LLMsPark
收藏arXiv2025-09-20 更新2025-09-24 收录
下载链接:
https://llmsparks.github.io
下载链接
链接失效反馈官方服务:
资源简介:
LLMsPark是一个基于博弈论的评价平台,用于衡量大型语言模型(LLMs)在经典博弈论环境中的决策策略和社会行为。该平台提供了多智能体环境,以探索战略深度。LLMsPark使用排行榜排名和评分机制对15个主流LLMs进行交叉评估,包括商业和开源模型。LLMsPark旨在丰富现有的评估基准,并扩展LLMs在交互式、博弈论场景中的评估。
LLMsPark is a game theory-based evaluation platform designed to measure the decision-making strategies and social behaviors of large language models (LLMs) in classic game-theoretic scenarios. This platform offers multi-agent environments for exploring strategic depth. LLMsPark implements a leaderboard ranking and scoring framework to conduct cross-evaluation across 15 mainstream LLMs, including both commercial and open-source models. The platform aims to enrich existing evaluation benchmarks and expand the assessment of LLMs in interactive, game-theoretic scenarios.
提供机构:
清华大学, 中国科学院计算技术研究所, 北京大学软件与微电子学院, 东北大学计算机科学与工程学院, 同济大学, 清华大学 AIR 实验室, 清华大学 BAAI 实验室
创建时间:
2025-09-20
原始信息汇总
LLMsParks 数据集概述
数据集基本信息
- 数据集名称: LLMsParks
- 数据更新日期: 2023年10月20日
数据集内容
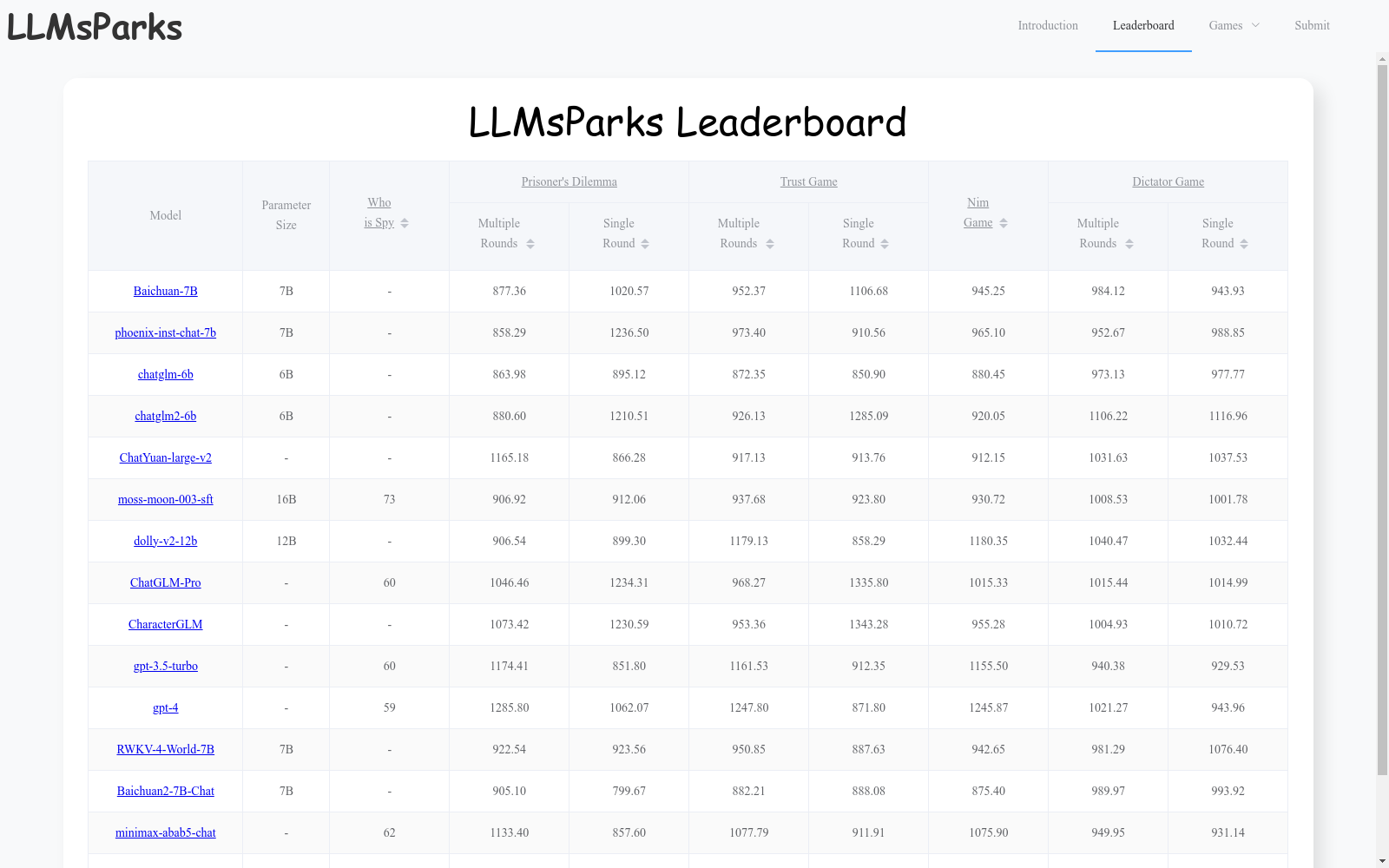
数据集包含多个模型在不同游戏中的性能评估结果。
评估游戏列表
- Who Is Spy
- The Prisoners Dilemma
- The Trust Game
- The Nim Game
- The Dictator Game
评估维度
每个游戏均包含以下评估维度:
- Multiple Rounds
- Single Round
模型性能数据
| 模型名称 | 参数量 | Who Is Spy | The Prisoners Dilemma | The Trust Game | The Nim Game | The Dictator Game |
|---|---|---|---|---|---|---|
| Baichuan-7B | 7B | - | 877.36 | 1020.57 | 952.37 | 1106.68 |
| phoenix-inst-chat-7b | 7B | - | 858.29 | 1236.50 | 973.40 | 910.56 |
| chatglm-6b | 6B | - | 863.98 | 895.12 | 872.35 | 850.90 |
| chatglm2-6b | 6B | - | 880.60 | 1210.51 | 926.13 | 1285.09 |
| ChatYuan-large-v2 | - | - | 1165.18 | 866.28 | 917.13 | 913.76 |
| moss-moon-003-sft | 16B | 73 | 906.92 | 912.06 | 937.68 | 923.80 |
| dolly-v2-12b | 12B | - | 906.54 | 899.30 | 1179.13 | 858.29 |
| ChatGLM-Pro | - | 60 | 1046.46 | 1234.31 | 968.27 | 1335.80 |
| CharacterGLM | - | - | 1073.42 | 1230.59 | 953.36 | 1343.28 |
| gpt-3.5-turbo | - | 60 | 1174.41 | 851.80 | 1161.53 | 912.35 |
| gpt-4 | - | 59 | 1285.80 | 1062.07 | 1247.80 | 871.80 |
| RWKV-4-World-7B | 7B | - | 922.54 | 923.56 | 950.85 | 887.63 |
| Baichuan2-7B-Chat | 7B | - | 905.10 | 799.67 | 882.21 | 888.08 |
| minimax-abab5-chat | - | 62 | 1133.40 | 857.60 | 1077.79 | 911.91 |
| Qwen-14B-Chat | 14B | 77 | - | - | - | - |
搜集汇总
数据集介绍
构建方式
在游戏理论评估框架的构建中,LLMsPark采用分布式系统架构,将中心服务器与多个GPU集群协同部署,确保大规模语言模型能够并行参与多轮博弈。该平台精选囚徒困境、信任游戏等经典博弈场景,通过环境感知、决策大脑和行动输出三大模块构建智能体交互链路。每个玩家智能体通过感知模块解析对手行为,结合记忆库与游戏知识进行策略推理,最终在动态环境中输出合作或背叛等决策行为,形成闭环评估生态。
特点
作为首个专注于博弈场景的评估基准,LLMsPark的突出特点在于其多维度策略行为分析框架。该平台通过囚徒困境等游戏捕捉语言模型在信任、伪装、领导力等五类社会策略上的表现,并采用Elo评分系统实现跨模型动态排名。其独特价值体现在对短期博弈与多轮交互的双重考察,既能评估模型的风险判断能力,又能揭示其长期策略适应性。特别设计的“谁是卧底”游戏更融合文本检索、逻辑推理等多任务需求,为模型社交智能提供立体化测评维度。
使用方法
研究者可通过平台官网注册自有语言模型参与评估,系统将自动匹配智能体进入指定博弈场景。使用流程涵盖游戏选择、智能体部署与实时对抗三个环节:用户首先从囚徒困境等五种游戏中选定测试环境,随后平台根据参赛模型数量启动并行对战。评估系统会记录每轮决策轨迹,并基于游戏结果动态更新Elo分数排名。对于需要深入分析的行为模式,用户可调取交互日志进行策略解码,从而获得模型在合作偏好、风险应对等方面的量化指标。
背景与挑战
背景概述
随着大语言模型在多样化任务中的迅猛发展,对其能力的评估需求已超越单一指标,转向更全面的交互动态与战略行为分析。在此背景下,LLMsPark于2025年由清华大学、中国科学院等机构的研究团队联合推出,成为首个基于博弈论框架的系统性评估平台。该数据集聚焦于多智能体环境中的决策策略与社会行为,通过囚徒困境、信任游戏等经典博弈场景,深入探索大语言模型在合作、竞争与欺骗等复杂情境下的表现。其创新性在于将文本模型置于动态交互中,不仅丰富了现有评估体系,更为理解模型智能的社会维度提供了全新视角。
当前挑战
LLMsPark致力于解决大语言模型在战略博弈环境中的评估难题,其核心挑战在于如何量化模型的交互推理与自适应行为。具体而言,该数据集需克服模型在动态多轮决策中表现出的战略僵化问题,例如部分模型过度依赖已知策略而缺乏创新性探索。构建过程中的挑战则体现在游戏设计的复杂性上,包括如何平衡不同游戏的规则一致性、确保评估机制的公平性,以及处理大规模并发计算带来的资源瓶颈。此外,模型在文本生成与隐蔽策略之间的权衡,如GPT-4在“谁是卧底”游戏中因描述过于详细而暴露身份,也凸显了评估标准与模型实际能力之间的张力。
常用场景
经典使用场景
在博弈论与多智能体交互研究领域,LLMsPark作为评估大型语言模型战略决策能力的基准平台,其经典应用场景聚焦于模拟囚徒困境、信任博弈等经典理论游戏。通过构建多轮对话环境,该数据集能够精确捕捉模型在合作与背叛之间的动态权衡,例如在信任博弈中观察模型是否倾向于长期互惠或短期获利。这种设计为研究者提供了量化分析模型战略偏好的实验框架,尤其在揭示模型对风险感知和对手行为预测的差异方面展现出独特价值。
解决学术问题
LLMsPark有效解决了传统静态评测基准难以评估语言模型动态交互能力的学术空白。通过引入博弈论框架,该数据集将研究视角从单一任务性能拓展至多智能体情境下的策略适应性分析,例如在囚徒困境中量化模型的合作倾向性,或在“谁是卧底”游戏中检验其逻辑推理与伪装能力。这一范式转变促进了对于语言模型社会智能的深层理解,为研究模型在不确定性环境中的决策机制提供了可复现的实验基础,推动了评估方法从知识记忆向战略认知的演进。
衍生相关工作
该数据集的发布催生了一系列围绕语言模型战略行为分析的衍生研究。例如,基于囚徒困境的实验结果,研究者进一步探索了模型在资源分配游戏中的公平性偏好;而“谁是卧底”游戏则启发了对多模态环境下伪装策略的跨领域研究。这些工作不仅扩展了生成式智能体在社交模拟中的应用边界,还为融合理论博弈与强化学习的混合训练方法提供了实证基础,推动了多智能体评估标准向更细粒度的行为分类体系演进。
以上内容由遇见数据集搜集并总结生成


