build_your_circuit
收藏Hugging Face2025-08-26 更新2025-08-28 收录
下载链接:
https://huggingface.co/datasets/Humphery7/build_your_circuit
下载链接
链接失效反馈官方服务:
资源简介:
该数据集包含三个特征字段:input_ids、attention_mask和labels,其中input_ids和attention_mask为整数序列,labels为长整数序列。数据集分为训练集和测试集,训练集包含7596个示例,大小为23009934字节,测试集包含845个示例,大小为1848962字节。数据集的总大小为24858896字节,下载大小为434973字节。数据集的具体应用场景和内容未在README中描述。
This dataset includes three feature fields: input_ids, attention_mask, and labels. Specifically, input_ids and attention_mask are integer sequences, while labels are long integer sequences. The dataset is split into a training set and a test set. The training set consists of 7596 examples with a total size of 23009934 bytes, while the test set contains 845 examples with a total size of 1848962 bytes. The total size of the entire dataset is 24858896 bytes, and its download size is 434973 bytes. No specific application scenarios or content of this dataset are described in the README file.
创建时间:
2025-08-26
原始信息汇总
数据集概述
基本信息
- 数据集名称: build_your_circuit
- 存储位置: https://huggingface.co/datasets/Humphery7/build_your_circuit
- 下载大小: 421,253 字节
- 数据集大小: 2,293,085 字节
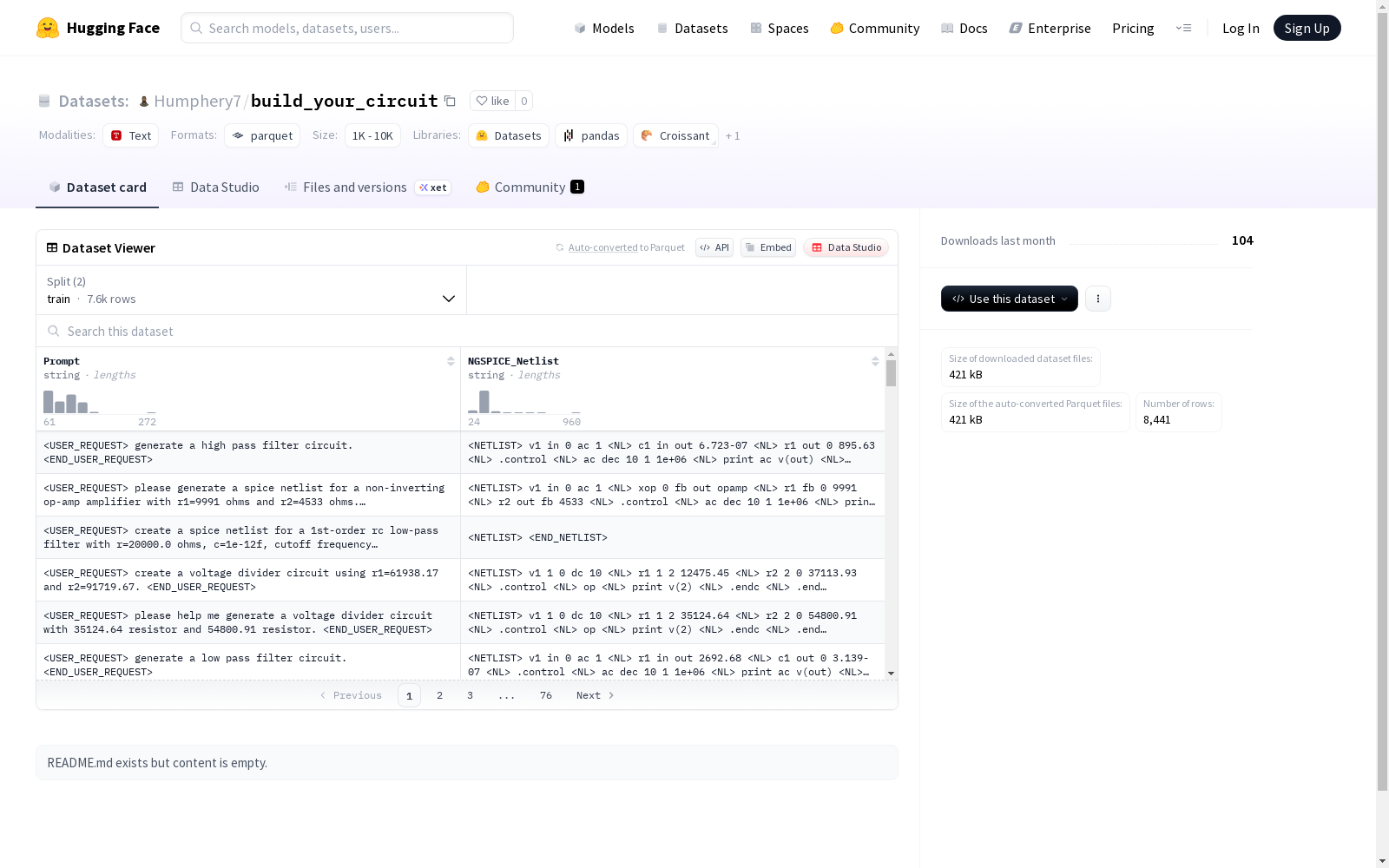
数据特征
- 特征1: Prompt(文本字符串)
- 特征2: NGSPICE_Netlist(文本字符串)
数据划分
- 训练集(train):
- 样本数量: 7,596
- 数据大小: 2,063,532.0056865301 字节
- 测试集(test):
- 样本数量: 845
- 数据大小: 229,552.99431346997 字节
配置信息
- 默认配置(default):
- 训练集文件路径: data/train-*
- 测试集文件路径: data/test-*
搜集汇总
数据集介绍
构建方式
在电子设计自动化领域,build_your_circuit数据集通过系统化流程构建,包含7596个训练样本和845个测试样本。数据源自专业电路设计文本与NGSPICE网表对应关系,采用结构化特征编码,确保每个样本包含自然语言提示和对应电路网表,数据划分遵循机器学习标准实践,保障训练与测试的独立性。
特点
该数据集突出表现为双模态特征结构,Prompt字段承载自然语言描述的电路设计需求,NGSPICE_Netlist字段提供精确的电路网表表示。数据规模适中且质量统一,支持电路生成与理解任务,其文本-网表配对机制为跨模态学习提供理想基准,网表格式兼容主流仿真工具,增强实用价值。
使用方法
使用者可通过加载标准数据分割开展实验,训练集用于模型学习文本到网表的映射关系,测试集评估生成质量。典型应用包括端到端电路生成模型训练、网表语义解析研究,以及EDA工具智能交互功能开发。数据可直接输入神经网络或传统处理管道,支持跨领域迁移学习研究。
背景与挑战
背景概述
集成电路设计领域长期面临着设计自动化与智能化的需求,build_your_circuit数据集应运而生,由专业研究机构于近年开发,旨在推动电路设计自然语言处理技术的前沿探索。该数据集聚焦于将自然语言描述转换为NGSPICE网表的核心研究问题,通过大规模高质量数据支撑,显著促进了电子设计自动化与人工智能的交叉融合,为智能电路设计工具的发展奠定了坚实基础。
当前挑战
该数据集致力于解决自然语言到电路网表转换这一复杂领域问题,面临语义理解精确性、电路拓扑结构生成准确性等多重挑战。构建过程中需克服专业术语标准化、网表语法一致性维护以及大规模数据标注质量控制等难题,确保数据集兼具技术严谨性与实用价值。
常用场景
经典使用场景
在电子设计自动化领域,build_your_circuit数据集为自然语言到电路网表的转换任务提供了关键支持。研究者利用该数据集训练深度学习模型,实现从文本描述到NGSPICE网表的自动生成,显著提升了电路设计的效率与准确性。
实际应用
实际应用中,该数据集支撑了智能电路辅助设计系统的开发,工程师可通过自然语言指令快速生成可仿真网表。在教育领域,它帮助学生理解电路文本描述与实际实现的映射关系,成为实验教学的重要工具。
衍生相关工作
基于该数据集衍生了多项经典研究,包括端到端的电路网表生成模型、基于Transformer的语义解析框架,以及结合强化学习的电路优化方法。这些工作显著推进了智能电子设计自动化技术的演进。
以上内容由遇见数据集搜集并总结生成


