SPEED+
收藏arXiv2021-12-10 更新2024-06-21 收录
下载链接:
https://kelvins.esa.int/pose-estimation-2021/
下载链接
链接失效反馈官方服务:
资源简介:
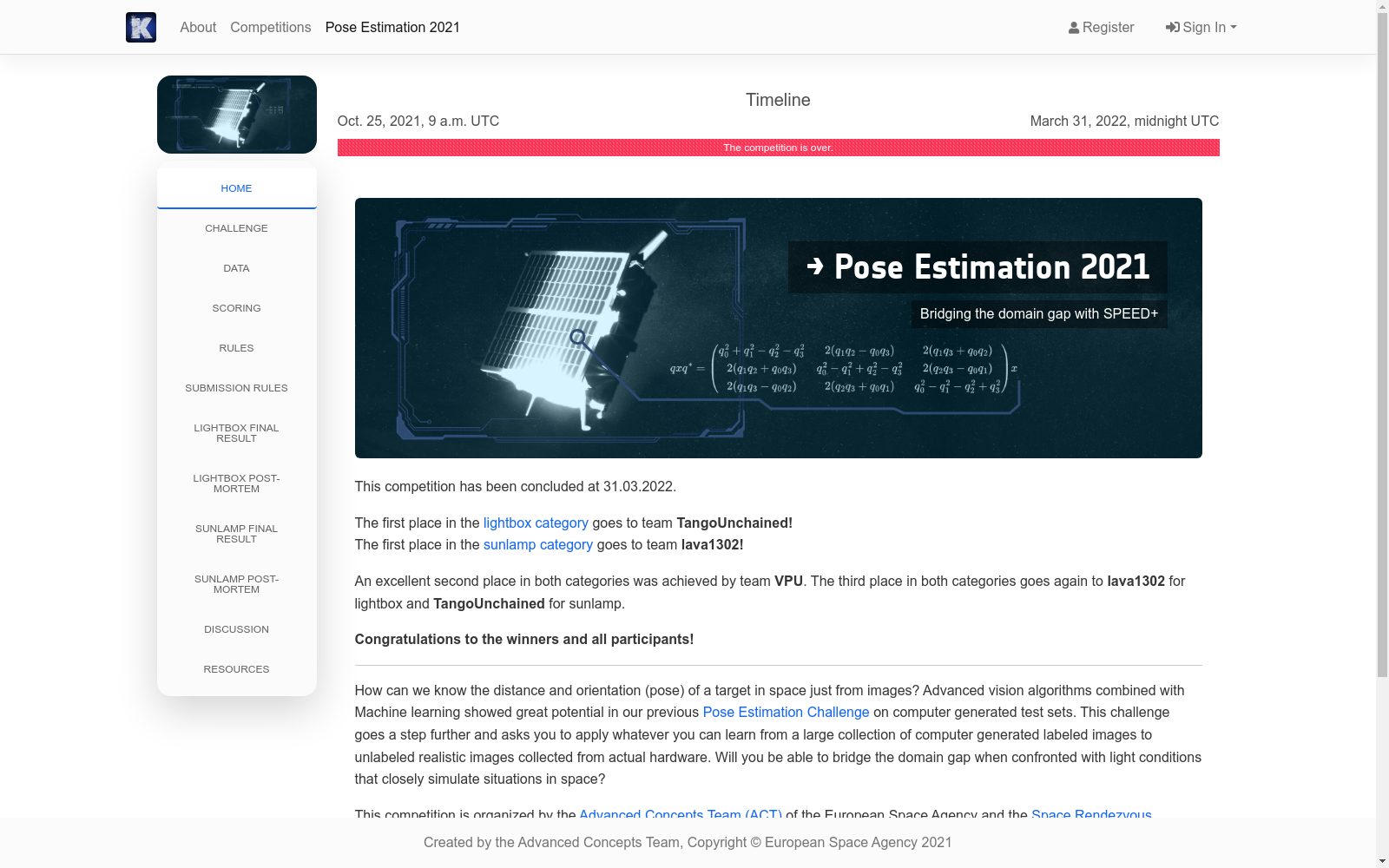
SPEED+是斯坦福大学航空航天系开发的下一代航天器姿态估计数据集,专注于跨领域差距。该数据集包含60,000张合成图像用于训练,以及9,531张硬件在环图像,这些图像是从TRON设施捕获的航天器模型。TRON是一个独特的机器人测试平台,能够捕获任意数量的目标图像,并提供准确且多样化的姿态标签以及高保真的航天器光照条件。SPEED+用于第二届国际卫星姿态估计挑战赛,旨在评估和比较基于合成图像训练的航天器机器学习模型的鲁棒性。数据集的应用领域包括未来的轨道服务和空间物流任务,旨在解决非合作目标的姿态确定和跟踪问题。
SPEED+ is a next-generation spacecraft attitude estimation dataset developed by the Department of Aeronautics and Astronautics of Stanford University, focusing on cross-domain gaps. This dataset contains 60,000 synthetic images for training, and 9,531 hardware-in-the-loop images of spacecraft models captured from the TRON facility. TRON is a unique robotic testbed that can capture an arbitrary number of target images, while providing accurate and diverse attitude labels as well as high-fidelity spacecraft lighting conditions. SPEED+ was used in the 2nd International Satellite Attitude Estimation Challenge, aiming to evaluate and compare the robustness of spacecraft machine learning models trained on synthetic images. The application domains of this dataset cover future on-orbit servicing and space logistics missions, aiming to address the issues of attitude determination and tracking for non-cooperative targets.
提供机构:
斯坦福大学航空航天系
创建时间:
2021-10-07
搜集汇总
数据集介绍
构建方式
SPEED+数据集的构建采用了合成图像与硬件在环(HIL)图像相结合的方式。首先,通过OpenGL光学模拟器生成了59,960张合成图像,用于训练卷积神经网络(CNN)模型。其次,利用斯坦福大学空间交会实验室(SLAB)的TRON设施,生成了9,531张HIL图像,这些图像通过高保真的空间光照条件模拟了真实的空间环境。TRON设施通过机器人臂和精确的位姿标签生成系统,确保了图像的高质量和多样性。
特点
SPEED+数据集的特点在于其强调域间差距(domain gap)的挑战性。除了大量的合成图像外,SPEED+还包含了两种不同光照条件下的HIL图像:lightbox和sunlamp。这些HIL图像捕捉了真实空间环境中的光照变化、阴影和反射等复杂视觉特征,提供了比合成图像更具挑战性的测试场景。此外,SPEED+的HIL图像覆盖了完整的位姿空间和距离范围,能够全面评估空间机器学习模型在不同环境条件下的鲁棒性。
使用方法
SPEED+数据集主要用于训练和评估空间机器学习模型,特别是在域间差距下的鲁棒性。用户可以使用合成图像进行模型训练,并通过HIL图像进行测试,以验证模型在真实空间环境中的表现。此外,SPEED+还被用于第二届国际卫星位姿估计挑战赛(SPEC2021),参赛者可以通过该数据集开发和比较不同模型的性能。数据集的使用方法包括加载图像和位姿标签,进行数据预处理,并应用各种机器学习算法进行训练和测试。
背景与挑战
背景概述
SPEED+数据集是由斯坦福大学和欧洲空间局先进概念团队联合开发的下一代航天器姿态估计数据集,旨在解决空间环境中视觉导航的领域差距问题。该数据集于2021年发布,主要研究人员包括Tae Ha Park、Marcus Märtens、Gurvan Lecuyer、Dario Izzo和Simone D’Amico。SPEED+的核心研究问题是通过合成图像和硬件在环(HIL)图像的结合,提升航天器姿态估计的鲁棒性,特别是在未来在轨服务和空间物流任务中的应用。该数据集不仅包含60,000张合成图像用于训练,还提供了9,531张通过TRON设施捕获的HIL图像,这些图像具有高保真的空间光照条件。SPEED+的发布推动了空间视觉导航领域的研究,尤其是在机器学习和计算机视觉技术的应用方面。
当前挑战
SPEED+数据集面临的挑战主要体现在两个方面。首先,领域差距问题(domain gap)是其主要挑战之一,即合成图像与真实空间图像之间的视觉特征和光照条件差异较大,导致基于合成数据训练的模型在真实空间图像上的性能显著下降。其次,数据集的构建过程中也面临诸多挑战,例如如何在实验室环境中模拟高保真的空间光照条件,以及如何确保HIL图像的姿态标签的精确性。此外,由于空间环境的复杂性和不可预测性,获取大规模的真实空间图像及其精确标签极为困难,这使得SPEED+的HIL图像成为验证模型鲁棒性的重要替代方案。尽管如此,如何进一步缩小合成图像与HIL图像之间的领域差距,仍然是未来研究的关键挑战。
常用场景
经典使用场景
SPEED+数据集在航天器姿态估计领域具有广泛的应用,尤其是在自主视觉导航任务中。该数据集通过提供大量合成图像和硬件在环(HIL)图像,为训练和验证机器学习模型提供了丰富的资源。其经典使用场景包括在轨服务任务中的非合作目标航天器的姿态估计,如空间资产加油和主动碎片清除任务。SPEED+的HIL图像通过高保真的空间环境模拟,能够有效评估模型在真实空间环境中的鲁棒性。
衍生相关工作
SPEED+数据集衍生了许多相关的研究工作,尤其是在航天器姿态估计和域适应领域。基于SPEED+,研究人员开发了多种卷积神经网络(CNN)模型,如关键点回归网络(KRN)和航天器姿态网络(SPN),并探索了域适应和域随机化算法以提升模型的鲁棒性。此外,SPEED+还被用于国际卫星姿态估计挑战赛(SPEC2021),推动了学术界和工业界在空间视觉导航领域的合作与创新。这些工作不仅提升了航天器姿态估计的精度,还为未来的空间任务提供了技术储备。
数据集最近研究
最新研究方向
SPEED+数据集作为下一代航天器姿态估计数据集,专注于解决合成图像与真实空间图像之间的领域差距问题。该数据集不仅包含60,000张合成图像用于训练,还引入了9,531张通过硬件在环(HIL)技术捕获的航天器模型图像,这些图像在TRON设施中生成,模拟了高保真的空间光照条件。SPEED+的发布为航天器自主导航和姿态估计领域的研究提供了重要的数据支持,特别是在未来在轨服务、空间物流和碎片清除任务中,精确的姿态估计技术至关重要。通过SPEED+,研究人员能够更好地评估和提升机器学习模型在跨领域场景中的鲁棒性,推动空间视觉导航技术的发展。
相关研究论文
- 1SPEED+: Next-Generation Dataset for Spacecraft Pose Estimation across Domain Gap斯坦福大学航空航天系 · 2021年
以上内容由遇见数据集搜集并总结生成


