IndicTTS-Hindi-male
收藏Hugging Face2025-05-24 更新2025-05-25 收录
下载链接:
https://huggingface.co/datasets/Anjan9320/IndicTTS-Hindi-male
下载链接
链接失效反馈官方服务:
资源简介:
这是一个由Indic TTS数据库项目派生出的数据集,特别使用了男女说话者的印地语单语言录音。数据集包含高质量的语音录音及其对应的文本转录,适合用于文本到语音(TTS)研究和开发。
This is a dataset derived from the Indic TTS Database Project, which specifically employs monolingual Hindi speech recordings from both male and female speakers. The dataset contains high-quality speech recordings along with their corresponding text transcriptions, making it suitable for research and development in the field of text-to-speech (TTS).
创建时间:
2025-05-22
原始信息汇总
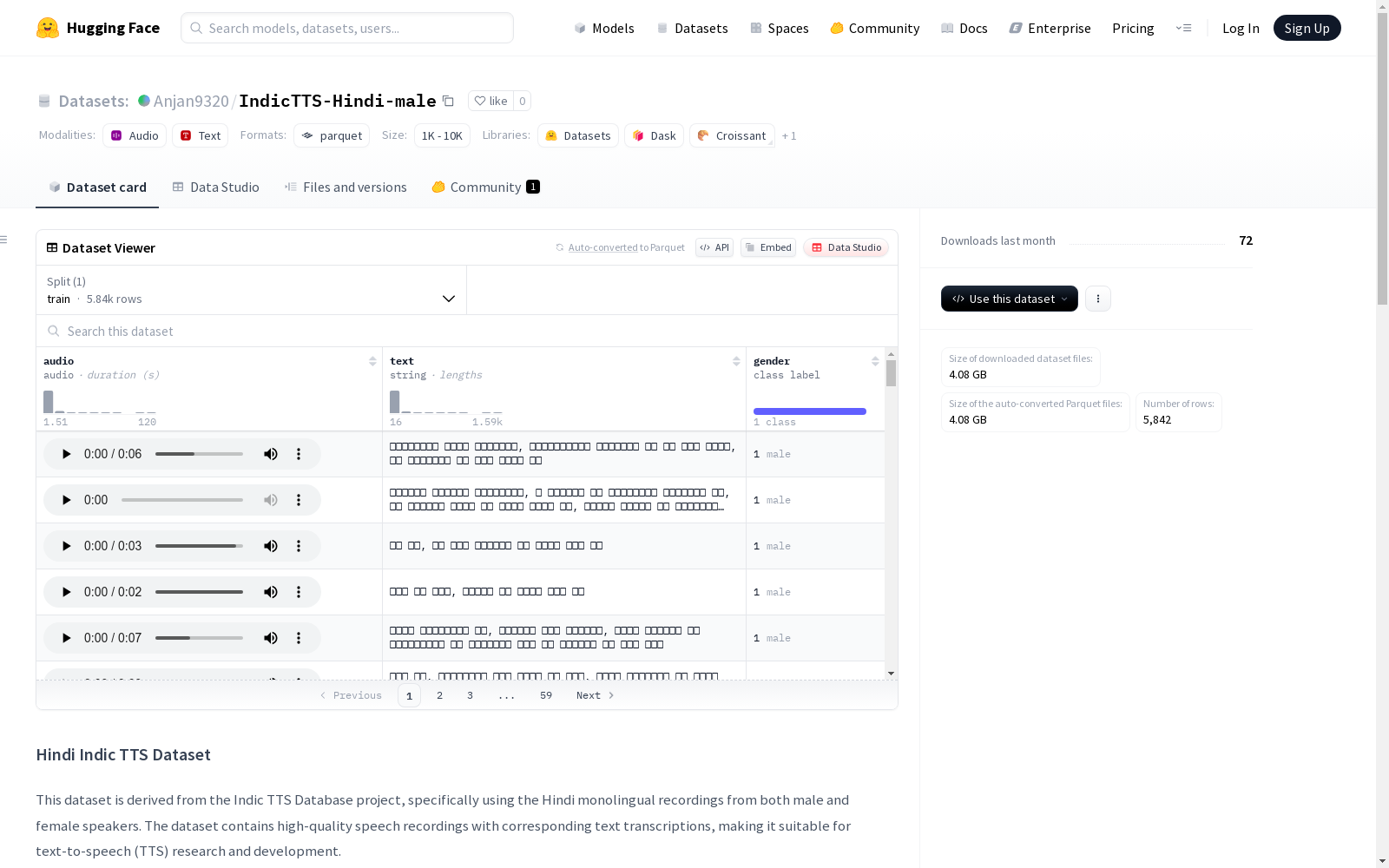
IndicTTS-Hindi-male 数据集概述
数据集基本信息
- 语言: 印地语 (Hindi)
- 音频格式: WAV
- 采样率: 48000Hz
- 总时长: 5.16小时 (男性)
- 说话人: 1位男性母语者
- 内容类型: 单语印地语发音
- 录音质量: 录音室品质
- 转录文本: 所有音频文件均提供
数据组成
- 特征列:
audio: 音频数据 (dtype: audio)text: 文本转录 (dtype: string)gender: 说话人性别 (dtype: class_label)- 标签:
- 0: female
- 1: male
- 标签:
- 数据划分:
train:- 样本数: 5842
- 数据量: 4479580899.294208字节
- 下载大小: 4079447675字节
- 数据集总大小: 4479580899.294208字节
数据来源
- 源自印度理工学院马德拉斯分校语音技术联盟开发的Indic TTS数据库
- 原始数据库覆盖13种印度主要语言,包含10000+句子/发音(单语和英语录音)
许可信息
- 受原始Indic TTS许可条款约束
- 使用前需阅读并同意许可协议
引用方式
bibtex @misc{indictts2023, title = {Indic {TTS}: A Text-to-Speech Database for Indian Languages}, author = {Speech Technology Consortium and {Hema A Murthy} and {S Umesh}}, year = {2023}, publisher = {Indian Institute of Technology Madras}, url = {https://www.iitm.ac.in/donlab/indictts/}, institution = {Department of Computer Science and Engineering and Electrical Engineering, IIT MADRAS} }
联系方式
- 数据集问题: 通过HuggingFace社区标签留言
- 原始数据库咨询: smtiitm@gmail.com
原始数据库访问
- 完整数据库地址: https://www.iitm.ac.in/donlab/indictts/database
搜集汇总
数据集介绍
构建方式
IndicTTS-Hindi-male数据集源自印度理工学院马德拉斯分校语音技术联盟开发的Indic TTS数据库项目,专注于印地语单语录音。该数据集通过专业录音设备在受控的声学环境中采集,由一位母语为印地语的男性发音人完成,共包含5842条高质量语音样本,总时长达5.16小时。所有音频均以48kHz采样率的WAV格式存储,并配有精确的文本转录,构建过程严格遵循语言学标注规范。
使用方法
研究人员可通过HuggingFace平台直接加载该数据集进行语音合成模型训练,其标准化的音频-文本配对结构兼容主流TTS框架。使用前需确认遵守Indic TTS许可条款,建议通过原始文献引用来规范学术用途。对于特定研究需求,可结合其他印度语言子集进行对比分析,或利用48kHz采样特性开展高保真语音生成实验。
背景与挑战
背景概述
IndicTTS-Hindi-male数据集源于印度理工学院马德拉斯分校语音技术联盟主导的Indic TTS Database项目,该项目致力于构建覆盖印度13种主要语言的高质量语音合成数据库。作为其重要组成部分,该数据集聚焦印地语单语种男性发音人数据,收录了5.16小时专业录音棚采集的48kHz采样率音频及对应文本转录。由Hema A Murthy和S Umesh教授领衔的研究团队通过严格的语言学标注和声学处理,为语音合成技术提供了符合印度本土语言特性的基准数据,对推动南亚次大陆多语言语音技术发展具有显著意义。
当前挑战
该数据集主要应对印度语言复杂音系结构的建模挑战,包括印地语特有的气声音素、辅音连缀等发音特征。在构建过程中,研究人员需克服低资源语言标注标准缺失的问题,通过设计音素平衡的文本语料确保发音覆盖度。录音环节面临口音纯化与发音人风格一致性的双重压力,后期处理需消除环境噪声同时保留语音自然度。多层级语言标注的精确性要求与有限母语专家资源的矛盾,进一步增加了数据质量控制难度。
常用场景
经典使用场景
在语音合成技术的研究中,IndicTTS-Hindi-male数据集作为高质量的印地语男性语音语料库,为文本到语音转换系统提供了重要的训练基础。该数据集特别适用于开发针对印度语言的TTS模型,其高保真的录音质量和精确的文本标注使得研究者能够构建更为自然和流畅的语音合成系统。
解决学术问题
该数据集有效解决了印地语语音合成研究中数据稀缺的问题,为学术界提供了标准化的研究素材。通过提供高质量的语音和文本配对,研究者能够深入探索印地语特有的语音特征和韵律模式,从而推动多语言语音合成技术的发展。
实际应用
在实际应用中,IndicTTS-Hindi-male数据集被广泛用于开发面向印度市场的语音助手、有声读物和自动客服系统。其高质量的录音和准确的转录使得基于该数据集训练的TTS系统能够更好地服务于印地语用户,提升用户体验。
数据集最近研究
最新研究方向
在语音合成技术快速发展的背景下,IndicTTS-Hindi-male数据集为印度语言文本转语音研究提供了重要资源。当前研究热点集中在多方言语音合成模型的优化,特别是针对印地语等低资源语言的声学建模改进。该数据集的高质量录音和精准标注为探索端到端神经网络TTS系统在印度语言中的应用创造了条件,相关成果已逐步应用于智能助手、无障碍技术等跨语言服务场景。随着Bhashini等国家级语言技术计划的推进,基于该数据集的发音人克隆和情感语音合成正成为学术界与工业界共同关注的焦点方向。
以上内容由遇见数据集搜集并总结生成


