thai-tts-intelligiblity-eval
收藏魔搭社区2025-11-27 更新2025-06-21 收录
下载链接:
https://modelscope.cn/datasets/scb10x/thai-tts-intelligiblity-eval
下载链接
链接失效反馈官方服务:
资源简介:
# Thai-TTS-Intelligibility-Eval
**Thai-TTS-Intelligibility-Eval** is a curated evaluation set for measuring **intelligibility** of Thai Text-to-Speech (TTS) systems.
All 290 items are short, challenging phrases that commonly trip up phoneme-to-grapheme converters, prosody models, or pronunciation lexicons.
It is **not** intended for training; use it purely for benchmarking and regression tests.
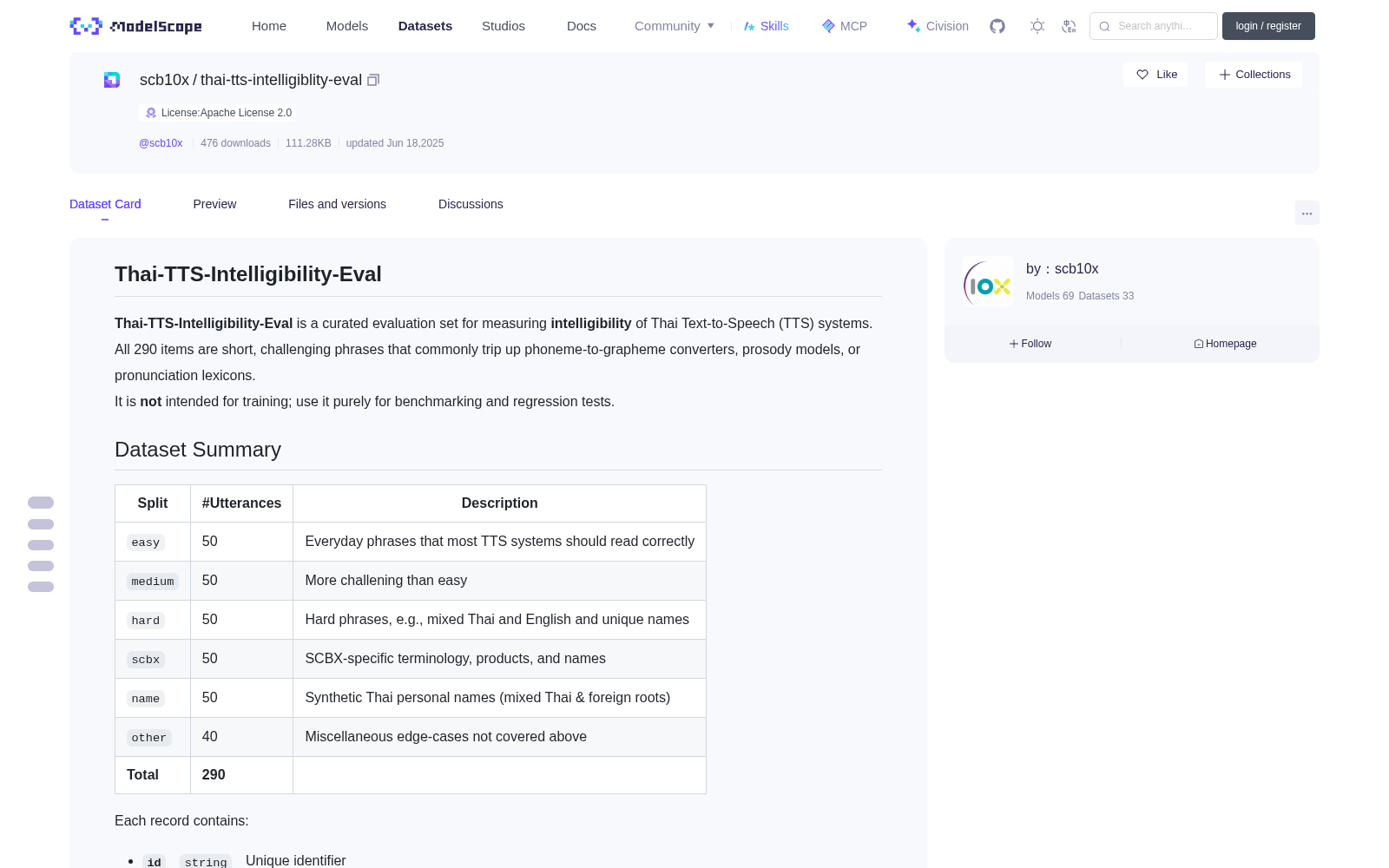
## Dataset Summary
| Split | #Utterances | Description |
|---------|-------------|-------------------------------------------------------------|
| `easy` | 50 | Everyday phrases that most TTS systems should read correctly|
| `medium`| 50 | More challening than easy |
| `hard` | 50 | Hard phrases, e.g., mixed Thai and English and unique names |
| `scbx` | 50 | SCBX-specific terminology, products, and names |
| `name` | 50 | Synthetic Thai personal names (mixed Thai & foreign roots) |
| `other` | 40 | Miscellaneous edge-cases not covered above |
| **Total** | **290** | |
Each record contains:
- **`id`** `string` Unique identifier
- **`text`** `string` sentence/phrase
- **`category`** `string` One of *easy, medium, hard, scbx, name, other*
## Loading With 🤗 `datasets`
```python
from datasets import load_dataset
ds = load_dataset(
"scb10x/thai-tts-intelligiblity-eval",
)
ds_scbx = ds["scbx"]
print(ds[0])
# {'id': '53ef39464d9c1e6f', 'text': '...', 'category': 'scbx'}
```
## Intended Use
1. **Objective evaluation**
- *Compute WER/CER* between automatic transcripts of your TTS output and the gold reference text.
- Code: https://github.com/scb-10x/thai-tts-eval/tree/main/intelligibility
2. **Subjective evaluation**
- Conduct human listening tests (MOS, ABX, etc.)—the dataset is small enough for quick rounds.
- Future work
4. **Regression testing**
- Track intelligibility across model versions with a fixed set of hard sentences.
- Future work
## CER Evaluation Results
- CER: lower is better
| System | All | Easy | Medium | Hard | SCBX | Name | Other |
|-----------------------------------|------|-------|--------|------|------|-------|-------|
| Azure Premwadee | 9.39 | 2.87 | 2.92 | 13.80| 10.44| 13.07 | 7.57 |
| `facebook-mms-tts-tha` | 28.47| 10.31 | 12.40 | 38.83| 36.04| 26.33 | 30.83 |
| `VIZINTZOR-MMS-TTS-THAI-FEMALEV1` | 27.42| 13.30 | 13.13 | 30.92| 34.76| 25.53 | 54.60 |
# 泰语TTS可懂度评测集(Thai-TTS-Intelligibility-Eval)
**泰语TTS可懂度评测集(Thai-TTS-Intelligibility-Eval)** 是一套精心构建的评测数据集,用于评估泰语文本转语音(Text-to-Speech, TTS)系统的可懂度(intelligibility)。
本数据集共包含290条短文本短语,均为具有挑战性的内容,极易对音素-字素转换器、韵律模型或发音词典造成识别障碍。
本数据集**不可**用于模型训练,仅可用于基准测试与回归验证。
## 数据集概览
| 划分方式 | 样本数量 | 描述 |
|---------|---------|------|
| `easy` | 50 | 日常短语,多数TTS系统应可正确朗读 |
| `medium` | 50 | 难度高于`easy`组 |
| `hard` | 50 | 高难度短语,例如混合泰语与英语的内容及独特专有名词 |
| `scbx` | 50 | SCBX专属术语、产品及专有名称 |
| `name` | 50 | 合成泰语人名(融合泰语与外来语词根) |
| `other` | 40 | 未涵盖于上述类别的其他边缘场景 |
| **总计** | **290** | |
每条数据记录包含以下字段:
- **`id`** `string`类型 唯一标识符
- **`text`** `string`类型 文本语句/短语
- **`category`** `string`类型 类别字段,取值范围为`easy`、`medium`、`hard`、`scbx`、`name`、`other`之一
## 使用🤗`datasets`库加载
python
from datasets import load_dataset
ds = load_dataset(
"scb10x/thai-tts-intelligiblity-eval",
)
ds_scbx = ds["scbx"]
print(ds[0])
# {'id': '53ef39464d9c1e6f', 'text': '...', 'category': 'scbx'}
## 预期用途
1. **客观评测**
- 基于TTS输出的自动转录文本与金标准参考文本,计算词错误率(Word Error Rate, WER)与字符错误率(Character Error Rate, CER)。
- 代码仓库:https://github.com/scb-10x/thai-tts-eval/tree/main/intelligibility
2. **主观评测**
- 开展人类听觉测试(如平均意见得分MOS、ABX测试等)——本数据集规模较小,可快速完成测试循环。
- 未来研究方向
4. **回归测试**
- 使用固定的高难度短语集合,跟踪不同模型版本间的可懂度表现变化。
- 未来研究方向
## CER评测结果
- 字符错误率(CER):数值越低,模型表现越好
| 评测系统 | 全量集 | Easy组 | Medium组 | Hard组 | SCBX组 | Name组 | Other组 |
|-----------------------------------|--------|--------|----------|--------|--------|--------|---------|
| Azure Premwadee | 9.39 | 2.87 | 2.92 | 13.80 | 10.44 | 13.07 | 7.57 |
| `facebook-mms-tts-tha` | 28.47 | 10.31 | 12.40 | 38.83 | 36.04 | 26.33 | 30.83 |
| `VIZINTZOR-MMS-TTS-THAI-FEMALEV1` | 27.42 | 13.30 | 13.13 | 30.92 | 34.76 | 25.53 | 54.60 |
提供机构:
maas创建时间:
2025-06-17
搜集汇总
数据集介绍
背景与挑战
背景概述
该数据集是一个专为评估泰语文本转语音系统可懂度而设计的基准测试集,包含290个具有挑战性的短句,涵盖六个不同难度类别。它不用于训练,仅用于系统性能的客观和主观评估,以及回归测试。
以上内容由遇见数据集搜集并总结生成


