moroccan-lawQA-dataset
收藏Hugging Face2025-06-16 更新2025-06-17 收录
下载链接:
https://huggingface.co/datasets/ilyassacha/moroccan-lawQA-dataset
下载链接
链接失效反馈官方服务:
资源简介:
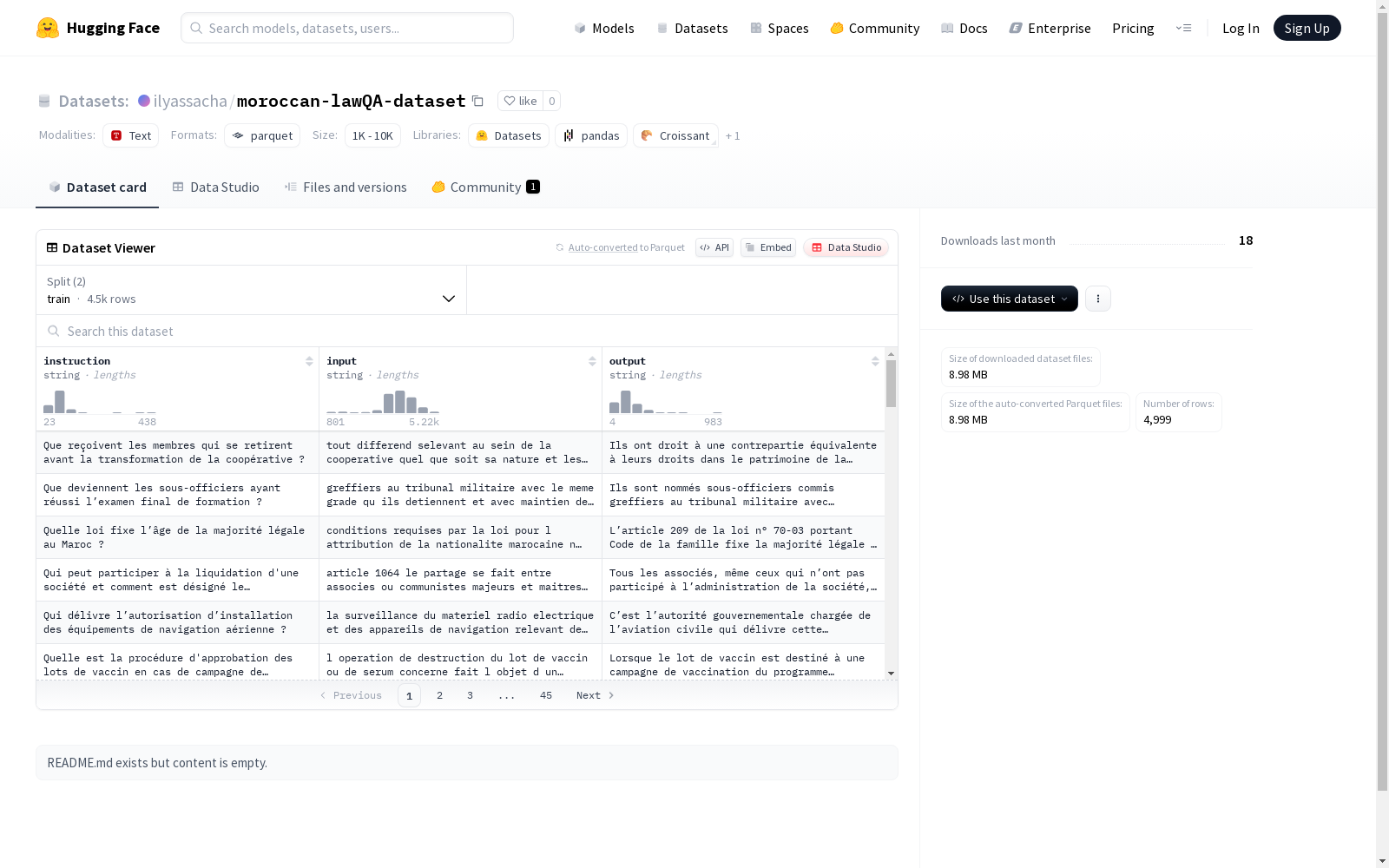
该数据集包含指令、输入和输出三个字段,均为文本格式。数据集分为训练集和评估集,训练集包含4499个示例,评估集包含500个示例。数据集总大小约为19249MB,下载大小约为8977MB。
This dataset includes three fields: instruction, input, and output, all in text format. It is split into a training set and an evaluation set, which contain 4499 examples and 500 examples respectively. The total size of the dataset is approximately 19249 MB, while its download size is around 8977 MB.
创建时间:
2025-06-14
原始信息汇总
数据集概述
基本信息
- 数据集名称: moroccan-lawQA-dataset
- 下载大小: 8,976,970 字节
- 数据集大小: 19,249,018 字节
数据集结构
特征
- instruction: 字符串类型
- input: 字符串类型
- output: 字符串类型
数据划分
- train
- 样本数量: 4,499
- 数据大小: 17,323,731.142628524 字节
- eval
- 样本数量: 500
- 数据大小: 1,925,286.8573714744 字节
配置文件
- 默认配置
- train: data/train-*
- eval: data/eval-*
搜集汇总
数据集介绍
构建方式
在摩洛哥法律问答领域,该数据集通过系统化的数据采集与标注流程构建而成。研究人员从权威法律文本、司法判例和常见法律咨询问题中提取原始素材,采用结构化模板将每项数据规范化为instruction-input-output三元组形式。训练集包含4499个样本,评估集500个样本,通过专业法律人士的交叉验证确保问答对的准确性与权威性。
使用方法
使用本数据集时建议采用分层抽样策略,充分利用训练集进行模型微调。eval子集适用于法律文本理解任务的性能评估,可通过计算法条引用准确率等专业指标衡量模型表现。数据处理过程中应注意保留原始文本的法律术语特征,建议结合摩洛哥民法典进行跨验证,确保法律解释的合规性。
背景与挑战
背景概述
摩洛哥法律问答数据集(moroccan-lawQA-dataset)是针对摩洛哥法律领域构建的专业问答数据集,旨在为自然语言处理技术在法律咨询和司法辅助领域的应用提供支持。该数据集由相关研究机构或团队精心构建,涵盖了丰富的法律条文解释、案例分析和实务问答内容,反映了摩洛哥法律体系的特点和复杂性。其构建不仅填补了阿拉伯语法律问答数据资源的空白,也为跨语言法律智能系统的开发奠定了基础,对推动法律人工智能在摩洛哥及周边地区的应用具有重要意义。
当前挑战
该数据集面临的挑战主要体现在两个方面:领域问题的挑战方面,摩洛哥法律体系兼具大陆法系和伊斯兰法系特征,法律条文解释和案例判决存在高度专业性,要求模型具备准确理解复杂法律概念和条文关联的能力;构建过程的挑战方面,法律数据的敏感性和隐私性导致数据获取困难,同时阿拉伯语的法律术语标准化程度不足,且摩洛哥方言与标准阿拉伯语存在差异,增加了数据标注和清洗的难度。此外,确保问答对的法律准确性和时效性也对数据维护提出了较高要求。
常用场景
经典使用场景
在摩洛哥法律体系智能化研究的背景下,moroccan-lawQA-dataset为法律问答系统的开发提供了关键支持。该数据集通过结构化的问题-答案对,为研究人员构建基于自然语言处理的法律咨询模型奠定了数据基础,特别适用于训练能够理解阿拉伯语和法语混合法律术语的AI系统。
解决学术问题
该数据集有效解决了法律领域多语言处理与专业术语理解的学术难题。通过提供标准化的法律问答样本,研究者能够突破传统法律文本分析的局限性,探索跨语言法律知识表示的创新方法,对提升伊斯兰法系国家的司法信息化水平具有显著意义。
实际应用
在实际应用中,该数据集支撑了摩洛哥司法系统的数字化转型。基于该数据集开发的智能法律助手已在政府门户网站部署,为公民提供24小时在线的婚姻继承、商业合同等常见法律问题的自动解答服务,显著降低了法律咨询的门槛。
数据集最近研究
最新研究方向
在摩洛哥法律智能问答领域,moroccan-lawQA-dataset的推出为阿拉伯语法律文本处理开辟了新路径。该数据集以指令-输入-输出的三元结构为核心,正推动法律知识图谱构建与生成式AI的交叉研究。近期学者们聚焦于如何将此类本土化数据集与Llama、ChatGLM等大语言模型适配,解决伊斯兰法系与大陆法系混合背景下法律条款的多义性问题。2023年北非数字司法论坛特别指出,此类数据集对实现法语-阿拉伯语双语法律咨询自动化具有里程碑意义,其标注范式已影响突尼斯、阿尔及利亚等马格里布国家的同类项目。
以上内容由遇见数据集搜集并总结生成


