redmoddata/Knowledge_Pile
收藏Hugging Face2025-12-05 更新2025-12-20 收录
下载链接:
https://hf-mirror.com/datasets/redmoddata/Knowledge_Pile
下载链接
链接失效反馈官方服务:
资源简介:
---
license: apache-2.0
language:
- en
tags:
- knowledge
- Retrieval
- Reasoning
- Common Crawl
- MATH
size_categories:
- 100B<n<1T
---
Knowledge Pile is a knowledge-related data leveraging [Query of CC](https://arxiv.org/abs/2401.14624).
This dataset is a partial of Knowledge Pile(about 40GB disk size), full datasets have been released in [\[🤗 knowledge_pile_full\]](https://huggingface.co/datasets/Query-of-CC/knowledge_pile_full/), a total of 735GB disk size and 188B tokens (using Llama2 tokenizer).
## *Query of CC*
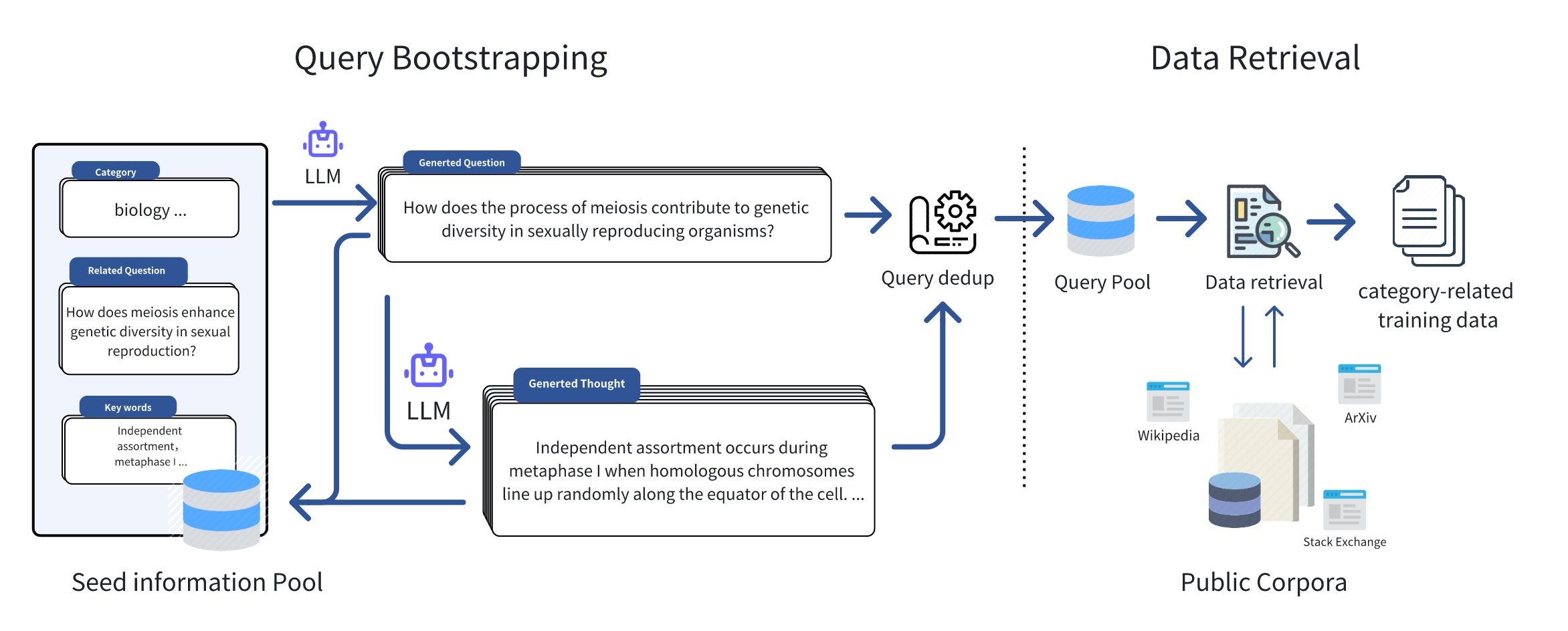
Just like the figure below, we initially collected seed information in some specific domains, such as keywords, frequently asked questions, and textbooks, to serve as inputs for the Query Bootstrapping stage. Leveraging the great generalization capability of large language models, we can effortlessly expand the initial seed information and extend it to an amount of domain-relevant queries. Inspiration from Self-instruct and WizardLM, we encompassed two stages of expansion, namely **Question Extension** and **Thought Generation**, which respectively extend the queries in terms of breadth and depth, for retrieving the domain-related data with a broader scope and deeper thought. Subsequently, based on the queries, we retrieved relevant documents from public corpora, and after performing operations such as duplicate data removal and filtering, we formed the final training dataset.
## **Knowledge Pile** Statistics
Based on *Query of CC* , we have formed a high-quality knowledge dataset **Knowledge Pile**. As shown in Figure below, comparing with other datasets in academic and mathematical reasoning domains, we have acquired a large-scale, high-quality knowledge dataset at a lower cost, without the need for manual intervention. Through automated query bootstrapping, we efficiently capture the information about the seed query. **Knowledge Pile** not only covers mathematical reasoning data but also encompasses rich knowledge-oriented corpora spanning various fields such as biology, physics, etc., enhancing its comprehensive research and application potential.
<img src="https://github.com/ngc7292/query_of_cc/blob/master/images/query_of_cc_timestamp_prop.png?raw=true" width="300px" style="center"/>
This table presents the top 10 web domains with the highest proportion of **Knowledge Pile**, primarily including academic websites, high-quality forums, and some knowledge domain sites. Table provides a breakdown of the data sources' timestamps in **Knowledge Pile**, with statistics conducted on an annual basis. It is evident that a significant portion of **Knowledge Pile** is sourced from recent years, with a decreasing proportion for earlier timestamps. This trend can be attributed to the exponential growth of internet data and the inherent timeliness introduced by the **Knowledge Pile**.
| **Web Domain** | **Count** |
|----------------------------|----------------|
|en.wikipedia.org | 398833 |
|www.semanticscholar.org | 141268 |
|slideplayer.com | 108177 |
|www.ncbi.nlm.nih.gov | 97009 |
|link.springer.com | 85357 |
|www.ipl.org | 84084 |
|pubmed.ncbi.nlm.nih.gov | 68934 |
|www.reference.com | 61658 |
|www.bartleby.com | 60097 |
|quizlet.com | 56752 |
### cite
```
@article{fei2024query,
title={Query of CC: Unearthing Large Scale Domain-Specific Knowledge from Public Corpora},
author={Fei, Zhaoye and Shao, Yunfan and Li, Linyang and Zeng, Zhiyuan and Yan, Hang and Qiu, Xipeng and Lin, Dahua},
journal={arXiv preprint arXiv:2401.14624},
year={2024}
}
```
---
许可证:Apache-2.0
语言:
- 英语
标签:
- 知识
- 检索(Retrieval)
- 推理(Reasoning)
- 通用爬虫(Common Crawl)
- MATH
数据规模区间:
- 1000亿 < Token数量 < 1万亿
---
知识堆(Knowledge Pile)是一类依托[CC查询(Query of CC)](https://arxiv.org/abs/2401.14624)构建的知识相关数据。
本数据集为知识堆(Knowledge Pile)的子集,磁盘占用量约40GB,完整数据集已在[[🤗 knowledge_pile_full]](https://huggingface.co/datasets/Query-of-CC/knowledge_pile_full/)发布,完整数据集磁盘占用总计735GB,包含1880亿个Token,统计时使用Llama2分词器。
## *CC查询(Query of CC)*
正如下图所示,我们最初从部分特定领域收集种子信息,例如关键词、常见问题与教科书内容,将其作为查询引导(Query Bootstrapping)阶段的输入。依托大语言模型(Large Language Model,LLM)的强大泛化能力,我们可以轻松扩展初始种子信息,将其拓展为大量领域相关查询。受Self-instruct与WizardLM的启发,我们涵盖了两轮扩展阶段,分别为**查询拓展(Question Extension)**与**思维生成(Thought Generation)**,二者分别从广度与深度层面拓展查询,以获取覆盖范围更广、思维层次更深的领域相关数据。随后,我们基于这些查询从公开语料库中检索相关文档,经过去重、筛选等操作后,形成最终的训练数据集。

## **知识堆(Knowledge Pile)** 统计信息
基于CC查询(Query of CC),我们构建了高质量知识数据集**知识堆(Knowledge Pile)**。如下图所示,相较于学术与数学推理领域的其他数据集,我们以更低成本打造了大规模高质量知识数据集,且无需人工干预。通过自动化的查询引导流程,我们高效捕获了种子查询相关信息。**知识堆(Knowledge Pile)**不仅涵盖数学推理数据,还包含生物学、物理学等多个领域的丰富知识导向语料,提升了其综合研究与应用潜力。

下表展示了**知识堆(Knowledge Pile)**中占比最高的前10个Web域名,主要包括学术网站、高质量论坛与部分知识领域站点。表格同时统计了知识堆中各数据源的时间戳分布,按年度进行划分。显而易见,知识堆的大量数据来源于近年,早期时间戳的数据占比逐渐降低。这一趋势可归因于互联网数据的指数级增长,以及知识堆本身具备的固有时效性。
| **Web域名** | **数量** |
|----------------------------|----------------|
|en.wikipedia.org | 398833 |
|www.semanticscholar.org | 141268 |
|slideplayer.com | 108177 |
|www.ncbi.nlm.nih.gov | 97009 |
|link.springer.com | 85357 |
|www.ipl.org | 84084 |
|pubmed.ncbi.nlm.nih.gov | 68934 |
|www.reference.com | 61658 |
|www.bartleby.com | 60097 |
|quizlet.com | 56752 |
### 引用
@article{fei2024query,
title={Query of CC: Unearthing Large Scale Domain-Specific Knowledge from Public Corpora},
author={Fei, Zhaoye and Shao, Yunfan and Li, Linyang and Zeng, Zhiyuan and Yan, Hang and Qiu, Xipeng and Lin, Dahua},
journal={arXiv preprint arXiv:2401.14624},
year={2024}
}
提供机构:
redmoddata


