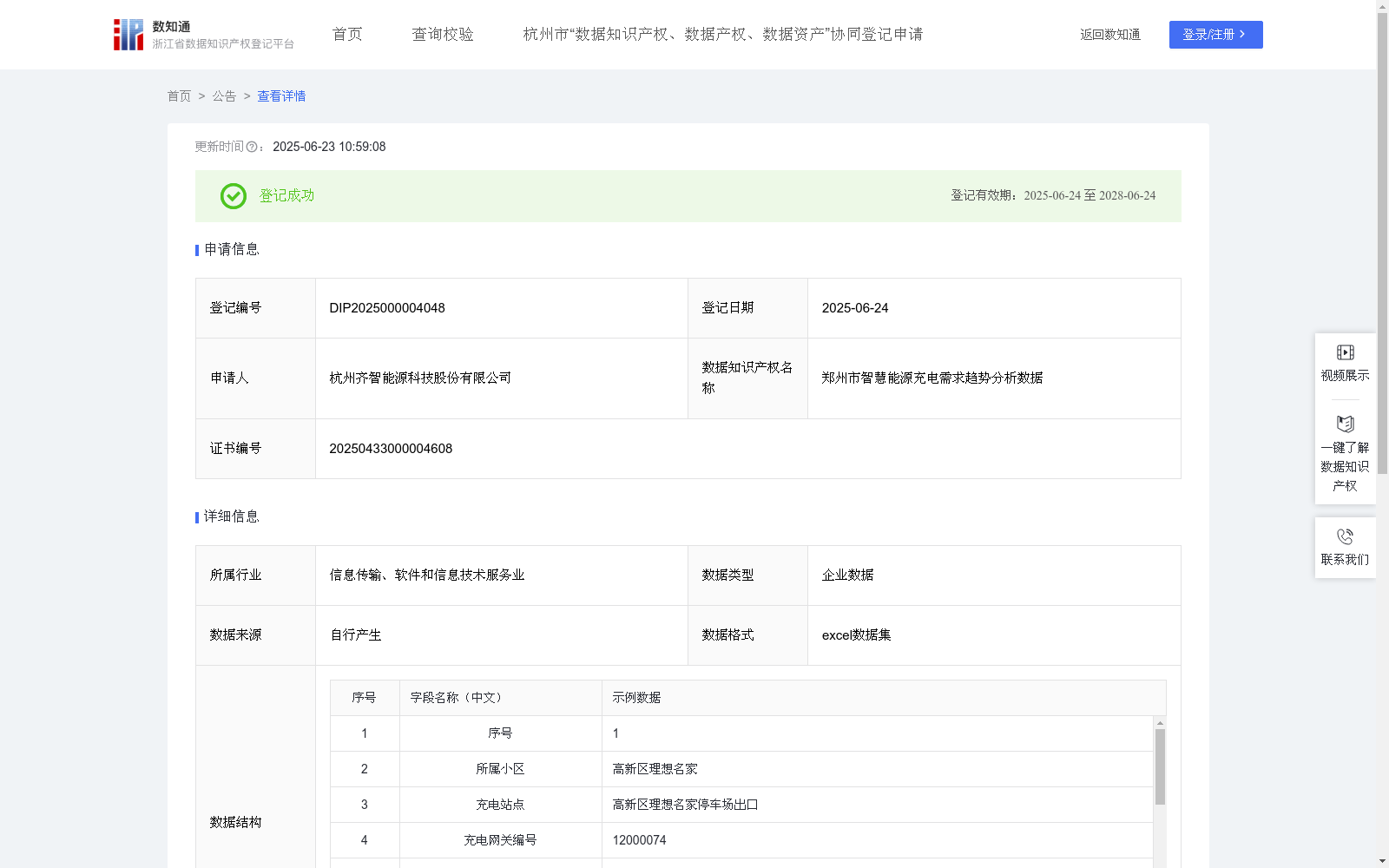
郑州市智慧能源充电需求趋势分析数据
收藏浙江省数据知识产权登记平台2025-06-23 更新2025-06-24 收录
下载链接:
https://www.zjip.org.cn/home/announce/trends/140410
下载链接
链接失效反馈官方服务:
资源简介:
通过对本地区电动自行车充电交易数据和充电功率数据的深入收集与分析,能够准确计算充电插座的充电使用率,并据此洞察充电需求的变化趋势。分析结果为电网公司和充电桩运营商提供了精准的扩容或减容决策依据,确保资源配置的科学性和合理性。充电使用率数据为市场营销策略提供坚实的数据支撑,使得运营商能够通过分析不同区域和时段的充电需求,优化充电桩的分布,进而提升用户的充电体验,增强客户吸引力和忠诚度。1、数据采集:利用智慧能源充电管理平台,采集郑州市各个充电站及充电插座业务数据。 2、数据处理:对采集到的数据进行聚合与分类,按照日期、充电站点、额定功率、充电电量、充电时长等关键维度进行梳理。 3、数据加工:一小时时间片充电费用(元)= 一小时时间片功率(281.2w)所代表的充电服务费单价 0.12(元/小时)* 一小时时间片用电量(0.195kwh)= 0.0234(元);充电费用(元)= 全部时间片累计金额;充电时长(分钟)= 全部时间片累计时长; 充电使用率(%)=充电时长/24/60*100; 4)数据分类分级:把所有计算出来的充电利用率从高到低排序,按照充电利用率将充电插座的使用率等级划分为“高效、中效、低效”共3个级别(75%以上标记为“高效”,45%-75%(含75%)的标记为“中效”,45%以下的(含45%)标记为“低效”),帮助公司更好地运营充电桩资源,提供扩容或减容的决策依据。
Through in-depth collection and analysis of charging transaction data and charging power data of electric bicycles in Zhengzhou City, the charging utilization rate of charging sockets can be accurately calculated, and the changing trends of charging demand can be thus identified. The analysis results provide precise decision-making basis for capacity expansion or reduction for power grid companies and charging pile operators, ensuring the scientificity and rationality of resource allocation. The charging utilization rate data also offers solid data support for marketing strategies, enabling operators to optimize the distribution of charging piles by analyzing charging demands across different regions and time periods, thereby improving users' charging experience and enhancing customer attractiveness and loyalty.
1. Data Collection: Utilize the smart energy charging management platform to collect business data of various charging stations and charging sockets in Zhengzhou City.
2. Data Processing: Aggregate and classify the collected data, and organize it according to key dimensions including date, charging station, rated power, charging energy, and charging duration.
3. Data Processing & Calculation: Charging cost per one-hour time slot (yuan) = unit price of charging service fee (0.12 yuan/hour) corresponding to the power of the one-hour time slot (281.2W) * power consumption of the one-hour time slot (0.195 kWh) = 0.0234 (yuan); Total charging cost (yuan) = cumulative amount of all time slots; Total charging duration (minutes) = cumulative duration of all time slots; Charging utilization rate (%) = (total charging duration / 24 / 60) * 100.
4. Data Classification and Grading: Sort all calculated charging utilization rates in descending order, and divide the utilization levels of charging sockets into three categories: "high-efficiency", "medium-efficiency" and "low-efficiency" based on the charging utilization rate: marked as "high-efficiency" for rates above 75%, "medium-efficiency" for rates ranging from 45% to 75% (including 75%), and "low-efficiency" for rates below 45% (including 45%). This helps the company better operate charging pile resources and provides decision-making basis for capacity expansion or reduction.
提供机构:
杭州齐智能源科技股份有限公司
创建时间:
2025-04-30
搜集汇总
数据集介绍
背景与挑战
背景概述
该数据集聚焦于郑州市电动自行车充电需求趋势分析,包含524条每日更新的记录,详细记录了充电站点、日期、功率、时长、电量、费用及使用率等20个关键字段。通过计算充电使用率并划分为高效、中效、低效等级,数据旨在为电网公司和充电桩运营商提供扩容减容决策依据,并优化充电桩分布以提升用户体验和运营效率。
以上内容由遇见数据集搜集并总结生成


