neurips_submission_23
收藏Hugging Face2025-05-16 更新2025-05-17 收录
下载链接:
https://huggingface.co/datasets/annonymousa378/neurips_submission_23
下载链接
链接失效反馈官方服务:
资源简介:
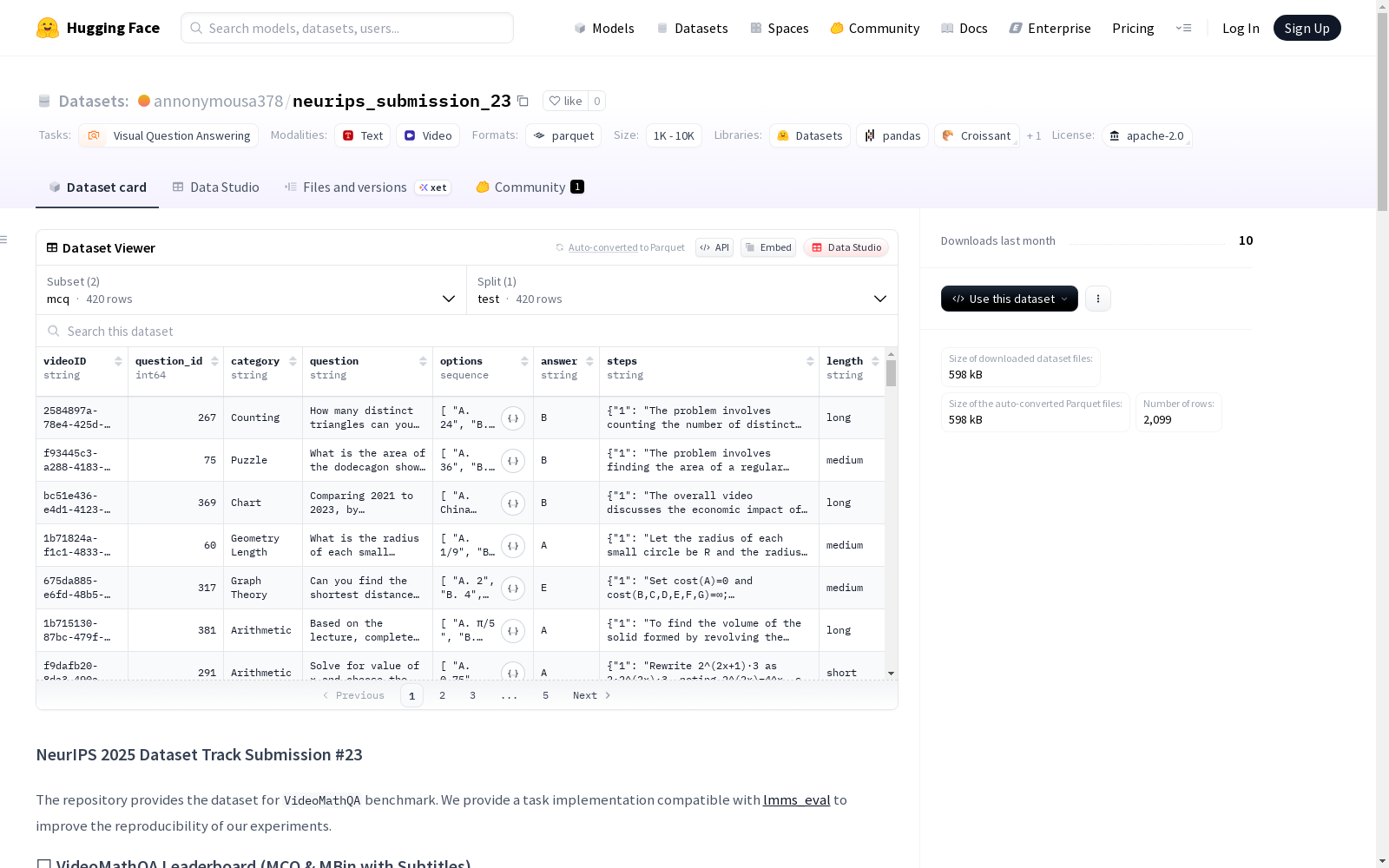
VideoMathQA数据集是一个针对视觉问答任务的标准测试集。该数据集包含了用于训练、验证和测试的多个任务,如多项选择题(MCQ)和多项二元选择题(MBin),并提供有和无字幕的版本以及逐步思考的CoT(Chain of Thought)变体。数据集以Parquet格式存储,并包含了一个模型性能排行榜,展示了不同模型在该数据集上的表现。
The VideoMathQA dataset is a standardized test set for visual question answering (VQA) tasks. It encompasses multiple task types for training, validation and testing splits, including Multiple-Choice Questions (MCQ) and Multiple Binary-choice Questions (MBin). It provides both subtitled and unsubtitled versions, as well as Chain of Thought (CoT) variants with step-by-step reasoning. The dataset is stored in Parquet format and includes a model performance leaderboard that showcases the performance of different models evaluated on this dataset.
创建时间:
2025-05-16
搜集汇总
数据集介绍
构建方式
在视频理解与数学推理交叉领域,VideoMathQA基准数据集通过精心设计的双配置架构构建而成。该数据集采用多选题与多二元分类两种评估模式,分别对应mcq和multi_binary两种配置类型。数据以标准化parquet格式存储,确保高效读取与处理。构建过程中特别注重视频内容与数学问题的语义对齐,每个样本均包含视频片段与对应的数学问题,形成完整的视觉-语言推理单元。
特点
该数据集最显著的特征在于其多模态评估框架的完整性。不仅提供基础的视频问答任务,还创新性地引入字幕增强版本与思维链推理变体,形成八种不同的任务配置。数据集涵盖从简单计算到复杂逻辑推导的数学问题类型,充分考验模型在时空维度上的推理能力。评测榜单呈现了从7B到78B参数规模的各种模型表现,为多模态数学推理研究提供了权威的基准参照。
使用方法
研究人员可通过lmms_eval评估框架便捷地使用该数据集。使用流程包括环境配置、依赖安装与任务执行三个主要阶段。评估时支持数据并行与张量并行两种分布式策略,适应不同规模的模型需求。特别提供的思维链评估脚本能深入分析模型的推理过程,而字幕增强任务则允许探究辅助信息对模型性能的影响。整个评估体系设计科学,确保了实验结果的可复现性与可比性。
背景与挑战
背景概述
视频数学问答数据集作为神经信息处理系统大会2025年数据集赛道的官方提交项目,由EvolvingLMMs-Lab研究团队于2024年构建完成。该数据集聚焦于多模态推理领域,核心研究目标在于评估大型语言模型对视频场景中数学问题的时空逻辑解析能力。通过融合视觉动态信息与文本字幕数据,该基准测试推动了视频语义理解与数学推理的交叉研究,为构建具备时序认知能力的通用人工智能奠定了实证基础。
当前挑战
在领域问题层面,视频数学问答需攻克动态视觉特征提取与多步数学推理的协同建模难题,现有模型在时序语义对齐和符号运算的融合处理上表现仍不理想。数据构建过程中面临视频片段数学问题标注的复杂性,需要平衡视觉场景多样性与数学问题严谨性,同时确保字幕文本与视频内容的时序一致性,这对标注专家的跨学科知识提出了较高要求。
常用场景
经典使用场景
在视觉问答领域,VideoMathQA数据集通过视频与数学问题的结合,为多模态大语言模型提供了标准化的评估基准。其经典使用场景聚焦于模型对动态视觉信息的数学推理能力测试,涵盖选择题与多二元分类两种任务模式。该数据集通过字幕增强与思维链提示等变体,系统考察模型在时序推理和符号逻辑整合方面的表现,成为衡量多模态模型数学认知水平的重要试金石。
衍生相关工作
基于该基准催生了系列创新研究,如Qwen2.5-VL提出的视觉语言联合表征框架,以及InternVL3探索的跨模态注意力机制。思维链提示技术的引入推动了可解释性推理模型的发展,而字幕增强任务则促进了多信号融合方法的研究。这些工作共同构成了视频数学推理领域的技术图谱,为后续时序多模态预训练提供了重要借鉴。
数据集最近研究
最新研究方向
在视觉语言推理领域,VideoMathQA数据集正推动多模态数学问题求解的前沿探索。当前研究聚焦于视频时序理解与符号推理的深度融合,通过引入思维链(CoT)提示机制和字幕增强技术,显著提升了模型对动态数学场景的解析能力。最新评估显示,闭源模型如GPT-4o-mini在多项选择题(MCQ)和多元二分类(MBin)任务中分别达到61.4%和44.2%的准确率,而开源模型如Qwen2.5-VL-72B通过参数扩展与注意力优化紧追其后。这一进展不仅推动了教育技术中自适应学习系统的发展,更为具身智能的因果推理能力奠定了关键基准。
以上内容由遇见数据集搜集并总结生成


