WaxalNLP
收藏Hugging Face2026-01-22 更新2026-01-23 收录
下载链接:
https://huggingface.co/datasets/google/WaxalNLP
下载链接
链接失效反馈官方服务:
资源简介:
Waxal项目为非洲语言提供了自动语音识别(ASR)和文本转语音(TTS)数据集。创建和发布这些数据集的目的是促进研究,提高这些服务不足语言的语音和语言技术的准确性和流畅性,并作为数字保存的存储库。Waxal数据集是通过与马凯雷雷大学、加纳大学、Digital Umuganda和Media Trust的合作收集的,由谷歌和盖茨基金会资助,协议要求数据集公开可访问。ASR数据集包含14种非洲语言的大约1,250小时的转录自然语音,代表超过1亿使用者的40个撒哈拉以南非洲国家。TTS数据集包含10种非洲语言的大约240小时的脚本自然语音。
The Waxal Project curates automatic speech recognition (ASR) and text-to-speech (TTS) datasets tailored for African languages. These datasets were developed and released to advance academic research, improve the accuracy and fluency of speech and language technologies for these under-resourced languages, and serve as a dedicated repository for digital preservation efforts. The Waxal datasets were collected through partnerships with Makerere University, University of Ghana, Digital Umuganda, and Media Trust, with funding provided by Google and the Bill & Melinda Gates Foundation. Per the terms of the funding agreement, the datasets must be publicly accessible. The ASR dataset comprises approximately 1,250 hours of transcribed natural speech spanning 14 African languages, which are spoken across 40 Sub-Saharan African countries by a combined speaker population of over 100 million. The TTS dataset contains approximately 240 hours of scripted natural speech across 10 African languages.
提供机构:
Google
创建时间:
2026-01-19
原始信息汇总
Waxal NLP 数据集概述
数据集基本信息
- 数据集名称: Waxal NLP Datasets
- 提供方: Google Research
- 许可证: CC-BY-SA-4.0, CC-BY-4.0 (具体语言许可证因数据提供方而异)
- 当前版本: 1.0.0
- 最后更新: 2026年1月
- 数据集地址: https://huggingface.co/datasets/google/WaxalNLP
数据集描述
Waxal项目提供用于非洲语言的自动语音识别和文本到语音数据集。其创建和发布的目标是促进研究,以提高这些服务不足语言的语音和语言技术的准确性和流畅性,并作为数字保存的存储库。
该数据集通过与马凯雷雷大学、加纳大学、Digital Umuganda和Media Trust的合作获取,由谷歌和盖茨基金会资助,并同意使数据集可公开访问。
任务与配置
- 任务类别: 自动语音识别, 文本到语音
- 配置:
asr: 自动语音识别数据tts: 文本到语音数据
语言覆盖
- 总语言数: 20种非洲语言
- 语言列表: Acholi, Akan, Dagbani, Dagaare, Ewe, Fante, Fula, Hausa, Igbo, Ikposo, Lingala, Luganda, Masaaba, Malagasy, Nyankole, Shona, Soga, Kiswahili, Twi, Yoruba
ASR数据集语言详情
- 语言数量: 14种
- 总时长: 约1250小时的自然语音转录数据
- 覆盖人群: 代表超过40个撒哈拉以南非洲国家的1亿多使用者
- 数据提供方与语言:
- 马凯雷雷大学: Acholi, Luganda, Masaaba, Nyankole, Soga (许可证: CC-BY-4.0)
- 加纳大学: Akan, Ewe, Dagbani, Dagaare, Ikposo (许可证: CC-BY-NC-4.0)
- Digital Umuganda: Fula, Lingala, Shona, Malagasy (许可证: CC-BY-4.0)
TTS数据集语言详情
- 语言数量: 10种
- 总时长: 约240小时的脚本自然语音数据
- 数据提供方与语言:
- 马凯雷雷大学: Acholi, Luganda, Kiswahili, Nyankole (许可证: CC-BY-4.0)
- 加纳大学: Akan (Fante, Twi) (许可证: CC-BY-NC-4.0)
- Media Trust: Fula, Igbo, Hausa, Yoruba (许可证: CC-BY-4.0)
数据集结构
数据字段
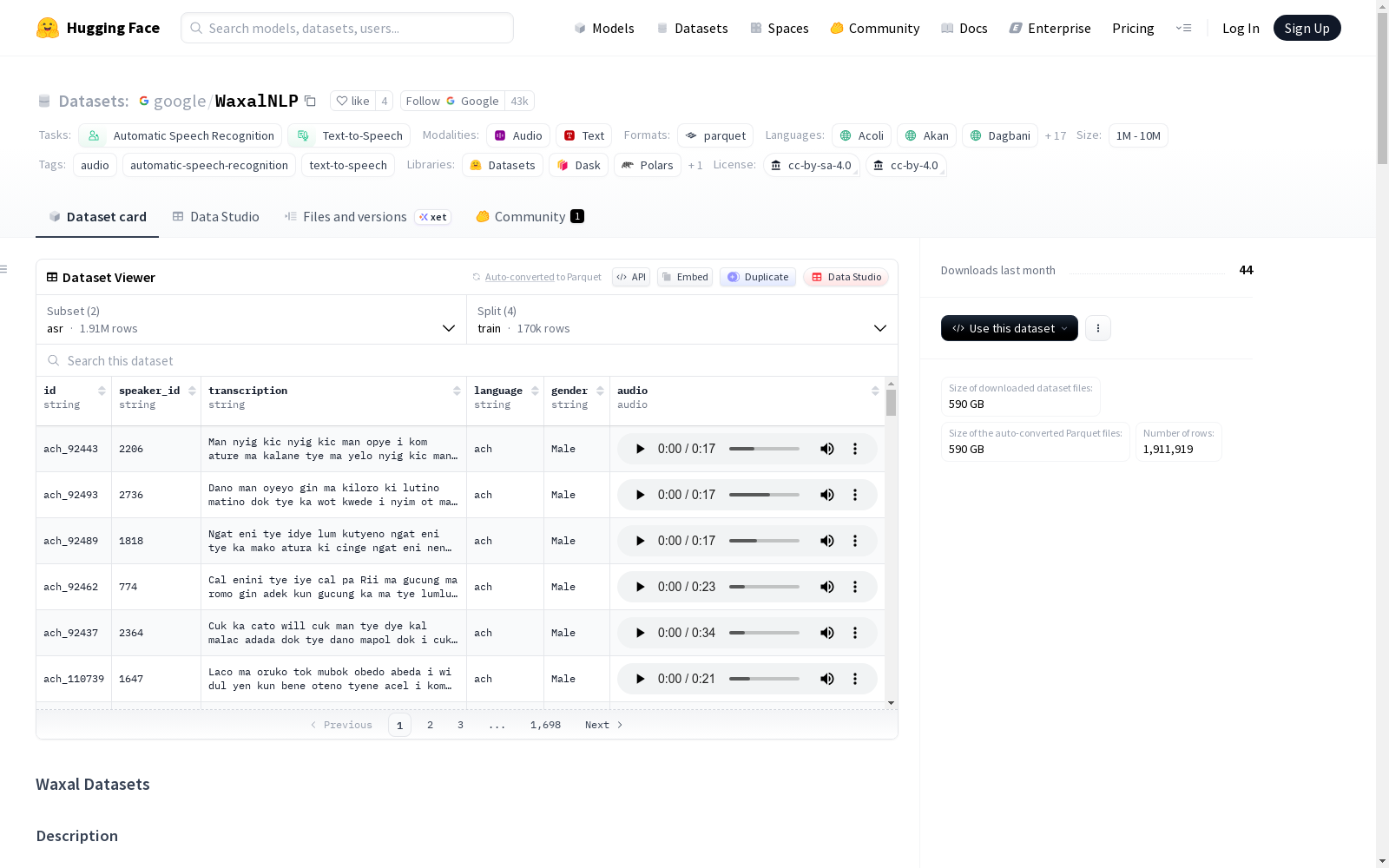
ASR配置字段:
id: 唯一标识符speaker_id: 说话者唯一标识符audio: 音频数据transcription: 音频转录文本language: ISO 639-2语言代码gender: 说话者性别 (Male, Female, 或空)
TTS配置字段:
id: 唯一标识符speaker_id: 说话者唯一标识符audio: 音频数据transcription: 转录文本locale: ISO 639-2语言代码gender: 说话者性别
数据划分
ASR数据集划分:
train: 80%的标注数据validation: 10%的标注数据test: 10%的标注数据unlabeled: 所有没有对应转录的样本
TTS数据集划分:
数据被划分为train、validation和test集,结构类似。
数据来源
- 加纳大学: UGSpeechData (https://doi.org/10.57760/sciencedb.22298)
- Digital Umuganda: AfriVoice (DigitalUmuganda/AfriVoice)
- 马凯雷雷大学: Yogera Dataset (https://doi.org/10.7910/DVN/BEROE0)
- Media Trust
使用注意事项
使用数据前请检查您所用具体语言的许可证,因为它们可能因提供方而异。
搜集汇总
数据集介绍
构建方式
在非洲语言语音技术资源相对匮乏的背景下,WaxalNLP数据集通过多机构协作模式构建而成。其数据采集工作由马凯雷雷大学、加纳大学、Digital Umuganda以及Media Trust等合作伙伴共同完成,并获得了谷歌与盖茨基金会的资助支持。数据集整合了来自UGSpeechData、AfriVoice及原创数据源的内容,经由人工标注与众包方式,系统性地收集并转录了涵盖多种非洲语言的语音样本,最终形成了结构化的自动语音识别与文本转语音语料库。
特点
该数据集的核心特征在于其广泛覆盖了包括阿坎语、埃维语、富拉语、豪萨语、伊博语等在内的二十余种非洲语言,涉及使用者超一亿人,地域横跨撒哈拉以南非洲四十个国家。数据集提供了约1250小时的自动语音识别自然语音数据与约240小时的文本转语音脚本语音数据,样本兼具说话人身份、性别及语言变体等丰富元信息。数据以标准化格式组织,包含训练、验证、测试及未标注分割,为低资源语言的语音技术研究提供了高质量、多维度且规模可观的基准资源。
使用方法
研究者可利用Hugging Face的`datasets`库便捷地加载与处理该数据集。使用前需通过`pip install datasets[audio]`安装音频处理依赖。对于自动语音识别任务,通过指定语言代码(如`sna`代表绍纳语)及数据目录`data/ASR`调用`load_dataset`函数即可加载相应子集;文本转语音数据的加载方式类似,需指向`data/TTS`目录。加载后,数据以字典形式呈现,可直接访问音频波形数组、采样率、文本转录及元数据字段,便于后续的模型训练与评估流程。
背景与挑战
背景概述
在语音技术领域,非洲语言长期以来面临资源匮乏的困境,制约了相关自然语言处理技术的发展。WaxalNLP数据集由Google Research联合Makerere University、University of Ghana、Digital Umuganda及Media Trust等机构,在Google与盖茨基金会的资助下共同构建,并于2026年初发布。该数据集旨在为自动语音识别和文本转语音任务提供高质量的多语言语料,覆盖阿坎语、富拉语、斯瓦希里语等二十余种非洲语言,涉及超过一亿使用者,致力于推动低资源语言的技术公平与数字保存。
当前挑战
该数据集致力于解决非洲低资源语言在自动语音识别与文本转语音领域的数据稀缺问题,其核心挑战在于这些语言方言变体丰富、标注规范缺失,导致模型泛化能力不足。在构建过程中,面临多方机构协作下的数据格式与许可协议整合困难,以及通过众包获取高质量、口音均衡的语音样本时,需克服录音环境不一致与转录准确性保障等实际障碍。
常用场景
解决学术问题
WaxalNLP数据集致力于解决语音技术研究中长期存在的语言不平等问题。在学术层面,它缓解了非洲语言数据稀缺的困境,为低资源语言语音识别和合成提供了标准化基准。该数据集支持多语言语音处理、跨语言表示学习以及方言变体建模等研究课题,促进了语音技术模型的泛化能力和鲁棒性。通过提供大规模标注语音数据,它推动了语音技术在全球语言多样性背景下的公平性与可及性研究。
衍生相关工作
围绕WaxalNLP数据集,学术界衍生出一系列经典研究工作。例如,基于该数据集的跨语言语音识别模型探索了迁移学习在低资源语言上的有效性;多说话人TTS系统利用其丰富的语音样本提升了合成语音的自然度。此外,该数据集还促进了非洲语言语音技术竞赛的举办,激励研究者开发更高效的端到端语音处理架构。这些工作共同推动了全球语音技术研究向多语言、公平化的方向演进。
以上内容由遇见数据集搜集并总结生成


