UrduMedIQ-Urdu-Medical-Intelligence-Questions
收藏Hugging Face2025-04-09 更新2025-04-10 收录
下载链接:
https://huggingface.co/datasets/iimran/UrduMedIQ-Urdu-Medical-Intelligence-Questions
下载链接
链接失效反馈官方服务:
资源简介:
UrduMed-Grok3-可验证数据集是一个高质量的乌尔都语医学推理数据集,它从Medical-O1-可验证问题中提炼而来,并使用Grok-3进行了优化。这个数据集适用于训练乌尔都语医学语言模型,减少AI在诊断中的虚构情况,并弥合非英语医学AI的鸿沟。数据集包含了经过专家翻译和精炼的医学问题,涵盖了诊断、治疗协议和病理学解释等领域,并为每个问题提供了可验证的参考答案和逐步推理过程。数据集规格包括10814个问题,适用于多种AI训练场景。
UrduMed-Grok3 Verifiable Dataset is a high-quality Urdu medical reasoning dataset derived from Medical-O1 verifiable questions and optimized with Grok-3. This dataset is designed for training Urdu medical language models, reducing AI-generated hallucinations in diagnostic scenarios, and bridging the gap in non-English medical AI. The dataset contains expertly translated and refined medical questions covering domains such as diagnostics, treatment protocols, and pathological explanations, with verifiable reference answers and step-by-step reasoning processes provided for each question. It includes 10,814 questions and is suitable for various AI training scenarios.
创建时间:
2025-04-08
搜集汇总
数据集介绍
构建方式
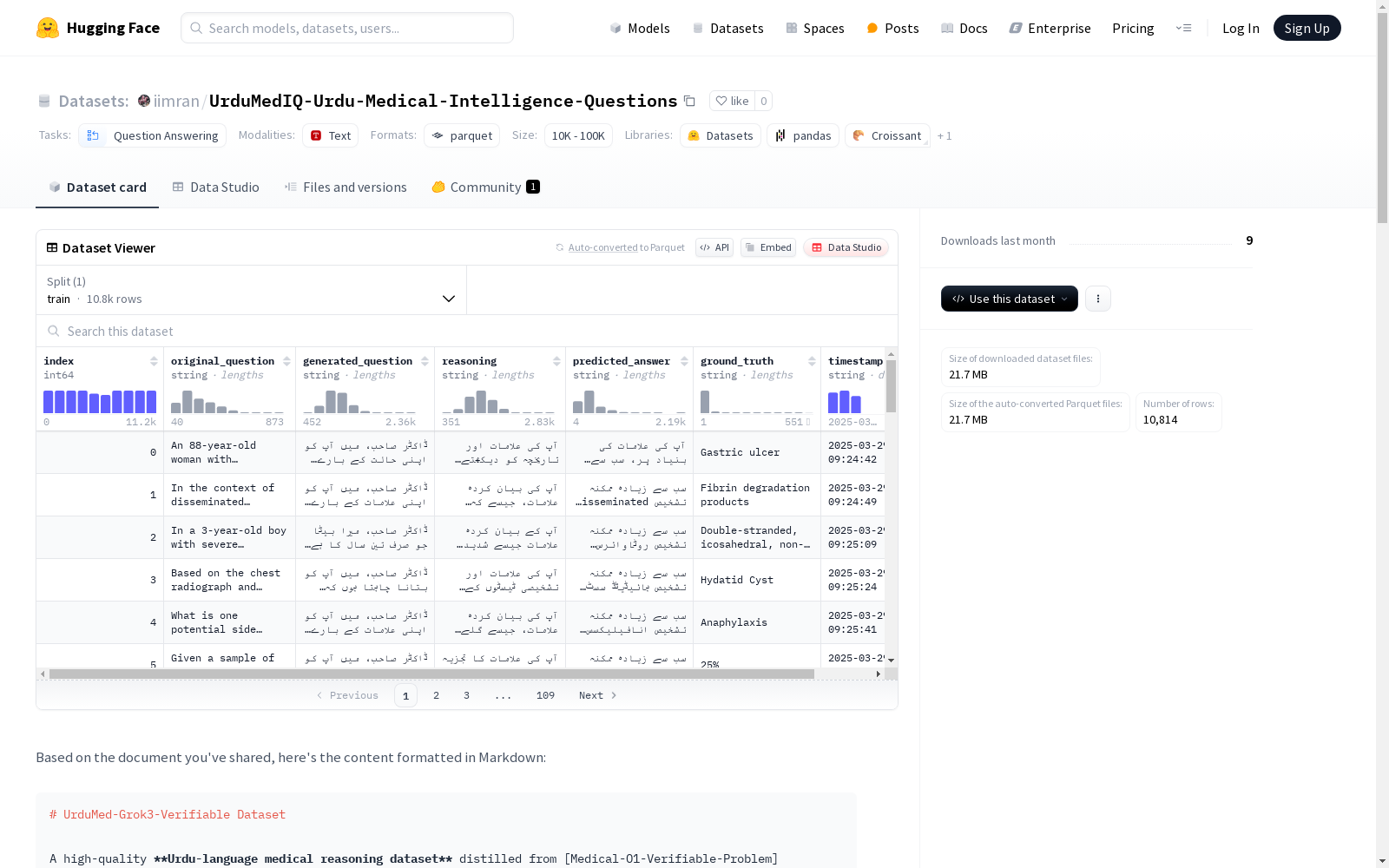
在医学人工智能领域,高质量的非英语数据集对于提升语言模型的临床推理能力至关重要。UrduMedIQ数据集通过先进的Grok-3模型,从英文医学数据集Medical-O1-Verifiable-Problem中蒸馏转化而来,确保了医学知识的准确性和文化适应性。构建过程中特别注重保留原始医学问题的严谨性,同时将其转化为符合乌尔都语医疗语境的专业表达。数据集包含10814个经过严格筛选的医学问题,每个问题都经过专家级翻译和医学验证,确保了内容的可靠性和专业性。
特点
作为乌尔都语医学智能领域的标杆性资源,该数据集展现出多维度优势。其核心价值在于精心设计的医学问题体系,涵盖诊断学、治疗方案和病理机制等关键临床领域。每个问题均配备可验证的标准答案和分步推理过程,为模型训练提供了可靠的基准参考。特别值得注意的是,数据集通过Grok-3的优化处理,完美保留了医学术语的专业性,同时确保乌尔都语表达的流畅自然。这种独特的组合使其成为提升乌尔都语医疗AI诊断准确性的理想训练素材。
使用方法
在具体应用层面,该数据集为乌尔都语医疗AI开发提供了标准化解决方案。研究人员可通过HuggingFace平台直接加载数据集,快速构建医疗问答系统或诊断辅助工具。数据集的结构化设计支持多种应用场景:既可作为微调乌尔都语大语言模型的训练素材,也能用于评估医疗AI的临床推理能力。典型应用包括开发症状自查助手、构建患者教育系统,以及支持资源匮乏地区的远程医疗项目。数据集的标准化格式确保了与主流机器学习框架的无缝对接,为乌尔都语医疗AI研究提供了即插即用的解决方案。
背景与挑战
背景概述
UrduMedIQ-Urdu-Medical-Intelligence-Questions数据集由Imran Sarwar和Muhammad Rouf Mustafa于2025年发布,旨在填补非英语医学人工智能领域的空白。该数据集基于Medical-O1-Verifiable-Problem,通过Grok-3技术蒸馏而成,专注于提升乌尔都语大型语言模型在临床推理和诊断准确性方面的表现。其核心研究问题围绕如何在低资源语言环境中实现高质量的医学问答系统,涵盖了诊断、治疗方案和病理解释等多个医学子领域。该数据集的发布为乌尔都语医学人工智能的发展提供了重要资源,特别是在改善乌尔都语地区的医疗可及性和教育工具方面具有显著影响力。
当前挑战
UrduMedIQ数据集面临的主要挑战包括医学术语的准确翻译与保留,确保在语言转换过程中不损失原始医学问题的专业性和严谨性。构建过程中需克服乌尔都语医学语料稀缺的问题,同时保持文化相关性以适应乌尔都语医疗环境。此外,数据集的验证性要求每个问题配备基于医学考试或文献的参考答案,这对数据收集和标注提出了高标准。在应用层面,如何有效利用该数据集训练乌尔都语医学大型语言模型,并减少诊断中的幻觉现象,仍是当前研究的重点挑战。
常用场景
经典使用场景
UrduMedIQ数据集作为乌尔都语医学智能问答的标杆资源,其经典使用场景聚焦于提升语言模型在临床推理任务中的表现。通过精心设计的诊断性问题与治疗方案询问,该数据集能够系统性地评估模型对南亚地区常见病症的理解深度,例如糖尿病并发症或高血压禁忌症的判断。医学教育领域常将其作为模拟诊疗平台的核心语料,帮助乌尔都语医学生通过AI交互强化病例分析能力。
解决学术问题
该数据集有效解决了非英语医学AI研究中的关键瓶颈问题。针对乌尔都语医学术语标准化缺失的现状,其通过Grok-3优化的术语蒸馏技术建立了可靠的评估基准。在可解释性医疗AI领域,数据集提供的分步推理答案为研究黑箱模型的决策逻辑提供了珍贵参照。更重要的是,它填补了低资源语言在循证医学知识表示方面的研究空白,为跨语言医疗知识迁移建立了范式。
衍生相关工作
该数据集已催生多个里程碑式研究,包括乌尔都语首个医学专用大模型U-LLaMA的开发。其基准测试框架被AdaptUrduMed项目扩展为涵盖12种南亚方言的评估体系。在跨模态研究方面,学者结合该数据集的临床问答数据与本地医学影像库,构建了首个乌尔都语多模态诊断系统。近期工作MedQA-Urdu更通过知识蒸馏技术,将数据集的医学逻辑迁移至基础教育领域。
以上内容由遇见数据集搜集并总结生成


