GIFT-CTX
收藏Hugging Face2026-01-14 更新2026-01-16 收录
下载链接:
https://huggingface.co/datasets/Salesforce/GIFT-CTX
下载链接
链接失效反馈官方服务:
资源简介:
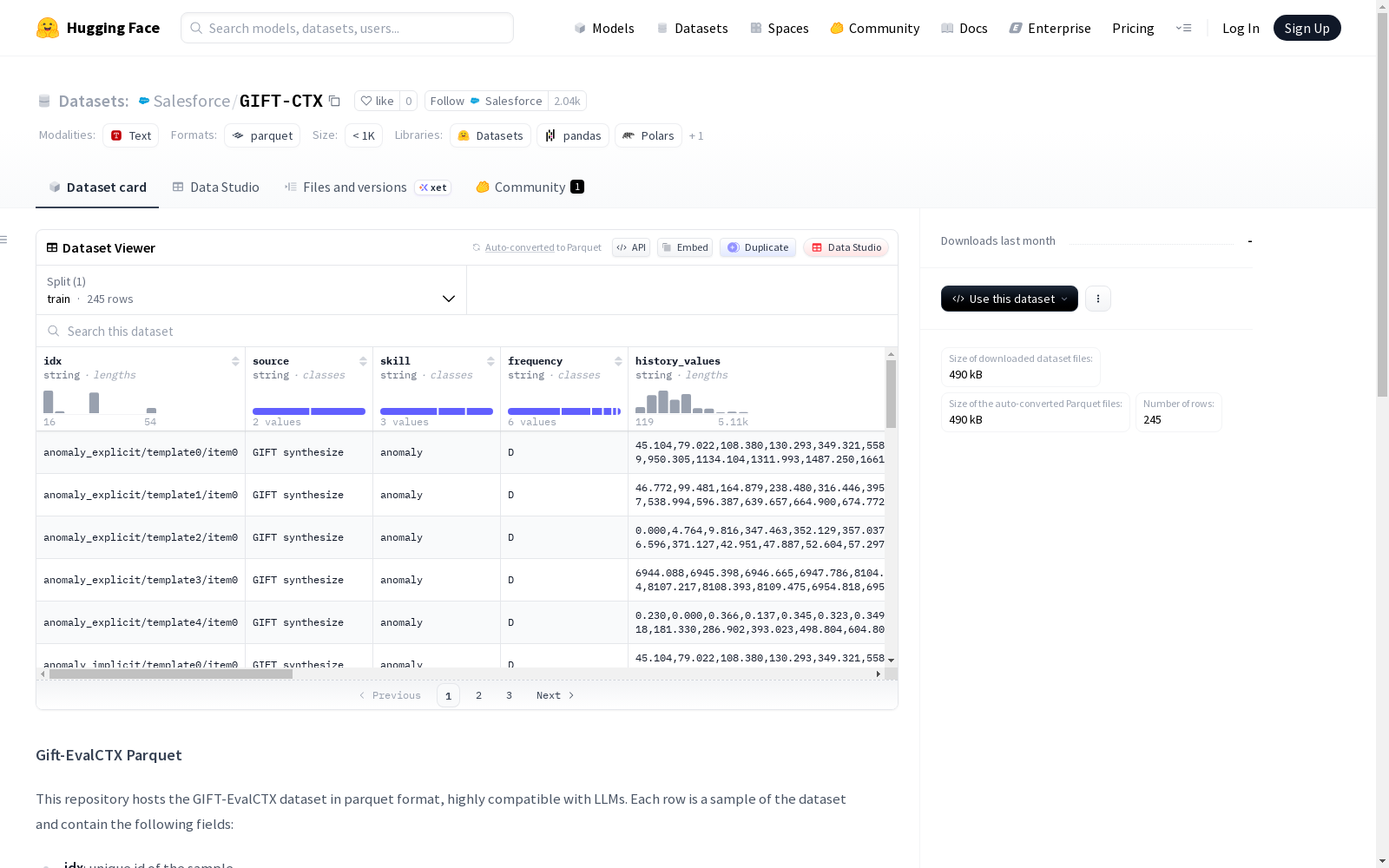
该数据集名为Gift-EvalCTX Parquet,采用parquet格式存储,高度兼容大型语言模型(LLMs)。每个样本包含多个字段,包括唯一标识符idx、数据来源source、上下文类型skill、样本频率frequency、历史值history_values、历史时间范围history_start和history_end、未来预测值future_values、未来时间范围future_start和future_end、分隔符entry_sep、感兴趣区域roi、预测长度pred_length、系统提示system_prompt、用户指令user_instruct、上下文信息context_info以及完整提示prompt。所有字段均为字符串格式,需转换为适当的数据类型(如浮点数数组或日期时间)。
This dataset is named Gift-EvalCTX Parquet, which is stored in Parquet format and demonstrates high compatibility with Large Language Models (LLMs). Each sample includes multiple fields: the unique identifier idx, data source source, context type skill, sample frequency frequency, historical values history_values, historical start time history_start and historical end time history_end, future prediction values future_values, future start time future_start and future end time future_end, delimiter entry_sep, region of interest (ROI), prediction length pred_length, system prompt system_prompt, user instruction user_instruct, context information context_info, and complete prompt prompt. All fields are initially stored in string format and require conversion to appropriate data types, such as floating-point arrays or datetime objects.
提供机构:
Salesforce
创建时间:
2026-01-14
原始信息汇总
GIFT-CTX 数据集概述
数据集基本信息
- 数据集名称: GIFT-CTX
- 发布者: Salesforce
- 数据格式: Parquet
- 访问地址: https://huggingface.co/datasets/Salesforce/GIFT-CTX
- 用途说明: 仅限研究目的
数据内容与结构
- 数据文件:
gift_ctx/train.parquet - 数据分割: 训练集(train)
- 样本字段:
idx: 样本唯一标识符source: 数据来源skill: 上下文类型frequency: 样本频率history_values: 历史值字符串history_start: 历史起始时间戳history_end: 历史结束时间戳future_values: 预测未来值字符串future_start: 未来起始时间戳future_end: 未来结束时间戳entry_sep: 用于将字符串拆分为浮点数数组的分隔符roi: 感兴趣区域,指示受上下文影响并用于评估的时间戳索引pred_length: 需预测的时间戳数量system_prompt: 默认系统提示user_instruct: 预测查询指令context_info: 当前样本的上下文信息prompt: 用于查询大语言模型的完整提示
数据特性说明
- 所有字段均为字符串类型,需根据需求转换为适当格式(如浮点数数组或日期时间)。
- 数据集设计与大语言模型高度兼容。
使用示例
python from datasets import load_dataset
ds = load_dataset( "Salesforce/GiftEvalCTX", "gift_ctx", split="train" ) print(len(ds)) print(ds[0].keys())
搜集汇总
数据集介绍
构建方式
在时间序列预测领域,GIFT-CTX数据集的构建体现了对上下文信息整合的深入考量。该数据集通过精心设计的数据采集流程,从多元时间序列中提取历史与未来区段,每个样本均包含历史值序列、未来预测值序列及相应的时间戳信息。构建过程中,数据被转换为高度兼容大型语言模型的Parquet格式,确保每行样本均具备完整的结构化字段,如历史起止时间、未来区间、区域兴趣标识等,便于后续的模型训练与评估。
特点
GIFT-CTX数据集的特点在于其专注于上下文感知的时间序列预测任务,样本中不仅包含标准的历史与未来数值序列,还融入了技能类型、频率信息以及上下文描述等元数据。数据集通过统一的字符串格式存储各类数值与时间戳,并辅以分隔符标识,支持灵活的数据解析与转换。此外,每个样本均配备了系统提示、用户指令及完整提示模板,可直接用于基于大型语言模型的预测任务,体现了其在评估模型上下文理解能力方面的独特价值。
使用方法
使用GIFT-CTX数据集时,研究人员可通过Hugging Face的datasets库便捷加载,指定配置名称与分割集即可获取结构化数据。加载后,需根据字段说明将字符串格式的历史值、未来值及时间戳转换为浮点数数组或日期时间对象,以适配模型输入要求。数据集中提供的提示模板可直接用于生成查询,结合区域兴趣标识与预测长度,用户能够针对性地评估模型在特定上下文条件下的预测性能,推动时间序列分析与语言模型交叉领域的研究进展。
背景与挑战
背景概述
GIFT-CTX数据集由Salesforce研究团队于近年构建,旨在推动大型语言模型在时间序列预测领域的应用。该数据集聚焦于上下文感知的预测任务,核心研究问题是如何有效利用历史时间序列数据中的上下文信息,提升模型对未来趋势的精准预测能力。通过整合历史值、未来值、时间戳及上下文提示等结构化字段,GIFT-CTX为评估模型在复杂时序场景中的泛化与推理能力提供了标准化基准,对促进人工智能在金融、气候、物联网等领域的预测分析具有重要影响力。
当前挑战
在领域问题层面,GIFT-CTX致力于解决时间序列预测中上下文整合与长期依赖建模的挑战,要求模型不仅能捕捉历史数据的动态模式,还需解析上下文信息对未来趋势的隐含影响。构建过程中,数据集面临多源异构时序数据的对齐与清洗难题,需确保历史与未来时间窗口的一致性;同时,设计兼顾可解释性与计算效率的提示结构,以适配大型语言模型的输入格式,亦是一项关键挑战。
常用场景
经典使用场景
在时间序列预测领域,GIFT-CTX数据集为评估大型语言模型在上下文感知预测任务中的性能提供了基准。该数据集通过整合历史时间序列数据、未来预测目标及丰富的上下文信息,模拟了现实世界中动态变化的预测场景。研究者利用其结构化字段,如历史值、未来值及区域兴趣索引,能够系统地测试模型在复杂时间依赖关系中的泛化能力与鲁棒性,从而推动时序预测方法的前沿探索。
解决学术问题
GIFT-CTX数据集旨在解决时间序列预测中上下文信息整合不足的学术挑战。传统预测模型往往忽略外部环境或历史模式中的上下文线索,导致在动态变化场景中表现受限。该数据集通过提供标注的上下文信息、时间戳及区域兴趣索引,使研究者能够深入探究如何有效融合多源上下文以提升预测精度。这不仅促进了上下文感知预测理论的发展,还为评估模型在真实世界复杂时序中的适应性提供了标准化工具。
衍生相关工作
围绕GIFT-CTX数据集,已衍生出多项经典研究工作,主要集中在上下文增强的时间序列预测模型开发上。例如,研究者基于其提供的上下文信息字段,提出了融合注意力机制与序列建模的混合架构,以提升长期依赖捕捉能力。此外,该数据集还激发了针对大型语言模型在时序任务中的微调策略探索,推动了如Prompt-based预测、多任务学习等方法的创新,为时序分析领域注入了新的活力。
以上内容由遇见数据集搜集并总结生成


