freesound-laion-640k
收藏Hugging Face2024-09-01 更新2024-12-12 收录
下载链接:
https://huggingface.co/datasets/benjamin-paine/freesound-laion-640k
下载链接
链接失效反馈官方服务:
资源简介:
LAION-Audio-630K是一个大规模的音频-文本数据集,包含633,526对音频和文本,总时长为4,325.39小时。数据集包含人类活动、自然声音和音频效果等多种音频,来源于公开可用的网站。数据集由LAION组织收集,包含音频文件及其相关元数据,如标题、描述、标签、用户名、freesound_id、许可证类型等。数据集分为训练集和测试集,分别包含455019和50599个样本。音频文件遵循多种许可证,包括CC0-1.0、CC-BY-4.0等。数据集的主要用途是音频分类和音频到音频的任务。
LAION-Audio-630K is a large-scale audio-text dataset containing 633,526 audio-text pairs with a total duration of 4,325.39 hours. It covers various audio types including human activities, natural sounds, and audio effects, sourced from publicly available websites. Collected by the LAION organization, the dataset includes audio files and their associated metadata such as title, description, tags, username, freesound_id, license type, and so on. The dataset is split into a training set and a test set, which contain 455,019 and 50,599 samples respectively. The audio files are governed by multiple licenses including CC0-1.0, CC-BY-4.0, and others. The primary applications of this dataset are audio classification and audio-to-audio tasks.
创建时间:
2024-08-30
原始信息汇总
FreeSound.org LAION-640k 数据集
数据集概述
- 名称: FreeSound.org LAION-640k 数据集
- 来源: 由LAION从FreeSound.org数据集重新整理
- 修改内容:
- 仅保留音频和基本元数据列。
- 包含必要的许可和署名信息。
- 移除约1,000个模糊许可的样本。
数据集结构
- 配置:
default
- 数据文件:
train:data/train-*test:data/test-*
数据特征
- 音频:
audio(音频类型) - 标题:
title(字符串类型) - 描述:
description(字符串类型) - 标签:
tags(字符串序列) - 用户名:
username(字符串类型) - FreeSound ID:
freesound_id(无符号64位整数类型) - 许可:
license(类别标签)CC0-1.0CC-BY-4.0CC-BY-3.0CC-BY-NC-3.0CC-BY-NC-4.0CC-Sampling+
- 署名要求:
attribution_required(类别标签)NoYes
- 商业使用:
commercial_use(类别标签)NoYes
数据分割
- 训练集:
- 样本数: 455019
- 字节数: 675888345929.433
- 测试集:
- 样本数: 50599
- 字节数: 61089398662.586
数据集大小
- 下载大小: 678850663953
- 数据集大小: 736977744592.019
许可
- 数据集元数据: MIT许可证
- 音频: 五种许可之一
CC0-1.0CC-BY-NC 4.0CC-BY-NC 3.0CC-BY 4.0CC-BY 3.0CC-Sampling+
任务类别
- 音频转音频
- 音频分类
标签
freesoundfreesound.orglaionlaion-audio
搜集汇总
数据集介绍
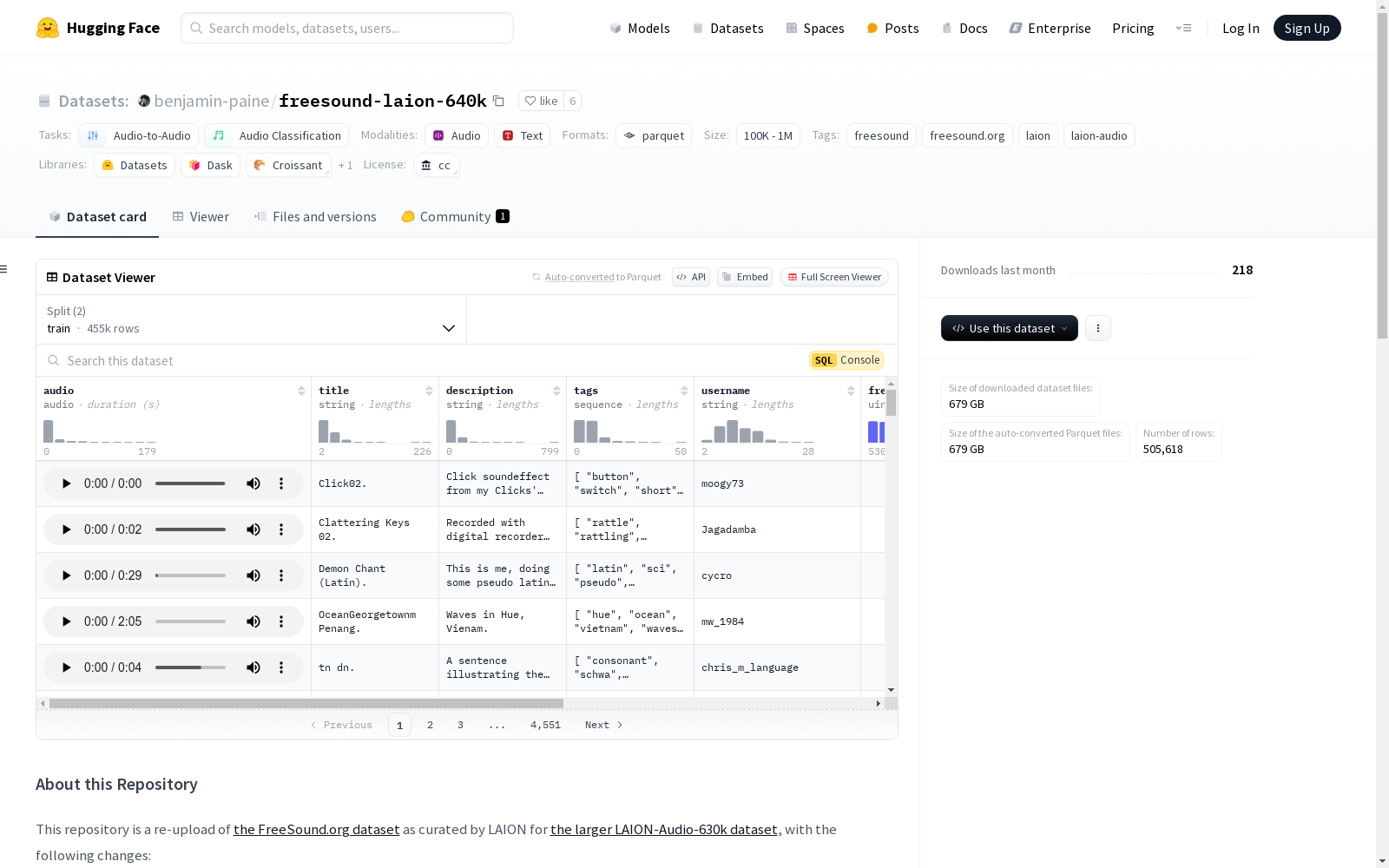
构建方式
freesound-laion-640k数据集是基于FreeSound.org平台上的音频资源,由LAION组织精心筛选和整理而成。该数据集从原始的LAION-Audio-630k数据集中提取了音频及其相关元数据,并剔除了许可证不明确的样本,最终保留了约640,000个音频样本。每个样本包含音频文件、标题、描述、标签、用户名、FreeSound ID以及许可证信息,确保了数据的完整性和合法性。
特点
freesound-laion-640k数据集以其多样性和规模著称,涵盖了人类活动、自然声音和音效等多种音频类型。每个音频样本均附有详细的元数据,包括标题、描述、标签和许可证信息,便于用户快速定位和理解音频内容。此外,数据集还特别标注了音频的许可要求,如是否需要署名或是否可用于商业用途,为用户提供了明确的使用指引。
使用方法
使用freesound-laion-640k数据集时,用户可通过HuggingFace平台直接访问数据文件,并根据需要下载训练集和测试集。每个音频样本的下载链接可通过用户名和FreeSound ID动态生成,格式为`https://freesound.org/people/{username}/sound/{id}`。在使用音频时,用户需严格遵守其对应的许可证要求,确保在合法范围内进行研究和应用。
背景与挑战
背景概述
freesound-laion-640k数据集是由LAION组织基于FreeSound.org平台上的音频数据构建而成,旨在为音频-文本对研究提供大规模、多样化的数据支持。该数据集于2022年发布,是LAION-Audio-630k数据集的一部分,包含了超过63万条音频-文本对,总时长超过4,325小时。其核心研究问题在于如何通过音频与文本的关联,推动音频分类、音频生成等任务的发展。该数据集的出现填补了大规模音频-文本数据集的空白,为音频领域的深度学习研究提供了重要资源。
当前挑战
freesound-laion-640k数据集在构建与应用中面临多重挑战。首先,音频数据的多样性与复杂性使得高质量的音频-文本对齐成为难题,尤其是在自然声音和人类活动音频的标注上。其次,数据集的构建过程中需处理大量来自不同来源的音频,其格式、质量和元数据的不一致性增加了数据清洗与标准化的难度。此外,音频的版权问题也带来了挑战,数据集需严格遵循多种开源许可协议,确保数据的合法使用。最后,如何在海量数据中提取有效特征并应用于实际任务,仍需进一步研究。
常用场景
经典使用场景
freesound-laion-640k数据集在音频处理领域具有广泛的应用,尤其是在音频分类和音频生成任务中。研究人员可以利用该数据集中的音频样本及其对应的文本描述,训练深度学习模型以识别不同类别的音频信号,或生成与特定文本描述相匹配的音频内容。该数据集的高质量和多样性使其成为音频-文本对研究的理想选择。
实际应用
在实际应用中,freesound-laion-640k数据集可用于开发智能音频编辑工具、语音助手和音频内容推荐系统。例如,基于该数据集训练的模型可以自动生成与用户输入文本相匹配的背景音乐,或根据音频内容推荐相关的标签和描述。此外,该数据集还可用于教育领域,帮助学生学习音频处理和生成技术。
衍生相关工作
freesound-laion-640k数据集衍生了许多经典的研究工作,尤其是在音频生成和跨模态学习领域。例如,基于该数据集的研究成果包括音频-文本对齐模型、音频生成模型以及多模态学习框架。这些工作不仅推动了音频处理技术的发展,还为其他领域如自然语言处理和计算机视觉提供了跨模态学习的参考。
以上内容由遇见数据集搜集并总结生成


