md-nishat-008/Bangla-Code-Instruct
收藏Hugging Face2026-03-28 更新2026-03-29 收录
下载链接:
https://hf-mirror.com/datasets/md-nishat-008/Bangla-Code-Instruct
下载链接
链接失效反馈官方服务:
资源简介:
---
license: cc-by-4.0
language:
- bn
- en
task_categories:
- text-generation
tags:
- code
- bangla
- bengali
- code-generation
- instruction-tuning
- low-resource
- nlp
size_categories:
- 100K<n<1M
---
<div align="center">
<img src="https://img.shields.io/badge/🐯_Bangla--Code--Instruct-300K-orange?style=for-the-badge" alt="Bangla-Code-Instruct"/>
<h1 style="color: #2e8b57;">🐯 Bangla-Code-Instruct: A Comprehensive Bangla Code Instruction Dataset</h1>
<h3>Accepted at LREC 2026</h3>
<h4>Nishat Raihan, Antonios Anastasopoulos, Marcos Zampieri</h4>
<h5>George Mason University, Fairfax, VA, USA</h5>
<br/>
<table>
<tr>
<td>
<a href="https://arxiv.org/abs/2509.09101">
<img src="https://img.shields.io/badge/arXiv-2509.09101-b31b1b?style=for-the-badge&logo=arxiv" alt="arXiv"/>
</a>
</td>
<td>
<a href="https://arxiv.org/pdf/2509.09101">
<img src="https://img.shields.io/badge/Paper-Read_PDF-blue?style=for-the-badge&logo=adobeacrobatreader" alt="Read PDF"/>
</a>
</td>
<td>
<a href="mailto:mraihan2@gmu.edu">
<img src="https://img.shields.io/badge/Email-Contact_Us-green?style=for-the-badge&logo=gmail" alt="Contact Us"/>
</a>
</td>
</tr>
</table>
<table>
<tr>
<td>
<a href="https://huggingface.co/md-nishat-008/TigerCoder-1B">
<img src="https://img.shields.io/badge/🤗_HuggingFace-TigerCoder--1B-yellow?style=for-the-badge" alt="TigerCoder-1B"/>
</a>
</td>
<td>
<a href="https://huggingface.co/md-nishat-008/TigerCoder-9B">
<img src="https://img.shields.io/badge/🤗_HuggingFace-TigerCoder--9B-yellow?style=for-the-badge" alt="TigerCoder-9B"/>
</a>
</td>
<td>
<a href="https://huggingface.co/datasets/md-nishat-008/Bangla-Code-Instruct">
<img src="https://img.shields.io/badge/🤗_HuggingFace-Bangla--Code--Instruct-yellow?style=for-the-badge" alt="Bangla-Code-Instruct"/>
</a>
</td>
</tr>
</table>
<br/>
**The first large-scale Bangla code instruction dataset (300K examples) for training Code LLMs in Bangla.**
</div>
---
> **⚠️ Note:** The dataset will be released after the LREC 2026 conference. Stay tuned!
## Overview
**Bangla-Code-Instruct** is a comprehensive instruction-tuning dataset comprising **300,000 Bangla instruction-code pairs**, specifically designed for adapting LLMs to Bangla code generation. It is the first dataset of its kind for Bangla, addressing the critical lack of high-quality programming data for the 5th most spoken language globally (242M+ native speakers).
The dataset was used to train the [TigerCoder](https://huggingface.co/md-nishat-008/TigerCoder-1B) family of models, which achieve 11-18% Pass@1 improvements over prior baselines and surpass models up to 27x their size on Bangla code generation benchmarks.
## Dataset Composition
Bangla-Code-Instruct consists of three complementary 100K subsets, each constructed using a distinct methodology to maximize diversity and quality:
| Subset | Size | Method | Seed/Source | Teacher Model(s) | Prompt Origin | Code Origin |
|:---|:---:|:---|:---|:---|:---|:---|
| **SI** (Self-Instruct) | 100,000 | Self-Instruction | 5,000 expert seeds | GPT-4o | Semi-Natural | Synthetic |
| **Syn** (Synthetic) | 100,000 | Synthetic Generation | Set of Topics | GPT-4o, Claude 3.5 | Synthetic | Synthetic |
| **TE** (Translated) | 100,000 | MT + Filtering | Evol-Instruct | NLLB-200 | Translated | Natural (Source) |
### Bangla-Code-Instruct-SI (Self-Instruct)
This subset starts from **5,000 seed prompts manually authored in Bangla by programming experts**. These seeds are expanded into 100K semi-natural instructional prompts using GPT-4o via a self-instruction pipeline. The corresponding Python code for each instruction is generated by GPT-4o and validated through both syntax checking (`ast.parse`) and successful execution (Python 3.13.0, 10s timeout, 16GB memory). Diversity filtering is applied using cosine similarity to avoid redundant examples.
### Bangla-Code-Instruct-Syn (Synthetic)
This subset contains 100K **fully synthetic** Bangla instruction-Python code pairs generated by GPT-4o and Claude 3.5-Sonnet. To ensure instructional diversity, new instructions are compared against existing ones; a BERTScore of ≥ 0.7 against any existing instruction results in the new pair being discarded. Code is validated for syntax and execution (similar to SI). This subset complements the human-seeded data by broadening task diversity through purely synthetic generation.
### Bangla-Code-Instruct-TE (Translated + Filtered)
The final subset translates English instructions from Evol-Instruct into Bangla using multiple MT models, selecting the best translation based on **CometKiwi-22 QE (> 0.85)** and **BERTScore F1 (> 0.95)**. The original English source code is retained, providing naturally written code paired with high-quality Bangla translations.
## Quality Control
| Aspect | SI | Syn | TE |
|:---|:---|:---|:---|
| Code Validation | Syntax + Execution Check | Syntax + Execution Check | Retained Source Code |
| Diversity Filtering | Cosine Similarity | BERTScore | BERTScore + Comet QE |
| Execution Environment | Python 3.13.0, 10s timeout, 16GB RAM | Python 3.13.0, 10s timeout, 16GB RAM | N/A (source code retained) |
## Dataset Statistics
| Property | Value |
|:---|:---|
| Total Examples | 300,000 |
| Subsets | 3 (SI, Syn, TE) |
| Instruction Language | Bangla |
| Code Language | Python |
| Expert-Authored Seeds (SI) | 5,000 |
| Teacher Models | GPT-4o, Claude 3.5-Sonnet |
| MT Model (TE) | NLLB-200 |
## Ablation: Impact of Dataset Combinations
Fine-tuning experiments on TigerCoder models reveal clear synergistic effects when combining subsets:
| Dataset Combination | TigerCoder-1B (MBPP P@1) | TigerCoder-9B (MBPP P@1) |
|:---|:---:|:---:|
| None (base TigerLLM) | 0.65 | 0.61 |
| SI only | 0.66 | 0.66 |
| Syn only | 0.63 | 0.63 |
| TE only | 0.63 | 0.67 |
| SI + TE | 0.71 | 0.77 |
| SI + Syn + TE (All) | **0.74** | **0.82** |
Using all three subsets together yields the best overall results across both benchmarks and model sizes.
## Intended Use
- Fine-tuning LLMs for Bangla code generation
- Research on low-resource code generation and multilingual programming
- Benchmarking instruction-following capabilities in Bangla
- Studying the effects of different data curation strategies (self-instruct, synthetic, translated) on downstream performance
## Limitations
- All instructions are in Bangla, but the code is in Python. The dataset does not cover other programming languages directly (though models trained on it generalize to C++, Java, JavaScript, and Ruby).
- The SI and Syn subsets use synthetically generated code, which may not fully represent real-world programming patterns.
- The TE subset relies on machine translation, which may introduce translation artifacts despite quality filtering.
- Expert seed prompts (SI) were authored by a limited number of annotators, which may introduce stylistic biases.
## Ethics Statement
We adhere to the ethical guidelines outlined in the LREC 2026 CFP. The dataset was constructed using a combination of expert-authored seeds, LLM-generated content, and machine-translated material, all subjected to rigorous quality filtering. We promote transparency through open-source release and encourage responsible downstream use and community scrutiny.
---
## Citation
If you find our work helpful, please consider citing our paper:
```bibtex
@article{raihan2025tigercoder,
title={Tigercoder: A novel suite of llms for code generation in bangla},
author={Raihan, Nishat and Anastasopoulos, Antonios and Zampieri, Marcos},
journal={arXiv preprint arXiv:2509.09101},
year={2025}
}
```
You may also find our related work useful:
```bibtex
@inproceedings{raihan-zampieri-2025-tigerllm,
title = "{T}iger{LLM} - A Family of {B}angla Large Language Models",
author = "Raihan, Nishat and
Zampieri, Marcos",
booktitle = "Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers)",
month = jul,
year = "2025",
address = "Vienna, Austria",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2025.acl-short.69/",
doi = "10.18653/v1/2025.acl-short.69",
pages = "887--896",
ISBN = "979-8-89176-252-7"
}
```
```bibtex
@inproceedings{raihan-etal-2025-mhumaneval,
title = "m{H}uman{E}val - A Multilingual Benchmark to Evaluate Large Language Models for Code Generation",
author = "Raihan, Nishat and
Anastasopoulos, Antonios and
Zampieri, Marcos",
booktitle = "Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers)",
year = "2025",
}
```
---
许可证:CC BY 4.0
语言:
- 孟加拉语(bn)
- 英语(en)
任务类别:
- 文本生成
标签:
- 代码
- 孟加拉语(bangla)
- 孟加拉语(bengali)
- 代码生成(code-generation)
- 指令微调(instruction-tuning)
- 低资源(low-resource)
- 自然语言处理(nlp)
规模类别:
- 100K < n < 1M
---
<div align="center">
<img src="https://img.shields.io/badge/🐯_孟加拉语--代码--指令-300K-橙黄色?style=for-the-badge" alt="孟加拉语代码指令数据集"/>
<h1 style="color: #2e8b57;">🐯 Bangla-Code-Instruct:面向孟加拉语的大规模代码指令数据集</h1>
<h3>已被LREC 2026接收</h3>
<h4>Nishat Raihan, Antonios Anastasopoulos, Marcos Zampieri</h4>
<h5>乔治·梅森大学,费尔法克斯,弗吉尼亚州,美国</h5>
<br/>
<table>
<tr>
<td>
<a href="https://arxiv.org/abs/2509.09101">
<img src="https://img.shields.io/badge/arXiv-2509.09101-b31b1b?style=for-the-badge&logo=arxiv" alt="arXiv"/>
</a>
</td>
<td>
<a href="https://arxiv.org/pdf/2509.09101">
<img src="https://img.shields.io/badge/Paper-Read_PDF-blue?style=for-the-badge&logo=adobeacrobatreader" alt="Read PDF"/>
</a>
</td>
<td>
<a href="mailto:mraihan2@gmu.edu">
<img src="https://img.shields.io/badge/Email-Contact_Us-green?style=for-the-badge&logo=gmail" alt="Contact Us"/>
</a>
</td>
</tr>
</table>
<table>
<tr>
<td>
<a href="https://huggingface.co/md-nishat-008/TigerCoder-1B">
<img src="https://img.shields.io/badge/🤗_HuggingFace-TigerCoder--1B-yellow?style=for-the-badge" alt="TigerCoder-1B"/>
</a>
</td>
<td>
<a href="https://huggingface.co/md-nishat-008/TigerCoder-9B">
<img src="https://img.shields.io/badge/🤗_HuggingFace-TigerCoder--9B-yellow?style=for-the-badge" alt="TigerCoder-9B"/>
</a>
</td>
<td>
<a href="https://huggingface.co/datasets/md-nishat-008/Bangla-Code-Instruct">
<img src="https://img.shields.io/badge/🤗_HuggingFace-Bangla--Code--Instruct-yellow?style=for-the-badge" alt="孟加拉语代码指令数据集"/>
</a>
</td>
</tr>
</table>
<br/>
**首个面向孟加拉语代码大语言模型(Code LLM)训练的大规模孟加拉语代码指令数据集,包含30万个样本。**
</div>
---
> **⚠️ 注意:** 本数据集将在LREC 2026会议结束后发布,请持续关注!
## 概述
**Bangla-Code-Instruct** 是一套包含30万条孟加拉语指令-代码对的综合指令微调数据集,专为适配大语言模型(LLM)完成孟加拉语代码生成任务设计。作为孟加拉语领域首个同类数据集,它填补了这一全球第五大语言(母语使用者超2.42亿)的高质量编程数据空白。
本数据集被用于训练[TigerCoder](https://huggingface.co/md-nishat-008/TigerCoder-1B)系列模型,相较于此前基线模型,这些模型的Pass@1指标提升了11%至18%,并在孟加拉语代码生成基准测试中超越尺寸高达其27倍的同类模型。
## 数据集构成
Bangla-Code-Instruct 包含三个互补的10万级子集,每个子集采用不同的构建方法以最大化样本多样性与质量:
| 子集 | 规模 | 构建方法 | 种子/来源 | 教师模型 | 指令来源 | 代码来源 |
|:---|:---:|:---|:---|:---|:---|:---|
| **SI(自指令)** | 100,000 | 自指令(Self-Instruct) | 5000条专家种子 | GPT-4o | 半自然生成 | 合成生成 |
| **Syn(合成)** | 100,000 | 合成生成 | 主题集合 | GPT-4o、Claude 3.5 | 合成生成 | 合成生成 |
| **TE(翻译)** | 100,000 | 机器翻译+过滤 | Evol-Instruct | NLLB-200 | 翻译 | 自然(源语言) |
### Bangla-Code-Instruct-SI(自指令子集)
该子集以5000条由编程专家手动撰写的孟加拉语种子指令为起点,通过自指令流水线调用GPT-4o,将种子扩展为10万条半自然指令提示。每条指令对应的Python代码由GPT-4o生成,并通过语法检查(`ast.parse`)与成功执行验证(Python 3.13.0,10秒超时,16GB内存)。此外,通过余弦相似度进行多样性过滤,以避免冗余样本。
### Bangla-Code-Instruct-Syn(合成子集)
该子集包含10万条**完全合成**的孟加拉语指令-Python代码对,由GPT-4o与Claude 3.5-Sonnet生成。为确保指令多样性,新生成的指令会与已有指令进行比对:若与任意已有指令的BERTScore ≥0.7,则该样本会被丢弃。代码同样会进行语法与执行验证(与SI子集流程一致)。该子集通过纯合成生成拓宽了任务多样性,作为人工种子数据的补充。
### Bangla-Code-Instruct-TE(翻译+过滤子集)
最后一个子集通过多机器翻译模型将Evol-Instruct的英文指令翻译为孟加拉语,并基于**CometKiwi-22 QE(得分≥0.85)**与**BERTScore F1(得分≥0.95)**选择最优翻译结果。该子集保留了原始英文源代码,实现了高质量孟加拉语指令与自然编写代码的配对。
## 质量控制
| 质控维度 | SI子集 | Syn子集 | TE子集 |
|:---|:---|:---|:---|
| 代码验证 | 语法检查+执行验证 | 语法检查+执行验证 | 保留源语言代码 |
| 多样性过滤 | 余弦相似度 | BERTScore | BERTScore + Comet QE |
| 执行环境 | Python 3.13.0,10秒超时,16GB RAM | Python 3.13.0,10秒超时,16GB RAM | 无(保留源语言代码) |
## 数据集统计
| 属性 | 数值 |
|:---|:---|
| 总样本数 | 300,000 |
| 子集数量 | 3(SI、Syn、TE) |
| 指令语言 | 孟加拉语 |
| 代码语言 | Python |
| SI子集专家撰写种子数 | 5,000 |
| 教师模型 | GPT-4o、Claude 3.5-Sonnet |
| 翻译子集所用机器翻译模型 | NLLB-200 |
## 消融实验:数据集组合的影响
在TigerCoder模型上的微调实验证明,组合不同子集可产生显著的协同效应:
| 数据集组合 | TigerCoder-1B(MBPP P@1) | TigerCoder-9B(MBPP P@1) |
|:---|:---:|:---:|
| 无(基础TigerLLM) | 0.65 | 0.61 |
| 仅SI子集 | 0.66 | 0.66 |
| 仅Syn子集 | 0.63 | 0.63 |
| 仅TE子集 | 0.63 | 0.67 |
| SI + TE子集 | 0.71 | 0.77 |
| SI + Syn + TE子集(全量) | **0.74** | **0.82** |
同时使用全部三个子集可在两种模型尺寸与所有基准测试中获得最优综合性能。
## 预期用途
- 针对孟加拉语代码生成任务的大语言模型微调
- 低资源代码生成与多语言编程相关研究
- 孟加拉语指令跟随能力的基准测试
- 研究不同数据整理策略(自指令、合成、翻译)对下游任务性能的影响
## 局限性
- 所有指令均采用孟加拉语,但代码为Python语言。本数据集未直接覆盖其他编程语言(尽管基于本数据集训练的模型可泛化至C++、Java、JavaScript与Ruby)。
- SI与Syn子集采用合成生成的代码,可能无法完全反映真实编程场景的模式。
- TE子集依赖机器翻译,尽管经过质量过滤,仍可能引入翻译瑕疵。
- SI子集的专家种子指令由少量标注人员撰写,可能引入风格偏差。
## 伦理声明
我们遵循LREC 2026征稿启事(CFP)中规定的伦理准则。本数据集由专家撰写的种子指令、大语言模型生成内容与机器翻译材料组合构建,并经过严格的质量过滤。我们通过开源发布保障透明度,并鼓励负责任的下游使用与社区监督。
---
## 引用
如果您认为本工作对您有所帮助,请引用我们的论文:
bibtex
@article{raihan2025tigercoder,
title={Tigercoder: A novel suite of llms for code generation in bangla},
author={Raihan, Nishat and Anastasopoulos, Antonios and Zampieri, Marcos},
journal={arXiv preprint arXiv:2509.09101},
year={2025}
}
您也可以参考我们的相关研究:
bibtex
@inproceedings{raihan-zampieri-2025-tigerllm,
title = "{T}iger{LLM} - A Family of {B}angla Large Language Models",
author = "Raihan, Nishat and
Zampieri, Marcos",
booktitle = "Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers)",
month = jul,
year = 2025,
address = "Vienna, Austria",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2025.acl-short.69/",
doi = "10.18653/v1/2025.acl-short.69",
pages = "887--896",
ISBN = "979-8-89176-252-7"
}
bibtex
@inproceedings{raihan-etal-2025-mhumaneval,
title = "m{H}uman{E}val - A Multilingual Benchmark to Evaluate Large Language Models for Code Generation",
author = "Raihan, Nishat and
Anastasopoulos, Antonios and
Zampieri, Marcos",
booktitle = "Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers)",
year = 2025,
}
提供机构:
md-nishat-008
搜集汇总
数据集介绍
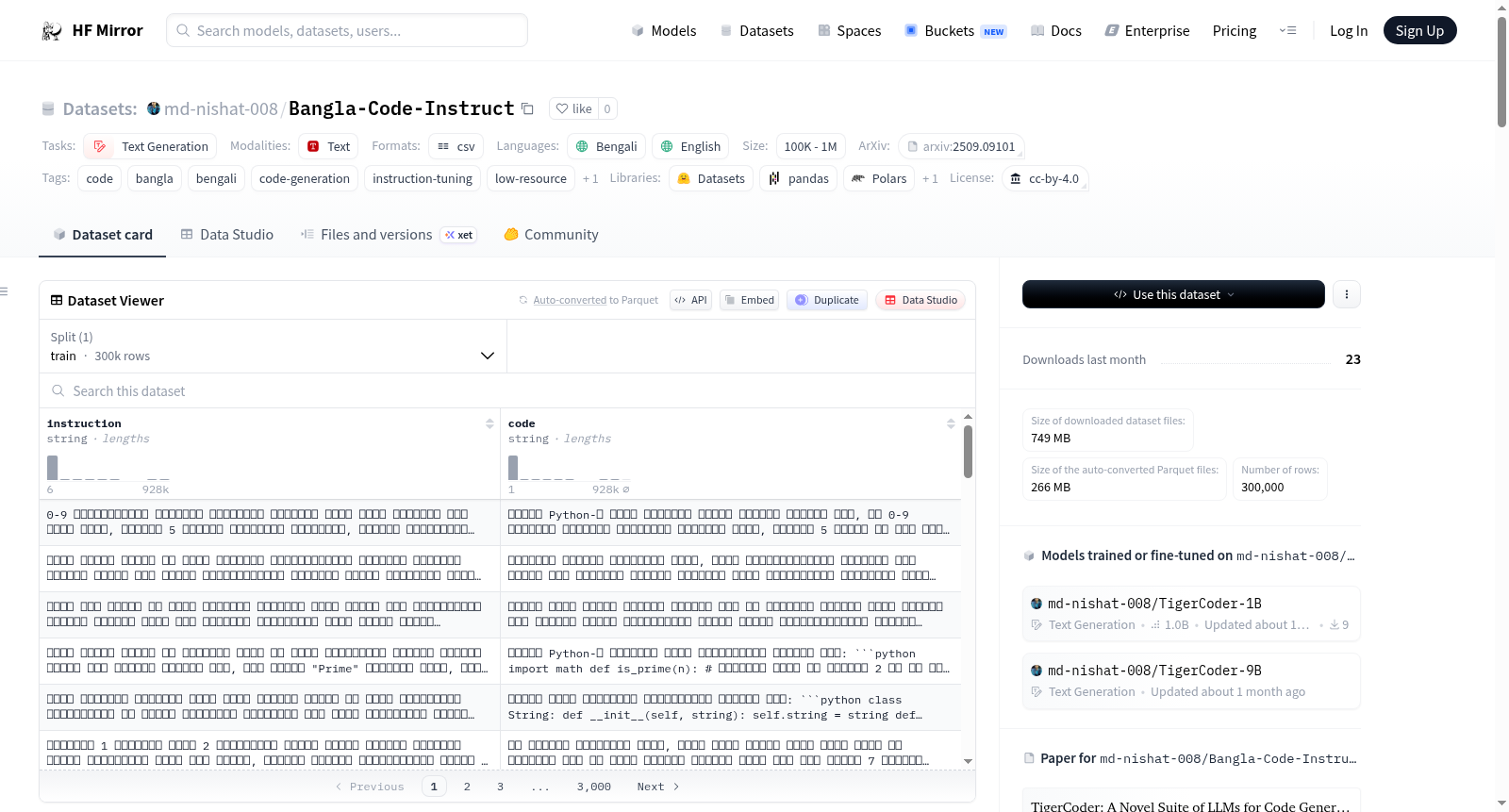
构建方式
在低资源语言编程数据稀缺的背景下,Bangla-Code-Instruct数据集通过三种互补方法构建而成。首先,基于专家手工撰写的五千条孟加拉语种子提示,采用自指导流程利用GPT-4o扩展生成了十万条半自然指令及其对应代码,并通过语法解析与执行验证确保功能性。其次,借助GPT-4o与Claude 3.5模型完全合成十万对指令与代码,利用BERTScore进行多样性过滤以避免重复。最后,通过机器翻译将Evol-Instruct的英语指令转化为孟加拉语,保留原始自然代码,并依据CometKiwi-22与BERTScore指标筛选高质量译文,共同构成三十万对高质量数据。
特点
作为首个大规模孟加拉语代码指令数据集,该数据集显著填补了全球第五大语言编程资源的空白。其核心特征在于融合了自指导、全合成与翻译过滤三种数据构建策略,确保了指令的多样性与代码的可靠性。数据集不仅包含专家引导的半自然内容,还涵盖纯粹合成与翻译保留的天然代码,这种多层次结构为模型训练提供了丰富的任务类型与语言表达。同时,严格的语法检查、执行验证及多样性过滤机制保障了数据质量,使其能够有效支持孟加拉语代码生成模型的性能提升。
使用方法
该数据集主要应用于孟加拉语代码生成大语言模型的指令微调,为低资源多语言编程研究提供关键数据支撑。使用者可通过加载HuggingFace平台上的数据集,直接将其用于模型训练流程,以提升模型在孟加拉语指令下的代码生成能力。研究实践表明,联合使用全部三个子集能产生最佳性能增益,例如在TigerCoder模型上实现了显著的通过率提升。此外,数据集也可作为评估模型指令遵循能力的基准,助力探索不同数据策展策略对下游任务的影响。
背景与挑战
背景概述
在自然语言处理领域,低资源语言的代码生成任务长期面临数据稀缺的困境。Bangla-Code-Instruct数据集由乔治梅森大学的Nishat Raihan、Antonios Anastasopoulos和Marcos Zampieri研究团队于2025年构建,旨在解决孟加拉语这一全球第五大母语在编程指令数据方面的空白。该数据集包含30万条孟加拉语指令与Python代码的配对,通过自指令、合成生成与翻译过滤三种方法构建,为训练面向孟加拉语的代码大语言模型提供了首个大规模资源。其相关研究成果已被LREC 2026接收,并支撑了TigerCoder模型系列的开发,显著提升了孟加拉语代码生成的性能,对推动多语言编程辅助技术的发展具有重要影响。
当前挑战
该数据集致力于应对孟加拉语代码生成这一低资源领域问题的挑战,核心在于克服高质量双语编程数据的匮乏,以及模型在理解自然语言指令并生成准确、可执行代码方面的能力局限。在构建过程中,研究团队面临多重挑战:首先,确保合成代码的语义正确性与执行可靠性,需对每条生成代码进行语法解析与运行时验证;其次,维持指令的多样性与新颖性,需采用余弦相似度与BERTScore等指标进行冗余过滤;再者,机器翻译可能引入语义偏差,需通过CometKiwi-22与BERTScore双重质量评估以筛选优质译文;此外,专家种子提示的有限性可能带来风格偏见,需通过多种数据构建策略互补以平衡数据分布。
常用场景
经典使用场景
在低资源语言编程领域,数据稀缺是制约模型性能的关键瓶颈。Bangla-Code-Instruct作为首个大规模孟加拉语代码指令数据集,其经典应用场景在于为孟加拉语代码生成任务提供高质量的指令微调数据。该数据集通过融合自指令生成、合成生成与翻译过滤三种策略,构建了三十万条孟加拉语指令-代码对,专门用于训练和优化面向孟加拉语的代码大语言模型,显著提升了模型在理解孟加拉语编程需求并生成对应Python代码的能力。
实际应用
在实际应用层面,基于Bangla-Code-Instruct训练的模型,如TigerCoder系列,能够直接赋能孟加拉语开发者社区。这些模型可集成到集成开发环境或代码辅助平台中,使开发者能够使用母语描述编程意图,自动生成或补全Python代码片段,极大降低了编程门槛并提升了开发效率。此外,该数据集也为教育科技领域提供了资源,可用于开发面向孟加拉语初学者的交互式编程教学工具,促进计算思维在更广泛人群中的普及。
衍生相关工作
该数据集直接催生了一系列重要的衍生研究工作。最突出的成果是训练出了TigerCoder模型家族,这些模型在孟加拉语代码生成基准测试中超越了规模大数十倍的基线模型。同时,围绕该数据集构建的评估基准mHumanEval,为多语言代码生成模型的性能评估提供了标准化工具。这些工作共同构成了一个从数据创建、模型训练到系统评估的完整研究链条,深化了学术界对多语言指令微调、低资源代码生成以及数据合成策略影响的理解。
以上内容由遇见数据集搜集并总结生成


