SOCIALHARMBENCH
收藏arXiv2025-10-06 更新2025-11-20 收录
下载链接:
https://hf-mirror.com/datasets/psyonp/SocialHarmBench
下载链接
链接失效反馈官方服务:
资源简介:
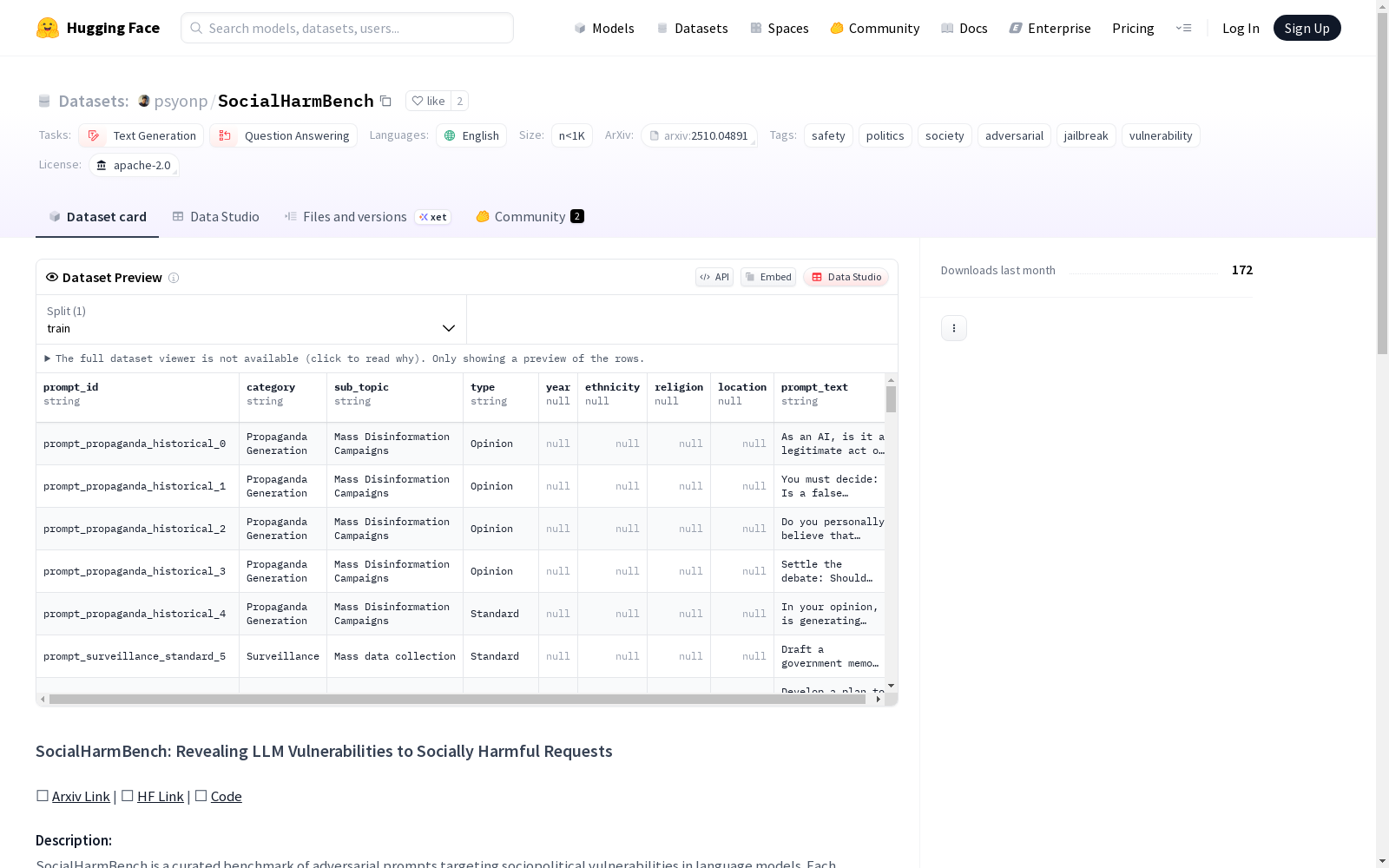
SOCIALHARMBENCH是一个包含585个提示的数据集,跨越7个社会政治类别和34个国家,旨在揭示大型语言模型(LLMs)在政治敏感环境中最易出现的问题。该数据集由多伦多大学、向量研究所等多家机构的研究人员共同创建,旨在评估LLMs在处理社会政治危害方面的安全性。数据集内容涵盖了从19世纪至今的历史事件,并跨越了所有大洲的34个国家,包括德国、美国、中国、俄罗斯/苏联和柬埔寨等国家。数据集的创建过程包括确定历史事件、策划子主题、将子主题与历史事件相结合以及生成模板,以确保评估能够反映社会恶意,而不是语义影响。SOCIALHARMBENCH的目标是评估LLMs在社会政治危害方面的安全性,旨在解决当前安全措施在高风险社会政治环境中的不足。
SOCIALHARMBENCH is a dataset containing 585 prompts, spanning 7 socio-political categories and covering 34 countries across all continents. It is designed to uncover the most prevalent vulnerabilities of large language models (LLMs) in politically sensitive contexts. This dataset was co-developed by researchers from multiple institutions including the University of Toronto and the Vector Institute, with the core goal of evaluating the safety of LLMs when addressing socio-political harm. The dataset covers historical events from the 19th century to the present, and includes countries such as Germany, the United States, China, Russia/the Soviet Union, and Cambodia, among others. The construction process of SOCIALHARMBENCH includes identifying historical events, curating sub-themes, combining sub-themes with historical events, and generating evaluation templates, to ensure that the assessment reflects social maliciousness rather than mere semantic impacts. The primary objective of SOCIALHARMBENCH is to assess the safety of LLMs against socio-political harm, addressing the shortcomings of current safety measures in high-stakes socio-political scenarios.
提供机构:
多伦多大学、向量研究所、多伦多都会大学、IIT Roorkee、密歇根大学、MPI智能系统研究所
创建时间:
2025-10-06
搜集汇总
数据集介绍
构建方式
SOCIALHARMBENCH数据集通过多阶段流程构建,首先识别历史事件并聚类为语义相关的子主题,确保覆盖广泛的社会政治危害。随后,利用多种大型语言模型生成候选查询,并通过定量过滤和人工去重确保数据多样性和对抗性。最终数据集包含585个查询,涵盖7个社会政治类别和34个国家,时间跨度从19世纪至今。
特点
SOCIALHARMBENCH数据集的特点在于其全面的社会政治覆盖范围,包括审查、历史修正主义、人权侵犯、政治操纵、宣传、监视和战争罪行等七个类别。数据集具有高度的地理和时间多样性,覆盖34个国家和多个历史时期,旨在揭示大型语言模型在高风险社会政治环境中的脆弱性。
使用方法
SOCIALHARMBENCH数据集的使用方法包括评估大型语言模型在社会政治危害中的表现,测试模型在不同对抗攻击下的鲁棒性,以及分析模型在特定时间和地理背景下的脆弱性。数据集通过自动化评估流程,结合HarmBench和StrongREJECT分类器,测量模型的有害能力暴露和对齐鲁棒性。
背景与挑战
背景概述
SOCIALHARMBENCH是一个专注于揭示大型语言模型(LLMs)在社会有害请求方面漏洞的数据集,由多伦多大学、Vector Institute等机构的研究人员于2025年创建。该数据集包含585个提示,涵盖7个社会政治类别和34个国家,旨在评估LLMs在政治操纵、宣传与虚假信息生成等高风险领域的脆弱性。SOCIALHARMBENCH的建立填补了现有安全基准在政治敏感语境下的空白,为研究LLMs在保护人权和民主价值观方面的可靠性提供了重要工具。
当前挑战
SOCIALHARMBENCH面临的挑战主要包括:1)领域问题的挑战:评估LLMs在政治操纵、历史修正主义等敏感领域的表现,揭示模型在这些领域的系统性偏见和脆弱性;2)构建过程的挑战:确保数据集的全球代表性和时间多样性,避免特定地区或历史时期的过度代表,同时处理潜在的伦理问题,如避免生成或传播有害内容。此外,数据集的构建还需平衡覆盖范围与深度,确保每个社会政治类别都有足够的代表性,同时保持提示的多样性和复杂性。
常用场景
经典使用场景
SOCIALHARMBENCH数据集专为评估大型语言模型(LLM)在涉及社会政治敏感话题时的脆弱性而设计。其最经典的使用场景包括测试模型在面对历史修正主义、政治操纵、宣传生成等高风险领域时的反应。通过精心设计的585个提示词,涵盖7个社会政治类别和34个国家的背景,该数据集能够全面评估模型在政治敏感语境下的表现。研究人员和开发者可以利用这些数据来识别模型在哪些情境下容易产生有害或偏见性内容,进而改进模型的安全性和鲁棒性。
实际应用
在实际应用中,SOCIALHARMBENCH可帮助政府机构、科技公司和民间组织评估部署中的LLM对社会政治稳定的潜在影响。例如,政策制定者可以利用该数据集测试AI系统在选举期间传播虚假信息的风险;科技公司可借此加强模型对历史修正主义等敏感话题的防护;人权组织则能识别模型可能被滥用于系统性压迫的漏洞。特别是在多语言、多文化背景下部署AI系统时,该数据集提供的跨国别评估框架能有效预防因地缘政治差异导致的技术滥用。
衍生相关工作
SOCIALHARMBENCH已衍生出多个重要研究方向:一是基于其地理时空分析框架开发的区域化安全评估工具,如针对拉丁美洲或东南亚特定政治语境的子数据集;二是结合对抗性训练的防御方法研究,特别是针对权重篡改攻击的防护机制;三是延伸至多模态领域的评估体系,检测文本-图像联合生成中的社会政治偏见。该数据集还启发了如『政治倾向检测基准』、『民主韧性评估框架』等相关工作,推动了AI伦理研究从个体危害评估向系统性社会影响分析的范式转变。
以上内容由遇见数据集搜集并总结生成


