nlu-question_answering
收藏Hugging Face2024-12-19 更新2024-12-20 收录
下载链接:
https://huggingface.co/datasets/aisingapore/nlu-question_answering
下载链接
链接失效反馈官方服务:
资源简介:
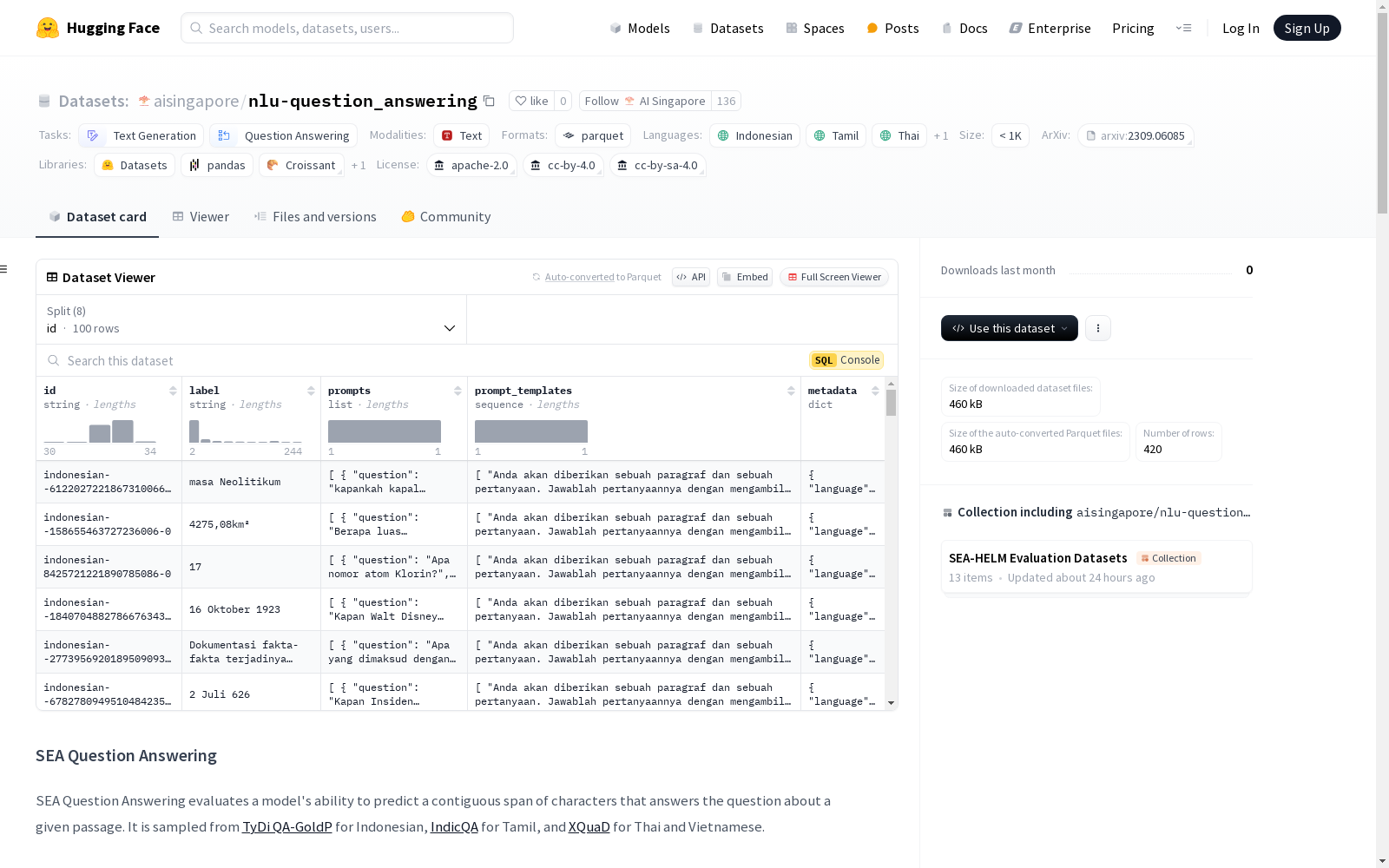
SEA Question Answering数据集用于评估模型在给定段落中回答问题的能力。它包含印度尼西亚语、泰米尔语、泰语和越南语的样本,每个语言部分都有100个示例,并且有少样本示例的额外分割。数据集的特征包括ID、标签、提示(包括问题和文本)、提示模板和元数据(包括语言信息)。数据集的统计信息包括每个分割的示例数量、GPT-4o、Gemma 2和Llama 3的标记数量。数据集的来源包括TyDi QA-GoldP、IndicQA和XQuaD,每个来源都有其特定的许可证。
The SEA Question Answering dataset is designed to evaluate a model's ability to answer questions using provided paragraphs. It contains samples in Indonesian, Tamil, Thai, and Vietnamese, with 100 examples per language subset and an additional few-shot split. The dataset's features include ID, label, prompt (comprising the question and supporting text), prompt template, and metadata (including language information). Its statistical metrics cover the number of examples per split, as well as the token counts generated by GPT-4o, Gemma 2, and Llama 3. The dataset is sourced from TyDi QA-GoldP, IndicQA, and XQuaD, each with its own specific license.
提供机构:
AI Singapore
创建时间:
2024-12-11
搜集汇总
数据集介绍
构建方式
SEA Question Answering数据集的构建基于多语言问答任务,汇集了来自不同语言背景的问答数据。具体而言,该数据集从TyDi QA-GoldP、IndicQA和XQuaD等多个源数据集中采样,涵盖了印度尼西亚语、泰米尔语、泰语和越南语。每个语言子集均包含标准问答数据和少样本示例,以支持模型在不同语言环境下的性能评估。数据集的构建旨在通过多语言问答任务,评估模型在不同语言中的跨文化理解能力。
特点
SEA Question Answering数据集的显著特点在于其多语言覆盖和多样化的数据来源。该数据集不仅支持印度尼西亚语、泰米尔语、泰语和越南语,还提供了少样本学习示例,以帮助模型在资源有限的情况下进行有效训练。此外,数据集的结构设计考虑了不同语言的特性,确保了问答任务的多样性和挑战性,从而为模型提供了全面的评估基准。
使用方法
SEA Question Answering数据集适用于评估和优化大型语言模型在多语言问答任务中的表现。用户可以通过加载数据集的不同语言子集,进行模型训练和评估。数据集提供了详细的元数据信息,包括语言标识和问答对,便于用户根据具体需求进行数据筛选和处理。此外,数据集还支持少样本学习场景,适用于资源受限的模型训练和测试。
背景与挑战
背景概述
SEA Question Answering数据集旨在评估模型在给定文本段落中回答问题的能力,其样本来源于多个高质量的问答数据集,包括TyDi QA-GoldP(印尼语)、IndicQA(泰米尔语)以及XQuaD(泰语和越南语)。该数据集由AI Singapore主导开发,旨在支持东南亚语言的自然语言处理研究,特别是针对大型语言模型(LLMs)的指令调优和聊天模型评估。通过整合多语言资源,SEA Question Answering为跨语言问答系统的发展提供了宝贵的基准数据,推动了多语言环境下信息检索与生成的研究。
当前挑战
SEA Question Answering数据集面临的挑战主要集中在多语言处理和数据质量控制方面。首先,不同语言的语法结构和表达习惯差异显著,导致模型在跨语言迁移时面临困难。其次,数据集的构建过程中,如何确保样本的多样性和代表性,避免版权或争议内容,是一个复杂的问题。此外,针对东南亚语言的资源相对匮乏,如何有效利用有限的数据进行模型训练和评估,也是该数据集需要解决的关键挑战。
常用场景
经典使用场景
SEA Question Answering数据集主要用于评估大型语言模型在多语言环境下进行问答任务的能力。该数据集通过提供多种语言的问答对,帮助模型学习如何在不同语言背景下准确提取并生成答案。其经典使用场景包括在多语言问答系统中,模型需要根据给定的文本段落回答用户提出的问题,尤其是在印尼语、泰米尔语、泰语和越南语等语言中进行跨语言问答任务的评估。
解决学术问题
SEA Question Answering数据集解决了多语言问答系统中的关键学术问题,特别是在非英语语言中的信息提取与生成难题。通过提供多语言的问答对,该数据集帮助研究人员评估和改进模型在不同语言环境下的表现,推动了多语言自然语言处理技术的发展。其意义在于促进了跨语言知识迁移的研究,并为多语言问答系统的实际应用提供了理论支持。
衍生相关工作
基于SEA Question Answering数据集,研究者们开展了一系列相关工作,特别是在多语言问答系统和跨语言知识迁移领域。例如,有研究利用该数据集评估了不同语言模型在多语言环境下的表现,并提出了改进模型性能的方法。此外,该数据集还促进了多语言预训练模型的开发,推动了多语言自然语言处理技术的整体进步,为后续研究提供了丰富的实验基础。
以上内容由遇见数据集搜集并总结生成


