ASVspoofLD
收藏Hugging Face2024-12-01 更新2024-12-12 收录
下载链接:
https://huggingface.co/datasets/hashim19/ASVspoofLD
下载链接
链接失效反馈官方服务:
资源简介:
ASVspoof Laundered Database是一个基于ASVspoof 2019逻辑访问(LA)评估分区的数据集,经过多种噪声和信号处理技术处理,总计1388.22小时的音频数据。数据集包含音频文件和协议文件,详细描述了每种洗钱攻击的参数。
The ASVspoof Laundered Database is a dataset based on the logical access (LA) evaluation partition of ASVspoof 2019. It has been processed with various noise and signal processing techniques, with a total of 1388.22 hours of audio data. The dataset includes audio files and protocol files that elaborate on the parameters of each laundering attack.
创建时间:
2024-11-26
原始信息汇总
ASVspoof Laundered Database
数据集概述
- 数据集名称: ASVspoof Laundered Database
- 数据集类型: 音频数据集
- 数据集来源: 基于ASVspoof 2019逻辑访问(LA)评估分区
- 数据集大小: 1388.22小时
- 数据集格式: FLAC
- 数据集创建者: Hashim Ali, Surya Subramani, Shefali Sudhir, Raksha Varahamurthy, Hafiz Malik
- 数据集联系人: Hashim Ali (alhashim@umich.edu)
- 数据集创建日期: 2024年5月29日
数据集内容
-
特征:
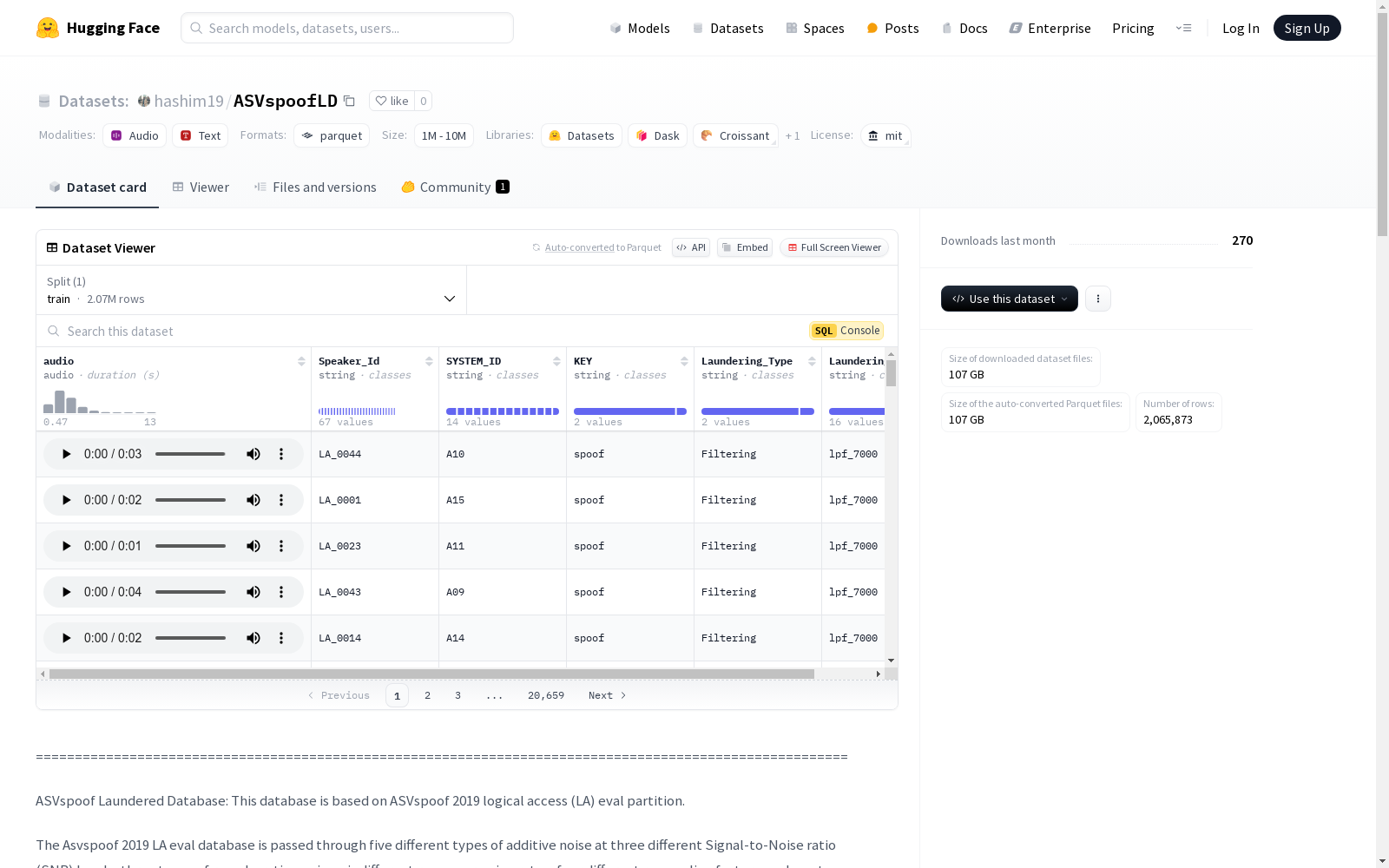
Speaker_Id: 说话者ID,字符串类型audio: 音频文件,音频类型SYSTEM_ID: 语音欺骗系统ID,字符串类型KEY: 语音类型(bonafide或spoof),字符串类型Laundering_Type: 清洗攻击类型,字符串类型Laundering_Param: 清洗攻击参数,字符串类型
-
数据集划分:
train: 训练集,包含213711个样本,大小为13156475352.626字节
-
数据集配置:
default: 默认配置,训练集数据路径为data/train-*
数据集结构
- 目录结构:
ASVspoofLauneredDatabase/:flac/: 包含所有音频文件protocols/: 包含五个协议文件,每个文件对应一种清洗攻击Readme.txt: 数据集说明文件
数据集描述
-
音频文件描述:
- 包含五种清洗攻击类型:Noise_Addition, Reverberation, Recompression, Resampling, Filtering
- 每种攻击类型有不同的参数,具体参数在协议文件中描述
-
协议文件描述:
- 每个协议文件包含以下列:
SPEAKER_ID: 说话者IDAUDIO_FILE_NAME: 音频文件名SYSTEM_ID: 语音欺骗系统IDKEY: 语音类型Laundering_Type: 清洗攻击类型Laundering_Param: 清洗攻击参数
- 每个协议文件包含以下列:
数据集警告
flac文件夹包含超过200万个文件,打开时需谨慎
引用
@inproceedings{ali2024audio, title={Is Audio Spoof Detection Robust to Laundering Attacks?}, author={Ali, Hashim and Subramani, Surya and Sudhir, Shefali and Varahamurthy, Raksha and Malik, Hafiz}, booktitle={Proceedings of the 2024 ACM Workshop on Information Hiding and Multimedia Security}, pages={283--288}, year={2024} }
搜集汇总
数据集介绍
构建方式
ASVspoofLD数据集基于ASVspoof 2019逻辑访问(LA)评估分区构建,通过将原始音频数据经过五种不同类型的加性噪声(在三种不同的信噪比水平下)、三种类型的混响噪声、六种不同的再压缩率、四种不同的重采样因子和一种低通滤波处理,最终生成了总计1388.22小时的音频数据。每种处理方式都有特定的参数设置,如噪声类型和信噪比,这些参数在协议文件中详细记录,确保了数据集的多样性和复杂性。
特点
ASVspoofLD数据集的显著特点在于其广泛的处理多样性和详细的参数记录。数据集包含了多种攻击类型,如噪声添加、混响、再压缩、重采样和滤波,每种攻击类型都有多个参数变体,使得数据集能够全面评估音频欺骗检测系统的鲁棒性。此外,数据集的音频文件以FLAC格式存储,保证了音频质量的同时也便于处理和分析。
使用方法
ASVspoofLD数据集主要用于评估和提升音频欺骗检测系统的性能。用户可以通过加载数据集中的音频文件和协议文件,进行模型训练和测试。协议文件详细记录了每段音频的攻击类型和参数,便于研究人员针对特定攻击类型进行深入分析。数据集的多样性和复杂性使其成为开发和验证音频欺骗检测算法的重要资源。
背景与挑战
背景概述
ASVspoofLD数据集基于ASVspoof 2019逻辑访问(LA)评估分区构建,由Hashim Ali、Surya Subramani、Shefali Sudhir、Raksha Varahamurthy和Hafiz Malik等研究人员于2024年创建。该数据集的核心研究问题在于评估音频欺骗检测系统在面对多种音频处理攻击(如噪声添加、混响、重新压缩、重采样和低通滤波)时的鲁棒性。通过将原始音频数据通过五种不同的噪声类型、三种信噪比水平、三种混响噪声、六种重新压缩率和四种重采样因子进行处理,ASVspoofLD数据集积累了总计1388.22小时的音频数据,旨在为音频欺骗检测领域的研究提供丰富的实验资源。
当前挑战
ASVspoofLD数据集在构建过程中面临多项挑战。首先,如何模拟多种复杂的音频处理攻击,并确保这些攻击的真实性和多样性,是一个技术难题。其次,数据集的规模庞大,包含超过200万条音频文件,这不仅对存储和处理资源提出了高要求,还增加了数据管理的复杂性。此外,如何确保数据集的标注准确性和一致性,尤其是在处理多种参数组合的攻击类型时,也是一个重要的挑战。最后,该数据集的应用场景主要集中在音频欺骗检测领域,如何评估和提升检测系统的鲁棒性,尤其是在面对复杂多变的攻击手段时,仍然是一个亟待解决的问题。
常用场景
经典使用场景
ASVspoofLD数据集在语音欺骗检测领域中具有经典应用,主要用于评估和提升语音识别系统对各种音频处理攻击的鲁棒性。通过模拟五种不同的音频处理攻击(如噪声添加、混响、重新压缩、重采样和低通滤波),该数据集为研究人员提供了一个全面的测试平台,以验证其算法在面对复杂音频攻击时的表现。
解决学术问题
ASVspoofLD数据集解决了语音识别系统在面对复杂音频处理攻击时的鲁棒性问题。通过提供多种攻击类型和参数设置,该数据集帮助研究人员深入理解不同攻击对语音信号的影响,从而开发出更加鲁棒的语音识别和欺骗检测算法。这不仅提升了语音识别系统的安全性,也为相关领域的研究提供了宝贵的实验数据。
衍生相关工作
基于ASVspoofLD数据集,许多研究工作得以展开,包括但不限于开发新的语音欺骗检测算法、优化现有的语音识别模型以及探索不同音频处理攻击对语音信号的影响。这些研究不仅推动了语音识别技术的发展,也为相关领域的学术研究和工业应用提供了重要的理论和实践基础。
以上内容由遇见数据集搜集并总结生成


