UrbanNav
收藏Hugging Face2025-12-22 更新2025-12-23 收录
下载链接:
https://huggingface.co/datasets/Vigar001/UrbanNav
下载链接
链接失效反馈官方服务:
资源简介:
UrbanNav是一个用于学习语言引导城市导航的数据集,基于网络规模的人类轨迹数据。数据集包含从YouTube下载的视频、轨迹数据和指令注释,用于训练和评估导航模型。数据集的准备过程包括视频下载、分割、帧提取和注释合并。数据集结构包括视频帧、轨迹数据文件和标签文件。部分数据经过清洗流程过滤,未包含注释。数据集适用于机器人技术和计算机视觉任务。
UrbanNav is a dataset for learning language-guided urban navigation, built upon web-scale human trajectory data. The dataset comprises videos downloaded from YouTube, trajectory data and instruction annotations, which are utilized for training and evaluating navigation models. The dataset preparation workflow includes video downloading, segmentation, frame extraction and annotation merging. The dataset structure consists of video frames, trajectory data files and label files. A subset of the data has been filtered through a cleaning pipeline and does not contain any annotations. This dataset is applicable to robotics and computer vision tasks.
创建时间:
2025-12-17
原始信息汇总
UrbanNav 数据集概述
数据集基本信息
- 数据集名称: UrbanNav
- 语言: 英语 (en)
- 许可证: MIT
- 任务类别: 机器人学 (robotics)
- 标签: 机器人学 (robotics), 计算机视觉 (cv)
- 数据规模: 大于1M (n>1M)
- 主页: https://github.com/Vigar0108M/UrbanNav
数据集描述
UrbanNav 是一个用于学习语言引导城市导航的数据集,其数据来源于网络规模的人类轨迹。
数据内容与结构
数据集包含从 YouTube 视频中提取的轨迹数据和语言指令标注。数据组织方式如下:
UrbanNav/data ├── <video_name_0000> | ├── 0000.jpg | ├── 0001.jpg | ├── ... | ├── T_1.jpg | ├── traj_data.pkl | └── label.json ├── <video_name_0001> | ├── 0000.jpg | ├── 0001.jpg | ├── ... | ├── T_2.jpg | ├── traj_data.pkl | └── label.json | ... └── <video_name_N> ├── 0000.jpg ├── 0001.jpg ├── ... ├── T_N.jpg ├── traj_data.pkl └── label.json
每个轨迹文件夹包含按1 FPS频率提取的图像帧(.jpg)、轨迹数据文件(traj_data.pkl)和语言指令标注文件(label.json)。
数据获取与准备
- 下载视频: 根据
video_list.txt中的视频ID列表,下载360p分辨率、30 FPS的YouTube视频。 - 下载标注: 从 Hugging Face (https://huggingface.co/datasets/Vigar001/UrbanNav) 下载
annos.tar.gz并解压。 - 处理流程:
- 使用
scripts/split_video_parallel.py将原始视频分割为120秒的片段。 - 使用
scripts/extract_video_frames.py以1 FPS的频率从视频片段中提取图像帧(若视频为30 FPS,需设置步长--stride 30)。 - 使用
scripts/merge_annotations.py将标注文件合并到对应的轨迹文件夹中。
- 使用
重要说明
- 大约50%的数据在数据清理流程中被过滤,这些轨迹没有标注,其列表保存在
filtered_trajs.txt中,可安全删除以释放存储空间。 - 相关论文为《UrbanNav: Learning Language-Guided Urban Navigation from Web-Scale Human Trajectories》,arXiv地址为 https://arxiv.org/abs/2512.09607。
搜集汇总
数据集介绍
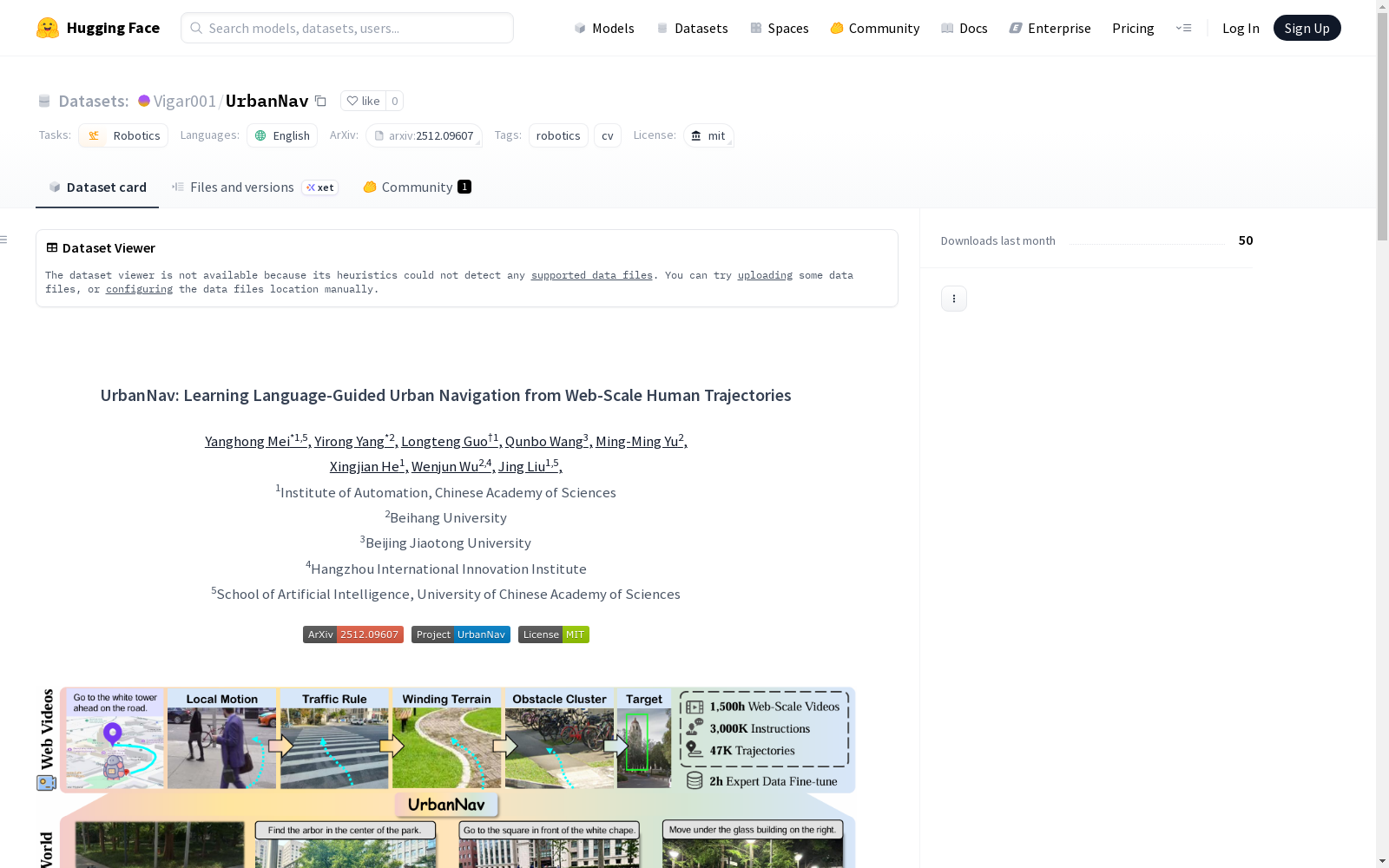
构建方式
在机器人学与计算机视觉交叉领域,UrbanNav数据集的构建体现了从海量真实世界数据中提炼导航知识的系统性方法。其核心数据源来自公开的YouTube视频,通过筛选特定视频列表并下载360p分辨率、30帧率的原始素材。构建流程首先将长视频分割为120秒的片段,随后以1帧每秒的频率抽取图像帧,确保时序连续性。轨迹数据与语言指令标注则通过独立渠道获取,最终通过自动化脚本将标注与视觉数据精准对齐,并经过严格的数据清洗流程,过滤了近半数不符合质量要求的轨迹,从而保证了数据集的可靠性与一致性。
使用方法
为有效利用UrbanNav数据集进行研究与开发,使用者需遵循一套标准化的数据准备流程。首先需依据提供的视频列表下载原始视频,并同步获取Hugging Face平台上发布的轨迹与标注压缩包。随后,利用项目提供的并行处理脚本依次执行视频分割、帧抽取与标注合并操作。关键步骤在于设置正确的帧抽取步长以匹配原始视频帧率,确保视觉序列与标注的时间戳对齐。数据处理完毕后,数据集将呈现为以轨迹为单位的文件夹结构,内含图像、轨迹数据及JSON格式的标签,研究者可直接将其输入模型进行语言条件化导航策略的学习。
背景与挑战
背景概述
UrbanNav数据集由中国科学院自动化研究所、北京航空航天大学等机构的研究团队于2025年共同构建,旨在推动语言引导的城市导航研究。该数据集的核心研究问题聚焦于如何利用大规模人类轨迹数据,结合自然语言指令,训练智能体在复杂城市环境中实现精准导航。其创新之处在于从网络视频中提取真实世界的人类移动轨迹,并配以语言描述,为机器人学与计算机视觉的交叉领域提供了前所未有的多模态学习资源,有望显著提升导航系统在动态开放场景中的泛化与理解能力。
当前挑战
在领域层面,UrbanNav致力于解决语言引导的视觉导航这一核心挑战,其难点在于如何让智能体准确理解模糊或复杂的自然语言指令,并在充满动态障碍物、视角变化与长程依赖的真实城市街道中规划出合理路径。在构建过程中,研究团队面临从海量网络视频中自动化提取、对齐与清洗轨迹数据的艰巨任务,需克服视频质量参差、标注噪声巨大以及时空信息校准等难题,最终通过精心设计的数据处理流程,确保了轨迹与语言标注的高质量对齐。
常用场景
经典使用场景
在机器人学与计算机视觉交叉领域,UrbanNav数据集为语言引导的视觉导航研究提供了关键支撑。其经典使用场景集中于训练和评估端到端的导航模型,模型通过解析自然语言指令,结合第一人称视角的连续视觉帧序列,学习在复杂城市环境中规划并执行行进轨迹。该场景深刻体现了从感知到行动的闭环学习范式,为智能体在真实世界中的自主移动奠定了数据基础。
解决学术问题
UrbanNav数据集主要致力于解决视觉语言导航中数据规模与真实性的瓶颈问题。传统数据集往往受限于模拟环境或小规模人工标注,难以捕捉真实城市动态的多样性与复杂性。该数据集通过采集海量网络人类轨迹视频及伴随的文本指令,为研究社区提供了大规模、高真实度的配对数据,从而推动模型在开放环境下的泛化能力、长时程规划以及复杂指令理解等核心学术问题的探索。
实际应用
该数据集的实际应用场景直接关联于下一代自主移动系统的开发。基于UrbanNav训练的模型,可赋能服务机器人、自动驾驶车辆乃至增强现实导航应用,使其能够理解如“请带我到前方第二个路口左转的蓝色建筑”这类富含语义的复杂指令,并在真实的城市街道、公园等动态场景中安全、高效地完成导航任务,提升人机交互的自然性与智能系统的实用性。
数据集最近研究
最新研究方向
在机器人学与计算机视觉交叉领域,UrbanNav数据集的推出标志着基于语言引导的视觉导航研究迈入新阶段。该数据集通过整合海量网络人类轨迹与自然语言指令,为构建能够理解复杂城市环境并执行高层语义导航任务的智能体提供了关键训练资源。当前前沿探索聚焦于如何利用大规模多模态轨迹数据,结合视觉语言模型与强化学习框架,实现从开放世界视频中直接学习鲁棒且泛化性强的导航策略。这一方向紧密关联具身智能与通用机器人技术的发展热潮,其成果有望推动自动驾驶、服务机器人等应用在动态城市场景中的自主性与适应性实现实质性突破。
以上内容由遇见数据集搜集并总结生成


