stage2_mixed_curriculum_v1_4.2M-4.5M
收藏Hugging Face2026-01-19 更新2026-01-20 收录
下载链接:
https://huggingface.co/datasets/AdoCleanCode/stage2_mixed_curriculum_v1_4.2M-4.5M
下载链接
链接失效反馈官方服务:
资源简介:
该数据集包含用于TTS训练的混合文本/音素序列,采用课程学习方法。课程学习的概率从0.3(更多文本,较少音素)线性增加到1.0(全部音素),过渡过程覆盖500,000行数据。数据集的特征包括纯文本、音素IPA表示、音素标记、混合文本、XCodec2标记等。训练格式为将指定的文本或音素转换为语音。数据来源于AAdonis/multilingual_audio_alignments(英语部分),索引范围为4200000到4495451,每个音频3个样本,总样本数为819177。
This dataset contains mixed text/phoneme sequences for TTS training, utilizing a curriculum learning approach. The probability for curriculum learning increases linearly from 0.3 (more text, fewer phonemes) to 1.0 (all phonemes), with the transition spanning 500,000 data lines. The dataset features include plain text, IPA transcriptions of phonemes, phoneme tags, mixed text sequences, XCodec2 tokens, and more. The training format is to convert specified text or phonemes into speech. The data is sourced from AAdonis/multilingual_audio_alignments (English subset), with an index range from 4,200,000 to 4,495,451. Each audio has 3 samples, resulting in a total of 819,177 samples.
创建时间:
2026-01-18
原始信息汇总
Stage 2 Mixed Text/Phoneme TTS 数据集概述
数据集基本信息
- 数据集名称:Stage 2 Mixed Text/Phoneme TTS Dataset
- 数据量:训练集包含 819,177 个样本
- 数据来源:基于 AAdonis/multilingual_audio_alignments 数据集(英语部分)处理
- 索引范围:4,200,000 至 4,495,451
- 音频样本数:每个音频对应 3 个样本
核心特性与用途
- 主要用途:用于支持课程学习的文本转语音(TTS)训练。
- 核心概念:包含混合文本/音素序列,其中文本转换为音素的概率在数据集中线性递增。
- 课程学习策略:
- 起始概率:0.3(文本多,音素少)
- 结束概率:1.0(全部为音素)
- 过渡方式:在 500,000 行数据上线性过渡
- 应用规则:每一行使用其对应的概率
p(i)处理该行所有单词和空格,随后i递增用于下一行。
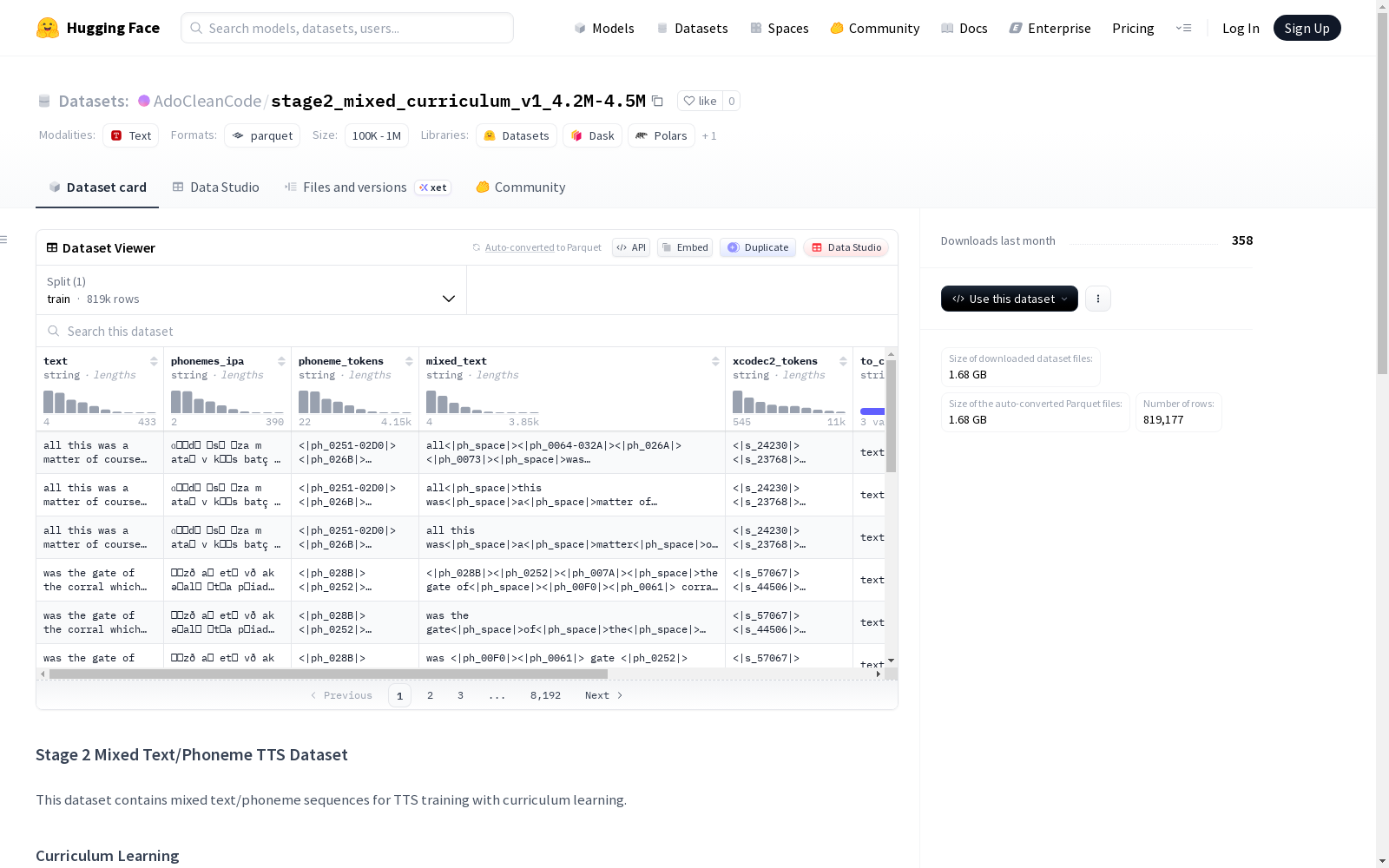
数据特征(Features)说明
| 特征列名 | 描述 |
|---|---|
text |
纯文本(包含所有单词) |
phonemes_ipa |
所有音素的国际音标(IPA)表示 |
phoneme_tokens |
所有音素,以 <|ph_xxxx|> 形式的十六进制令牌表示 |
mixed_text |
混合的文本和音素令牌 |
xcodec2_tokens |
完整音频的 XCodec2 令牌 |
to_convert |
指示内容类型:“text and phonemes” / “phonemes” / “text” |
sequence |
包含标记的完整训练序列 |
训练数据格式
训练序列遵循以下固定格式:
Convert the {to_convert} to speech: <|start_phon_gen|>{mixed_text}<|end_phon_gen|><|SPEECH_GENERATION_START|>{xcodec2_tokens}<|SPEECH_GENERATION_END|>
处理信息
- 最终全局行计数器:819,177
- 最终转换概率:1.000
搜集汇总
数据集介绍
构建方式
在语音合成技术领域,数据集的构建方式直接影响模型的学习轨迹与最终性能。本数据集采用课程学习策略,从源数据集AAdonis/multilingual_audio_alignments的英语部分中,截取索引范围4200000至4495451的音频样本,并从中均匀提取三个样本点,共计生成819,177条训练样本。其核心创新在于设计了一个动态的文本-音素混合转换机制:数据序列起始时,单词被转换为音素的概率设定为0.3,随着样本行数线性递增,在遍历50万行后,该概率最终达到1.0,即全部内容均以音素形式呈现。每一行数据均依据当前概率值,对其所有单词和空格进行统一转换,从而构建出一条从文本主导平滑过渡到音素主导的渐进式学习路径。
使用方法
为有效利用本数据集进行模型训练,使用者需遵循其预设的结构化流程。模型输入应基于`sequence`字段,该字段已整合了格式化的指令与数据。具体而言,模型的任务是根据`to_convert`字段的指示,将`mixed_text`字段中的混合内容转换为对应的语音输出,即`xcodec2_tokens`字段所代表的音频标记序列。整个流程被封装在特定的开始与结束标记之间,例如`<|start_phon_gen|>`和`<|end_phon_gen|>`用于界定文本-音素转换部分,`<|SPEECH_GENERATION_START|>`和`<|SPEECH_GENERATION_END|>`则用于界定语音生成部分。这种设计使得数据集能够直接适配于采用课程学习策略的端到端语音合成模型训练框架。
背景与挑战
背景概述
在语音合成技术不断演进的背景下,文本到语音模型面临着从纯文本输入向更丰富、更精确的语音表示过渡的需求。Stage 2 Mixed Text/Phoneme TTS Dataset应运而生,由研究团队基于AAdonis/multilingual_audio_alignments的英语数据子集构建,专注于通过课程学习策略优化TTS训练过程。该数据集的核心研究问题在于如何有效融合文本与音素序列,以提升模型在语音生成中的准确性与自然度,其渐进式混合设计为语音合成领域提供了新的数据范式,推动了自适应训练方法的发展。
当前挑战
该数据集旨在解决语音合成中文本与音素混合表示的挑战,具体包括如何平衡文本与音素在训练序列中的比例,以确保模型从文本理解平滑过渡到音素生成。在构建过程中,挑战主要体现为设计线性递增的转换概率机制,需精确控制超过50万行数据中从30%到100%音素转换的渐变过程,同时保持每个样本内部所有单词或空格转换的一致性,这对数据对齐与序列标记的可靠性提出了较高要求。
常用场景
经典使用场景
在语音合成领域,文本到语音转换模型常面临音素与文本对齐的挑战。该数据集通过混合文本与音素序列,为基于课程学习的语音合成训练提供了经典范例。模型从以文本为主的输入逐步过渡到全音素输入,模拟人类学习语言时从整体到细节的认知过程,有效提升合成语音的自然度与准确性。
解决学术问题
该数据集旨在解决语音合成中文本与音素表示不一致导致的训练不稳定性问题。通过线性增加音素转换概率的课程学习策略,缓解了模型在复杂语音特征学习中的梯度爆炸或消失现象。其意义在于为多模态序列建模提供了可解释的数据范式,推动了自适应课程学习在生成式人工智能中的应用。
实际应用
在实际应用中,该数据集支持开发高自然度的智能语音助手与有声内容生成系统。例如,在教育科技领域,可用于定制化发音教学工具,通过渐进式音素替换帮助学习者纠正口音。在娱乐产业中,能为虚拟角色生成带有情感韵律的语音,提升沉浸式体验。
数据集最近研究
最新研究方向
在语音合成领域,混合文本与音素序列的数据集正推动着课程学习策略的前沿探索。Stage 2 Mixed Text/Phoneme TTS Dataset通过动态调整文本到音素的转换概率,模拟了从语言理解到声学生成的渐进学习过程,这为构建更鲁棒、高效的端到端TTS模型提供了关键训练范式。当前研究热点集中于利用此类结构化课程数据优化多模态对齐,特别是在结合XCodec2等神经编解码器时,能够显著提升合成语音的自然度与表现力。该数据集的设计理念深刻影响了自适应学习在语音生成中的应用,为低资源语言与个性化语音合成开辟了新的技术路径。
以上内容由遇见数据集搜集并总结生成


