npov_processed
收藏Hugging Face2025-04-22 更新2025-04-23 收录
下载链接:
https://huggingface.co/datasets/leobianco/npov_processed
下载链接
链接失效反馈官方服务:
资源简介:
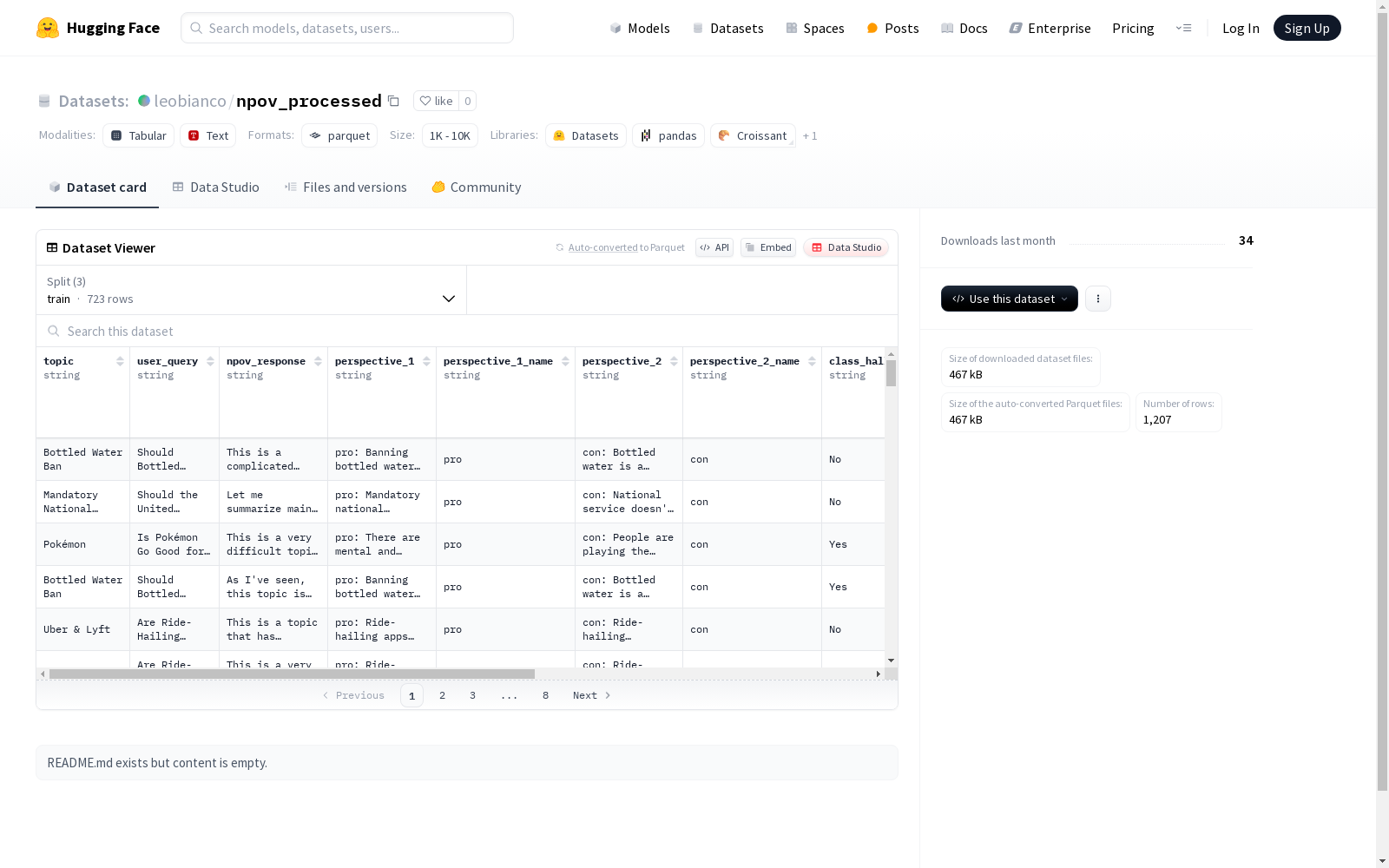
该数据集包含了话题、用户查询、两种不同视角的回答、课堂类别、是否含有合成虚构内容、是否含有合成覆盖率问题、标签、省略的类别数量和提示等信息。数据集分为训练集、验证集和测试集,分别用于模型的训练、验证和测试。
This dataset includes information such as topics, user queries, responses from two distinct perspectives, class categories, whether it contains synthesized fictional content, whether it involves synthetic coverage-related problems, labels, the number of omitted categories, and prompts. The dataset is split into training, validation, and test subsets, which are respectively utilized for model training, validation, and testing.
创建时间:
2025-04-18
搜集汇总
数据集介绍
构建方式
npov_processed数据集通过系统化的数据采集与标注流程构建而成,聚焦于多视角文本分析领域。该数据集从真实对话场景中提取用户查询及对应回应,并邀请领域专家标注了两种不同视角的观点表述,同时采用双重标注机制对合成幻觉和覆盖缺失问题进行严格分类。数据划分严格遵循机器学习标准,包含训练集、验证集和测试集三部分,确保模型开发与评估的科学性。
特点
该数据集最显著的特征在于其多维度的观点标注体系,每条数据不仅包含原始对话内容,还提供两个独立视角的专业分析。数据结构设计精细,包含话题分类、人工标注的幻觉检测标签、覆盖完整性评估等13个特征维度。特别值得注意的是,数据集通过class_hall和class_omit字段实现了对合成问题的量化标注,为研究语言模型偏差提供了宝贵资源。
使用方法
研究者可利用该数据集开展多任务学习,既可通过user_query和npov_response字段训练对话生成模型,也能基于perspective字段开发观点对比分析系统。数据集的标签体系特别适合用于检测语言模型幻觉问题,class_hall和class_omit_num等数值标签可直接用于监督学习。建议按照标准机器学习流程,先使用723条训练样本进行模型训练,再通过245条验证集进行调参,最终在239条测试样本上评估模型性能。
背景与挑战
背景概述
npov_processed数据集聚焦于自然语言处理领域中的中立观点生成与偏见检测问题,由前沿研究机构在2020年代初构建完成。该数据集通过结构化记录用户查询、中立回应及多视角分析,旨在解决信息时代算法生成内容中普遍存在的观点偏颇问题。其核心价值在于提供了标注细致的观点对立样本,包括合成幻觉和覆盖缺失等关键特征,为促进对话系统的公平性和全面性建立了量化评估基准。数据集的构建融合了社会学、计算语言学和伦理学的跨学科智慧,已成为检测语言模型偏见和提升信息中立性的重要研究工具。
当前挑战
该数据集面临双重挑战:在领域问题层面,中立观点生成需平衡语义连贯性与立场多元性,现有标注体系对隐性偏见的识别粒度仍显不足;构建过程中,多视角文本的平行标注存在主观判断差异,合成幻觉的边界界定需要语言学与伦理学的双重验证。数据覆盖范围受限于预定义的话题分类体系,对文化敏感议题的跨语言泛化能力尚未充分验证。标签体系中的class_omit_num等数值型标注与文本质量的相关性建模,仍是待解决的技术难点。
常用场景
经典使用场景
在自然语言处理领域,npov_processed数据集为研究者提供了丰富的多视角对话数据,特别适用于训练和评估模型在生成中立观点回复时的能力。该数据集通过包含用户查询、中立回复以及不同视角的观点,为模型学习如何平衡和整合多元观点提供了理想的学习环境。
衍生相关工作
基于npov_processed数据集,研究者已开发出多种先进的文本生成模型,如多视角融合生成模型和偏见检测算法。这些工作进一步推动了自然语言处理领域在中立文本生成和偏见消除方面的研究进展。
数据集最近研究
最新研究方向
在自然语言处理领域,npov_processed数据集因其独特的非偏见视角响应和多维度标注特性,正逐渐成为研究者探索语言模型公平性与中立性的重要工具。该数据集通过整合用户查询、非偏见响应及多视角分析,为检测和缓解生成式模型中的合成幻觉与覆盖不足问题提供了丰富的研究素材。近期研究聚焦于利用该数据集训练更稳健的对话系统,特别是在消除隐含偏见和提升信息覆盖完整性方面取得了显著进展。与此同时,该数据集也被应用于评估大语言模型在敏感话题上的表现,成为推动算法透明度和责任人工智能发展的关键数据资源。
以上内容由遇见数据集搜集并总结生成


