M3SciQA
收藏Hugging Face2024-10-25 更新2024-12-12 收录
下载链接:
https://huggingface.co/datasets/yale-nlp/M3SciQA
下载链接
链接失效反馈官方服务:
资源简介:
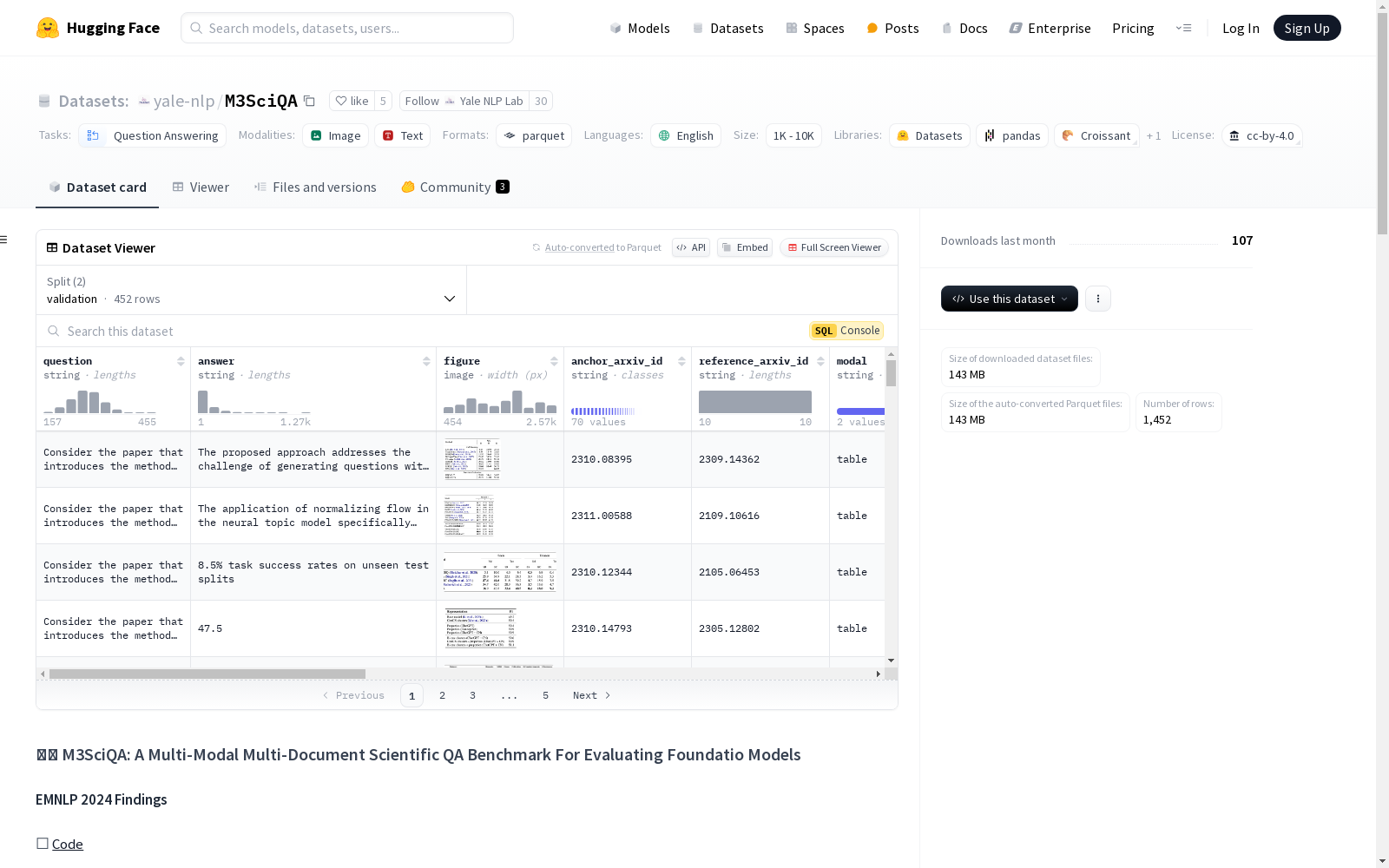
M3SciQA是一个多模态多文档科学问答基准,旨在更全面地评估基础模型。该数据集包含1,452个专家注释的问题,涵盖70个自然语言处理(NLP)论文集群,每个集群代表一篇主要论文及其所有引用的文档。数据集的特征包括问题、答案、图像、arXiv ID、模态类型、推理类型等。数据集分为测试集和验证集,分别包含1000个和452个样本。
M3SciQA is a multimodal, multi-document scientific question answering benchmark developed to enable more comprehensive evaluation of foundation models. This dataset contains 1,452 expert-annotated questions across 70 natural language processing (NLP) paper clusters, where each cluster consists of a primary paper and all its cited documents. The dataset includes data fields such as questions, answers, images, arXiv IDs, modality types, and reasoning types. It is split into a test set and a validation set, with 1,000 and 452 samples respectively.
提供机构:
Yale NLP Lab
创建时间:
2024-10-24
原始信息汇总
M3SciQA 数据集概述
基本信息
- 许可证: CC-BY-4.0
- 配置:
- 默认配置:
- 测试集:
data/test-* - 验证集:
data/validation-*
- 测试集:
- 默认配置:
- 数据集大小: 277,117,259 字节
- 下载大小: 142,739,811 字节
数据集特征
- 问题: 字符串
- 答案: 字符串
- 图表: 图像
- 锚点arXiv ID: 字符串
- 参考arXiv ID: 字符串
- 模态: 字符串
- 锚点推理类型: 字符串
- 参考推理类型: 字符串
- 问题锚点: 字符串
- 答案锚点: 字符串
- 问题参考: 字符串
- 参考解释: 字符串
- 参考证据: 字符串
数据集分割
- 测试集:
- 样本数: 1,000
- 字节数: 186,652,601
- 验证集:
- 样本数: 452
- 字节数: 90,464,658
任务类别
- 问答
数据集规模
- 1K < n < 10K
搜集汇总
数据集介绍
构建方式
M3SciQA数据集的构建旨在填补科学领域多模态、多文档问答基准的空白。该数据集由专家标注的1,452个问题组成,涵盖了70个自然语言处理(NLP)论文集群。每个集群包括一篇主论文及其所有引用文献,模拟了科学研究中理解单篇论文所需的跨文档和多模态数据处理流程。数据集的构建过程严格遵循科学研究的复杂性,确保问题能够全面评估模型在多模态信息检索和跨文档推理方面的能力。
特点
M3SciQA数据集的特点在于其多模态和多文档的特性。每个问题不仅涉及文本信息,还包含图像数据,如论文中的图表。此外,数据集中的问题设计充分考虑了科学研究的实际需求,要求模型能够从多个文档中提取和整合信息。数据集还提供了详细的元数据,包括问题与答案的关联、推理类型以及参考文献信息,为模型的全面评估提供了丰富的上下文。
使用方法
M3SciQA数据集的使用方法主要围绕对基础模型的评估展开。研究人员可以通过该数据集测试模型在多模态信息检索和跨文档推理任务中的表现。数据集提供了测试集和验证集,分别包含1,000个和452个样本,用户可以根据需要选择相应的数据集进行实验。此外,数据集还提供了详细的评估指标和结果分析工具,帮助研究人员深入理解模型在不同任务中的性能差异,并为未来模型的改进提供参考。
背景与挑战
背景概述
M3SciQA数据集由耶鲁大学自然语言处理团队于2024年发布,旨在为科学领域的基础模型提供多模态、多文档的问答评估基准。该数据集聚焦于科学研究的复杂工作流程,涵盖70个自然语言处理论文集群,每个集群包括一篇主论文及其所有引用文献。M3SciQA的构建基于专家标注的1452个问题,涉及文本、图像等多种模态,旨在模拟科研人员在多文档和多模态数据中进行信息检索和推理的实际场景。该数据集的发布为评估和改进基础模型在科学领域的表现提供了重要工具,推动了多模态科学问答研究的发展。
当前挑战
M3SciQA数据集面临的挑战主要体现在两个方面。首先,科学领域的多模态和多文档问答任务本身具有较高的复杂性,要求模型不仅能够理解文本信息,还需具备处理图像、表格等非文本数据的能力,并在多文档之间进行有效的信息整合与推理。其次,在数据集的构建过程中,如何确保专家标注的准确性和一致性,以及如何平衡不同模态和文档之间的信息分布,都是需要克服的技术难题。这些挑战不仅反映了当前基础模型在科学领域的局限性,也为未来模型的优化和改进指明了方向。
常用场景
经典使用场景
M3SciQA数据集在科学研究和自然语言处理领域中被广泛应用于评估基础模型的多模态和多文档理解能力。通过提供包含文本、图像和跨文档引用的复杂问题,该数据集能够模拟真实的科研工作流程,帮助研究者测试模型在处理多源信息时的表现。
衍生相关工作
基于M3SciQA数据集,研究者们开发了一系列改进的基础模型和多模态融合方法。例如,一些工作专注于提升模型在图像和文本联合理解中的表现,而另一些研究则探索了跨文档推理的新算法,进一步推动了科学问答领域的技术发展。
数据集最近研究
最新研究方向
在科学研究的复杂背景下,M3SciQA数据集为多模态、多文档的科学问答任务提供了全新的评估基准。该数据集通过整合文本与图像信息,并跨越多个科学文献进行信息检索与推理,显著提升了基础模型在科学领域的应用能力。当前研究热点集中在如何优化模型在处理多模态数据时的表现,特别是在图像与文本的联合理解方面。此外,跨文档推理能力的提升也成为研究焦点,旨在通过更复杂的任务设计,推动模型在科学文献中的深度理解与信息整合。M3SciQA的出现不仅填补了现有基准的不足,还为未来基础模型的发展提供了重要的参考方向,推动了科学问答系统向更高层次的智能化迈进。
以上内容由遇见数据集搜集并总结生成


