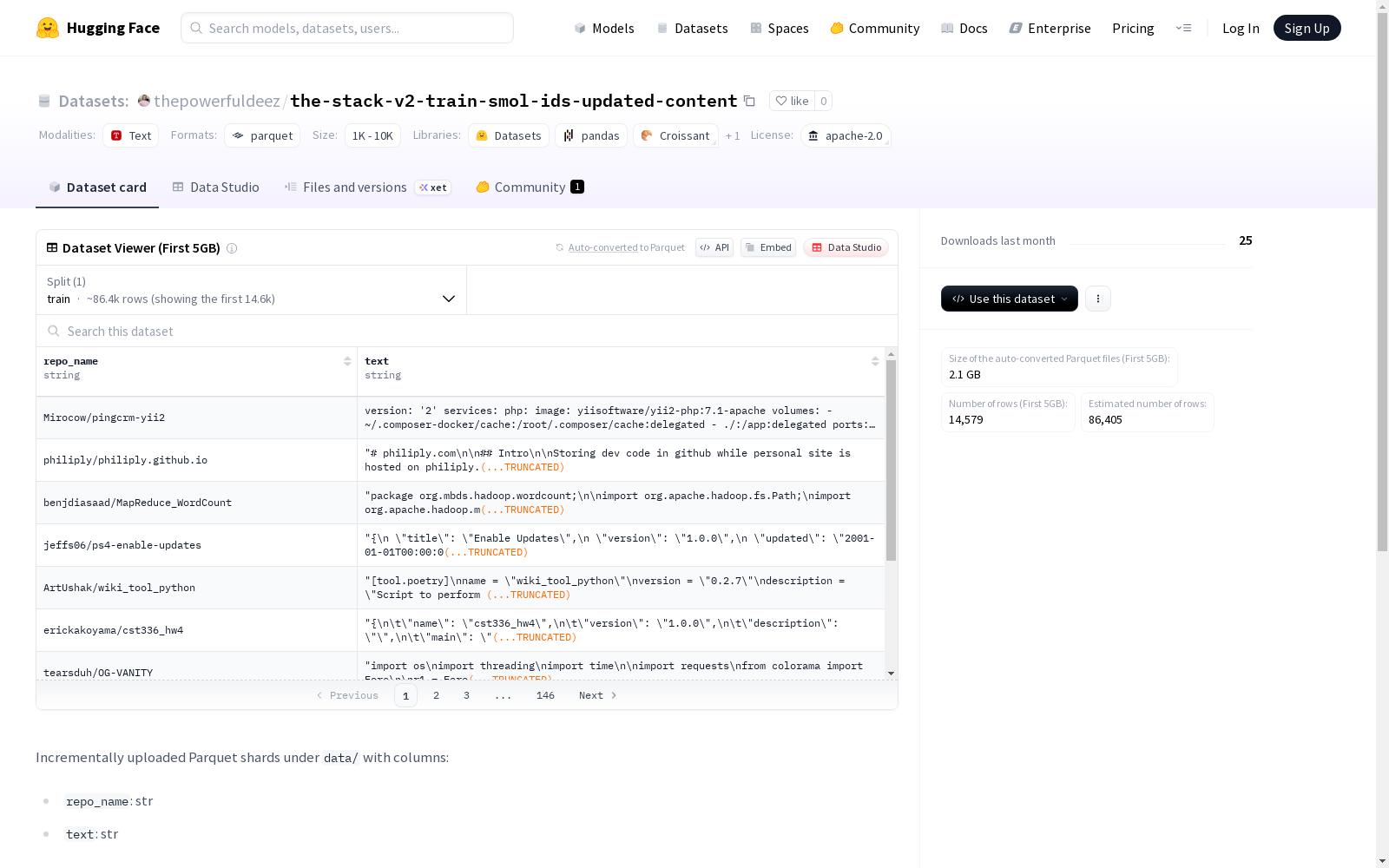
该数据集包含从HuggingFace仓库下载的代码仓库信息,主要特征包括仓库名称(`repo_name`)和文本内容(`text`)。数据集经过格式化处理,并且以训练集的形式提供,但具体的示例数量和大小未给出。总token量约为1000亿。
This dataset contains code repository information downloaded from the Hugging Face Hub. Its core features include the repository name (`repo_name`) and the textual content (`text`). The dataset has been formatted and is provided as a training dataset, but the exact number of samples and dataset size are not specified. The total token count is approximately 100 billion.
创建时间:
2025-09-12
原始信息汇总
数据集概述
基本信息
- 许可证: Apache 2.0
- 数据集名称: the-stack-v2-train-smol-ids-updated-content
数据特征
- 特征列:
repo_name: 字符串类型text: 字符串类型
数据拆分
- 训练集: 存在但具体字节数和样本数未指定
数据规模
- 下载大小: 未指定
- 数据集大小: 未指定
- 总标记数: 约1000亿
数据来源
- 数据来源于 https://huggingface.co/datasets/thepowerfuldeez/the-stack-v2-train-smol-ids-updated
数据处理
- 对所有文件进行了格式化、代码风格检查和导入排序
- 使用工具:
- Python: ruff + black + ty
- JavaScript/TypeScript/HTML/CSS/JSON/GraphQL: biomejs
数据访问
python from datasets import load_dataset ds = load_dataset("thepowerfuldeez/the-stack-v2-train-smol-ids-updated-content", split="train", streaming=True) for row in ds.take(3): print(row)
搜集汇总
数据集介绍
构建方式
在代码数据挖掘领域,该数据集通过系统化采集与精细化处理构建而成。原始数据源自the-stack-v2训练集的代码仓库,采用增量式Parquet分片存储架构,每个分片包含仓库名称和代码文本两个核心字段。数据处理过程中运用了ruff、black与ty工具链对Python代码进行格式化与规范整理,同时采用biomejs工具处理JavaScript、TypeScript及Web相关格式文件,确保了代码风格的统一性与语法规范性。
使用方法
研究人员可通过HuggingFace datasets库以流式传输方式高效加载该数据集。使用load_dataset函数指定数据集名称与训练分割后,即可通过迭代器逐条访问代码样本。这种流式读取方式特别适合处理超大规模数据,避免了本地存储压力。开发者可进一步结合代码处理工具链,对提取的代码文本进行语法解析或嵌入表示,为代码智能领域的模型训练提供高质量数据支撑。
背景与挑战
背景概述
作为代码大数据研究领域的重要资源,the-stack-v2数据集由HuggingFace团队于2023年构建完成,旨在为大规模代码生成与理解模型提供高质量训练语料。该数据集汇聚了来自GitHub等开源平台的数百万个代码仓库,覆盖Python、JavaScript等多种编程语言,为人工智能辅助编程、代码自动补全等前沿研究方向奠定了数据基础。其构建体现了学术界与工业界对代码智能化的共同追求,显著推动了神经程序合成领域的发展进程。
当前挑战
该数据集核心挑战在于解决代码语义理解与跨语言泛化问题,需应对不同编程范式的语法差异和代码上下文的多义性解析。构建过程中面临多重技术难题:需要从海量开源代码中精确识别高质量样本,消除敏感信息和许可证冲突;采用ruff、black等工具进行标准化格式处理时,需保持代码功能完整性;此外,超100亿token规模的分布式存储与流式加载对数据处理管道设计提出了极高要求。
常用场景
经典使用场景
在代码智能研究领域,该数据集作为大规模多语言代码语料库,主要用于训练和评估代码生成模型的性能。研究者通过分析不同编程语言的语法结构和语义特征,能够构建出具备更强泛化能力的代码理解与生成系统,为自动化编程提供数据支撑。
解决学术问题
该数据集有效解决了代码语义理解、跨语言代码迁移和程序合成等核心学术问题。通过提供经过规范化处理的百亿级代码令牌,它为研究代码的统计规律和语义表示奠定了数据基础,显著推动了基于深度学习的程序分析技术的发展。
实际应用
在实际工业场景中,该数据集支撑了智能代码补全、自动化漏洞检测和代码重构工具的开发。企业利用其训练定制化的编程助手,能够提升软件开发效率;同时安全团队可通过分析代码模式识别潜在风险,增强软件系统的可靠性。
数据集最近研究
最新研究方向
在代码大数据驱动的软件工程智能化浪潮中,该数据集作为包含约1000亿标记的大规模多语言代码语料库,正成为大语言模型代码生成与理解任务的核心训练资源。当前研究聚焦于提升模型对复杂代码语义的深层推理能力,结合格式化与静态分析工具实现高质量代码生成,支持跨编程语言的泛化性能优化。相关进展直接推动自动化编程、智能代码审查及软件维护等领域的突破,为构建下一代AI辅助开发系统奠定数据基石。
以上内容由遇见数据集搜集并总结生成


